

Объяснение состязательных примеров в машинном обучении
16 мая 2022 г.Как обмануть модель с 27 миллионами параметров с помощью Python
Как вы думаете, невозможно обмануть систему зрения беспилотного автомобиля Tesla?
Или что модели машинного обучения, используемые в программном обеспечении для обнаружения вредоносных программ, слишком хороши, чтобы хакеры могли их обойти?
Или что системы распознавания лиц в аэропортах пуленепробиваемы?
Как и любой из нас, энтузиастов машинного обучения, вы можете попасть в ловушку, думая, что используемые глубинные модели идеальны.
Ну, вы НЕПРАВЫ.
Есть простые способы создания состязательных примеров, которые могут обмануть любую модель глубокого обучения и создать проблемы безопасности. В этом посте мы рассмотрим следующее:
- Что такое состязательные примеры?
- Как вы генерируете состязательные примеры?
- Практический пример: давайте сломаем Inception 3
- Как защитить свои модели от враждебных примеров
Весь исходный код, показанный в этой статье, находится в **этом репозитории Github**👇🏽

Давайте начнем!
1. Что такое состязательные примеры? 😈
За последние 10 лет модели глубокого обучения покинули академический детский сад, стали большими мальчиками и изменили многие отрасли. Особенно это касается моделей компьютерного зрения. Когда AlexNet попал в чарты в 2012 году, эра глубокого обучения официально началась.
В настоящее время модели компьютерного зрения так же хороши или лучше, чем человеческое зрение. Вы можете найти их во множестве мест, включая…
- самоуправляемые автомобили
- распознавание лица
- медицинский диагноз
- системы наблюдения
- обнаружение вредоносных программ
До недавнего времени исследователи обучали и тестировали модели машинного обучения в лабораторной среде, например, на соревнованиях по машинному обучению и научных работах. В настоящее время при развертывании в реальных сценариях уязвимости безопасности, возникающие из-за ошибок модели, стали серьезной проблемой.
Представьте на мгновение, что ультрасовременная система машинного зрения с глубоким обучением вашего беспилотного автомобиля не смогла распознать [этот знак остановки] (https://spectrum.ieee.org/cars). -что-думает/транспорт/сенсоры/незначительные-модификации-уличных-знаков-могут-обмануть-алгоритмы-машинного обучения) в качестве знака остановки.
![Надежные атаки физического мира на визуальную классификацию глубокого обучения Эйкхольта и др.] (https://cdn.hackernoon.com/images/DUgalx4alqOf4QlthE3dDI1x7Wq2-7hc3m1n.jpeg)
Ну, это точно что произошло. Это изображение знака "стоп" является состязательным примером. Думайте об этом как об оптической иллюзии для модели.
Давайте посмотрим на другой пример. Ниже у вас есть два изображения собаки, которые неразличимы для нас, людей.

Изображение слева — оригинальная фотография щенка, сделанная [Доминикой Роузклей] (https://www.pexels.com/photo/soft-focus-photo-of-dachshund-895259/). Тот, что справа, является небольшой модификацией первого, который я создал, добавив вектор шума в центральное изображение.
Inception v3 правильно классифицирует исходное изображение как породу собак (рыжая кость). Однако эта же модель с большой уверенностью думает, что созданное мной измененное изображение — это бумажное полотенце.
Другими словами, я создал состязательный пример. И вы тоже, так как это пример, над которым мы будем работать позже в разделе 3.
Противоположный пример для модели компьютерного зрения — входное изображение с небольшими отклонениями, незаметными для человеческого глаза, что приводит к неверному прогнозу модели.
Не думайте, что эти 2 примера — редкие крайние примеры, которые можно найти, потратив кучу времени и вычислительных ресурсов. Есть простые способы генерировать враждебные примеры, и это открывает дверь к серьезным уязвимостям систем машинного обучения в продакшене.
Давайте посмотрим, как можно создать состязательный пример и обмануть современную модель классификации изображений.
2. Как генерировать состязательные примеры?
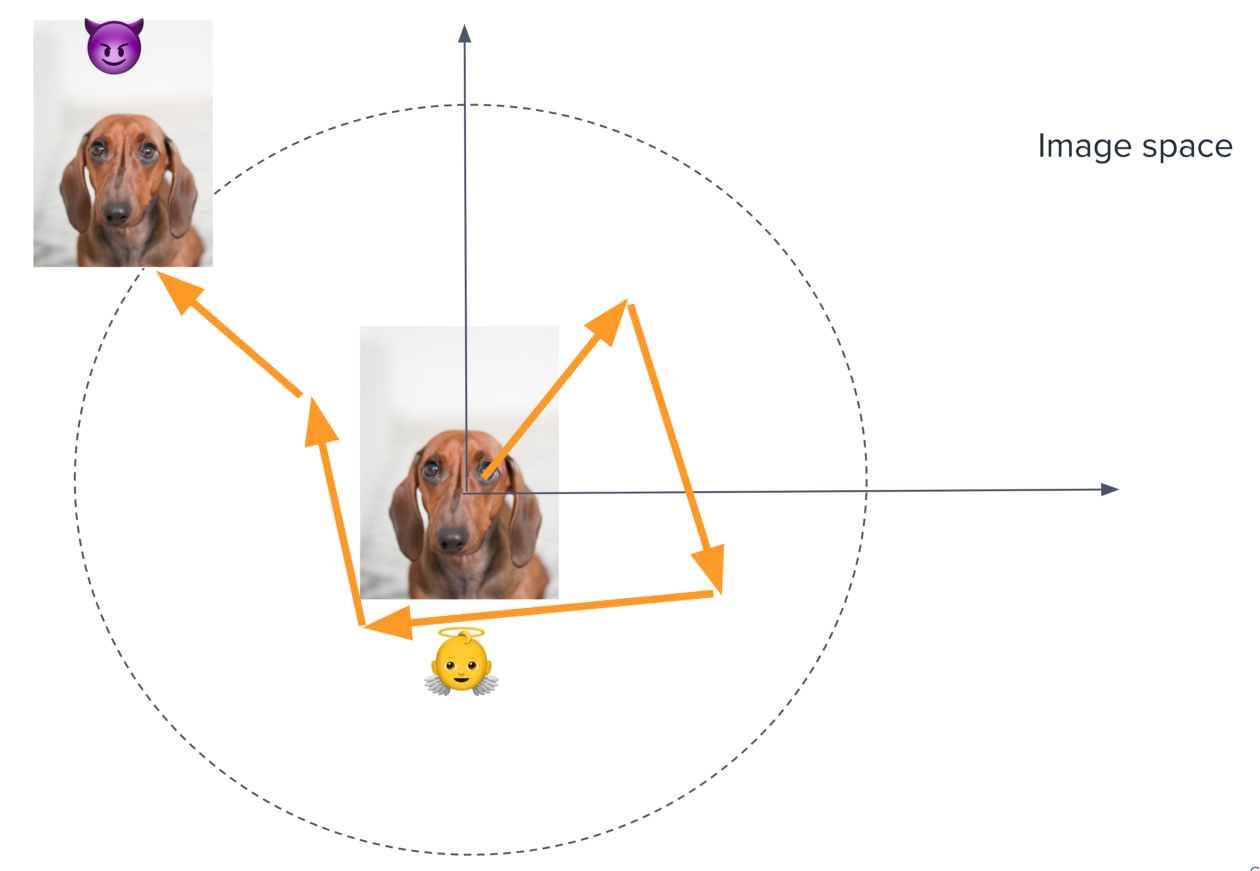
Состязательные примеры 😈 генерируются путем взятия чистого изображения 👼, которое модель правильно классифицирует, и обнаружения небольшого возмущения, из-за которого новое изображение неправильно классифицируется моделью ML.
Сценарий белого ящика
Предположим, у вас есть полная информация о модели, которую вы хотите обмануть. В этом случае можно вычислить функцию потерь модели
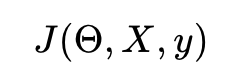
куда
- X входное изображение
- y — выходной класс,
- и θ — вектор параметров сети.
Эта функция потерь обычно представляет собой отрицательную логарифмическую вероятность для методов классификации.
Ваша цель — найти новое изображение X’, близкое к исходному X и дающее большое изменение значения функции потерь.
Представьте, что вы находитесь внутри пространства всех возможных входных изображений, сидя поверх исходного изображения X. Это пространство имеет размеры ширина х высота х каналы, так что извините, если вы плохо это представляете 😜.
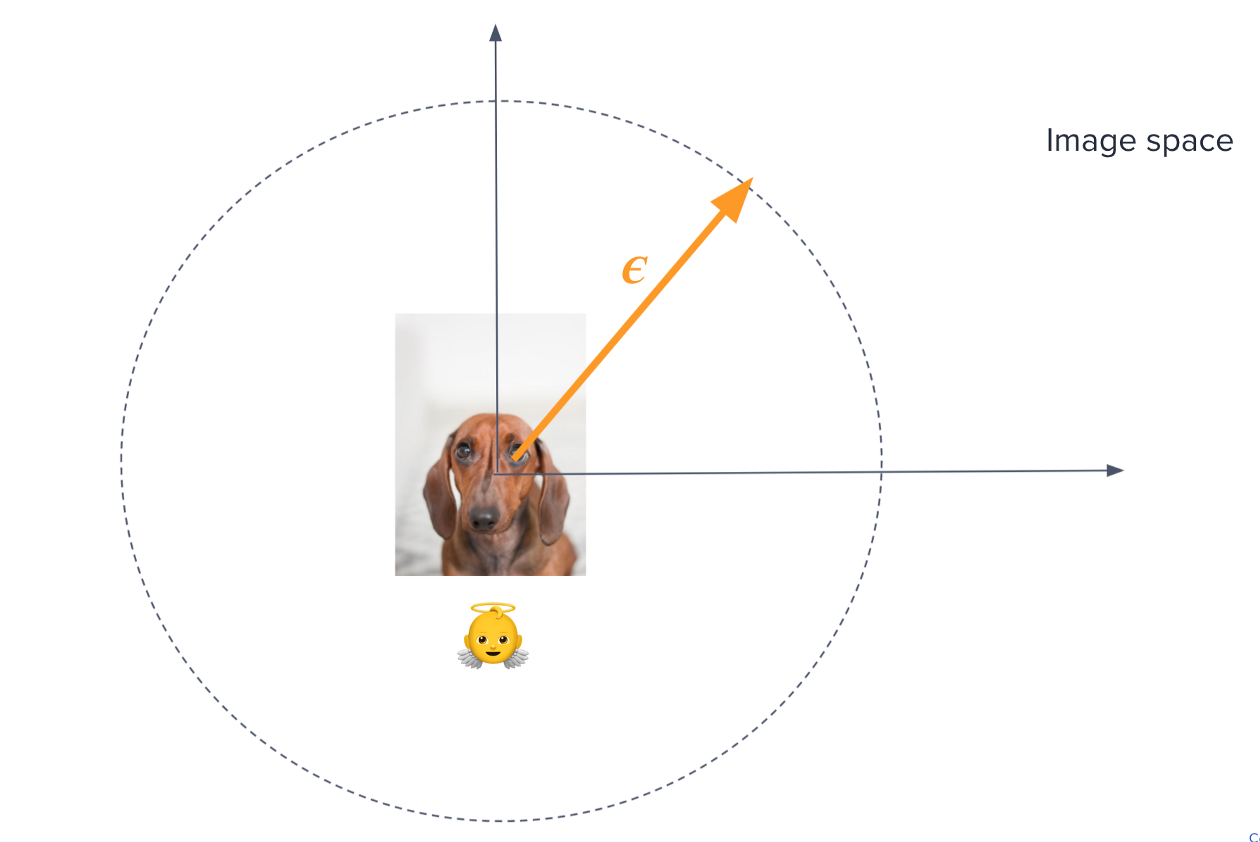
Чтобы найти состязательный пример, вам нужно немного пройтись в каком-то направлении в этом пространстве, пока вы не найдете другое изображение X’ с заметно отличающимся проигрышем. Вы хотите выбрать направление, которое максимизирует изменение функции потерь J для фиксированного малого шага эпсилон.
Теперь, если вы немного освежите свой курс математических вычислений, направление в пространстве X, где функция потерь изменяется больше всего, будет в точности градиентом J по отношению к X.
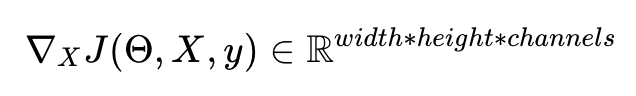
Градиент функции по одной из ее переменных — это именно направление максимального изменения. И, кстати, именно по этой причине люди тренируют нейронные сети, используя стохастический градиентный спуск, а не стохастический спуск в случайном направлении.
Метод быстрого знака градиента
Простой способ формализовать эту интуицию состоит в следующем:
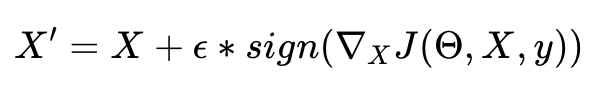
Мы берем только знак градиента и масштабируем его, используя небольшой параметр эпсилон, чтобы гарантировать, что искажение между X и X будет достаточно малым, чтобы быть незаметным для человеческого глаза. Этот метод называется методом быстрого знака градиента.
Атака черного ящика
В большинстве случаев весьма вероятно, что у вас не будет полной информации о модели. Следовательно, предыдущий метод бесполезен, поскольку вы не можете вычислить градиент.
Тем не менее, существует замечательное свойство, называемое «переносимость» враждебных примеров, которое злоумышленники могут использовать для взлома модели, даже если они не знают ее внутреннюю архитектуру и параметры.
Исследователи неоднократно отмечали, что состязательные примеры довольно хорошо переносятся между моделями, а это означает, что они могут быть разработаны для целевой модели А, но в конечном итоге эффективны против любой другой модели, обученной на аналогичном наборе данных.
Состязательные примеры могут быть сгенерированы следующим образом:
- Запросите целевую модель с входными данными X_i для i = 1 … n и сохраните выходные данные y_i.
- Используйте обучающие данные (X_i, y_i) для построения другой модели, называемой замещающей моделью.
- Используйте алгоритм белого ящика, такой как знак быстрого градиента, для создания состязательных примеров для замещающей модели. Многие из них будут успешно переноситься и также станут состязательными примерами для целевой модели.
Успешное применение этой стратегии против коммерческой модели машинного обучения представлено в этой статье Computer Vision Foundation.
3. Практический пример: давайте сломаем Inception 3
Давайте запачкаем руки и реализуем несколько атак, используя Python и замечательную библиотеку PyTorch. Всегда полезно знать, как думает злоумышленник.
Полный код можно найти в этом репозитории Github.
Нашей целевой моделью будет Inception V3, мощная модель классификации изображений, разработанная Google, которая имеет около 27 миллионов параметров и была обучена примерно на 14 миллионах изображений, принадлежащих к 20 тысячам категорий.
```питон
Загружаем предварительно обученную модель из концентратора PyTorch
https://pytorch.org/hub/pytorch_vision_inception_v3/
из torchvision.models импортировать inception_v3
модель = inception_v3 (предварительно обученный = True)
модель.eval()
Подсчет параметров модели: 27 161 264
n_params = sum(p.numel() для p в model.parameters())
print(f'{n_params:,} параметры')
Мы загружаем список классов, на которых обучалась модель, и создаем вспомогательный словарь, который сопоставляет идентификаторы классов с метками.
```питон
Загрузите txt-файл со списком классов ImageNet, на которых обучалась модель
"!" magic для запуска команд оболочки из ноутбука Jupyter
!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
id2label сопоставляет идентификаторы классов с их удобочитаемыми именами: например. id2label[1] = 'золотая рыбка'
с open("imagenet_classes.txt", "r") как f:
Categories = [s.strip() для s в f.readlines()]
ID2label = {}
для idx, категория в перечислении (категории):
id2label[idx] = категория
Давайте возьмем изображение невинной рыжей собаки в качестве исходного изображения, которое мы тщательно модифицируем, чтобы построить состязательные примеры:
```питон
запросы на импорт
импорт io
из изображения импорта PIL
url = 'https://previews.123rf.com/images/meinzahn/meinzahn1211/meinzahn121100339/16350068-милый-тигр-кошка-изолированный-на-белом.jpg'
ответ = запросы.get(url)
img = Image.open(io.BytesIO(response.content))
изображение

Inception V3 ожидает изображения с размерами 299 x 299 и нормализованными диапазонами пикселей от -1 до 1.
Давайте предварительно обработаем наше красивое изображение собаки:
```питон
импортный факел
от факела импорт Tensor
из импортных преобразований torchvision
def preprocess(img) -> Тензор:
Модель Inception V3 от pytorch ожидает входные изображения со значениями пикселей от -1 до 1.
и размеры 299 х 299
среднее = [0,485, 0,456, 0,406]
станд = [0,229, 0,224, 0,225]
preprocess_fn = transforms.Compose([
преобразовывает.Resize((299,299)),
преобразовывает.ToTensor(),
transforms.Normalize (среднее, станд.)
image_tensor = preprocess_fn (изображение)
добавить размер пакета: C x H x W ==> B x C x H x W
image_tensor = image_tensor.unsqueeze (0)
вернуть image_tensor
х = предварительная обработка (изображение)
и убедитесь, что модель правильно классифицирует это изображение.
```питон
из easydict импортировать EasyDict
импортировать torch.nn.functional как F
def get_predictions(img: Tensor) -> EasyDict:
вывод = модель.вперед(изображение)
class_idx = torch.max(output.data, 1)[1][0].item()
метка = id2label[class_idx]
output_probs = F.softmax (выход, тусклый = 1)
доверие = раунд (torch.max (output_probs.data, 1) [0] [0]. item(), 4)
вернуть EasyDict(
идентификатор = class_idx,
метка = метка,
уверенность = уверенность,
get_predictions(x) # {'id': 168, 'label': 'redbone', 'confidence': 0,8861}
Хорошо. Модель работает, как и ожидалось, и собака redbone классифицируется как собака redbone :-).
Давайте перейдем к забавной части и создадим состязательные примеры, используя метод Fast Gradient Sign.
```питон
от ввода import Tuple
из torch.autograd импортировать переменную
def fast_gradient_sign(x: Tensor, eps: float) -> Tuple[Tensor, Tensor]:
преобразовать тензор в переменную, потому что нам нужно будет вычислить градиенты
функции потерь по отношению к пикселям изображения
img_variable = переменная (x, required_grad = True)
прямой проход исходного изображения
вывод = model.forward(img_variable)
получить предсказанный класс
y_true = torch.max(output.data, 1)[1][0].item()
target = Variable (torch.LongTensor ([y_true]), require_grad = False)
обратный проход для вычисления градиентов
loss_fn = факел.nn.CrossEntropyLoss()
потеря = потеря_fn (выход, цель)
это рассчитает градиент каждой переменной (с require_grad=True)
к которому вы позже сможете получить доступ с помощью "var.grad.data"
PyTorch выполняет тяжелую работу, вычисляя градиент кросс-энтропии
по отношению к пикселям входного изображения.
loss.backward(retain_graph=Истина)
знак градиента функции потерь (относительно входа X)
x_grad = torch.sign (img_variable.grad.data)
формула быстрого знака градиента
x_adversarial = img_variable.data + eps * x_grad
вернуть x_adversarial, x_grad
оставьте эпсилон маленьким, чтобы генерировать небольшие изменения в исходном изображении
эпсилон = 0,02
x_adv, grad = fast_gradient_sign(x, эпсилон)
Я создал вспомогательную функцию для визуализации как исходного, так и противоборствующего изображения. Полную реализацию можно увидеть в этом репозитории GitHub.
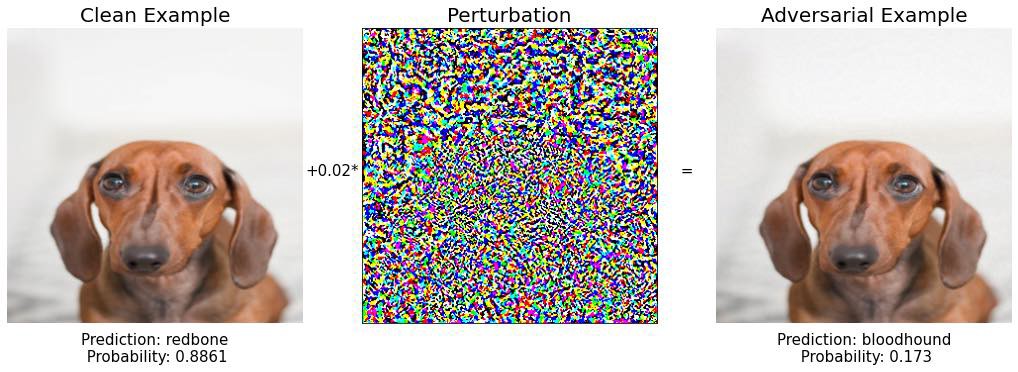
Хорошо. Интересно, как изменилось предсказание модели для нового изображения, которое практически неотличимо от исходного. Новое предсказание — «ищейка», еще одна порода собак с очень похожим цветом кожи и большими ушами. Поскольку рассматриваемый щенок может быть смешанной породы, ошибка модели кажется небольшой, поэтому мы хотим работать дальше, чтобы действительно сломать эту модель.
Одна из возможностей состоит в том, чтобы поиграть с различными значениями эпсилон и попытаться найти то, которое явно дает неверный прогноз. Давайте попробуем это.
```питон
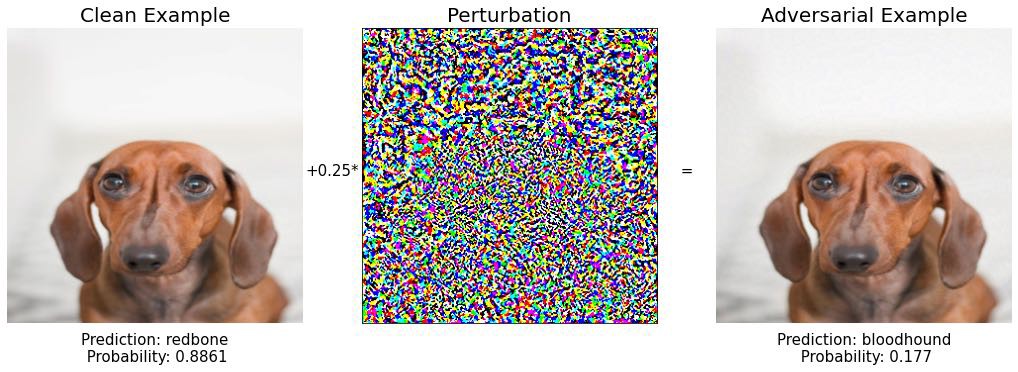
эпсилон = [0,02, 0,2, 0,9]
для эпсилон в эпсилонах:
x_adv, grad = fast_gradient_sign(x, эпсилон)
печать('эпсилон: ', эпсилон)
визуализировать (x, x_adv, град, эпсилон)

По мере увеличения эпсилон изменение изображения становится видимым. Однако в модельных прогнозах остаются все же другие породы собак: ищейка и бассет. Нам нужно быть умнее, чтобы сломать модель.
Вспомните интуицию, лежащую в основе метода быстрого знака градиента, т.е. представьте себя внутри пространства всех возможных изображений (размером 299 x 299 x 3), прямо там, где находится исходное изображение X. Градиент функции потерь указывает вам направление, в котором вам нужно двигаться, чтобы увеличить его значение и сделать модель менее уверенной в правильном прогнозе. Размер шага равен эпсилон. Вы шагаете и проверяете, не сидите ли вы сейчас на состязательном примере.
Расширением этого было бы выполнение множества более мелких шагов вместо одного. После каждого шага вы переоцениваете градиент и выбираете новое направление, в котором собираетесь двигаться.
Этот метод называется методом итеративного быстрого градиента. Какое оригинальное имя!
Более формально:
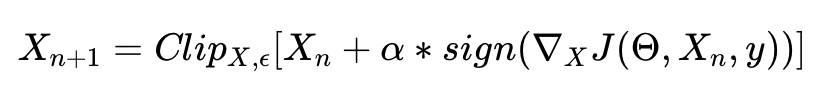
Где X0 = X, а Clip X,ϵ обозначает отсечение входных данных в диапазоне [X−ϵ, X+ϵ].
Реализация в PyTorch выглядит следующим образом:
```питон
def iterative_fast_gradient_sign (x_: Tensor, epsilon: float, n_steps: int, alpha: float):
скопировать, чтобы избежать изменения исходного тензора
х = х_.клон().отсоединить()
для шага в диапазоне (n_steps):
один шаг с использованием базового FGSM
x_adv, grad = fast_gradient_sign(x, альфа)
полное возмущение
total_grad = x_adv - x_
заставить общее возмущение быть меньше эпсилон в
абсолютная величина
total_grad = torch.clamp(total_grad, -epsilon, epsilon)
добавить полное возмущение к исходному изображению
x_adv = x_ + total_grad
х = х_adv
вернуть x_adv, total_grad
Теперь давайте попробуем снова создать хороший пример состязательности, начав с нашего невинного щенка.
Шаг 1: снова ищейка
Шаг 2: снова бигль
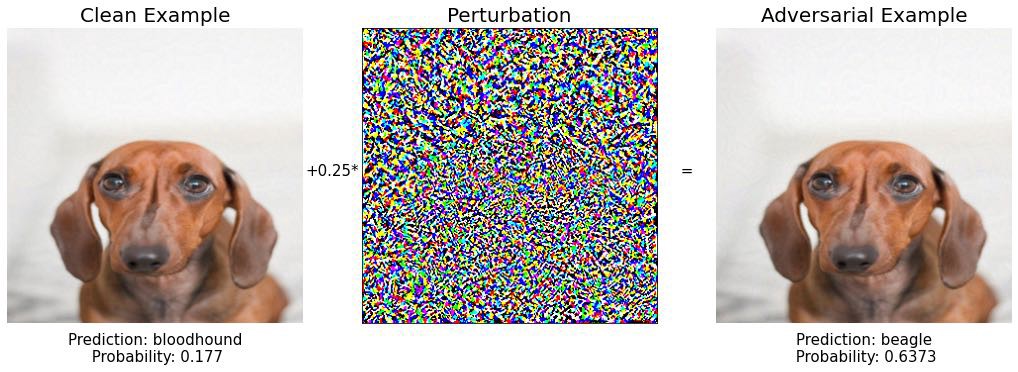
Шаг 3: мышеловка? Интересный. Однако уверенность модели в этом прогнозе составляет всего 16%.
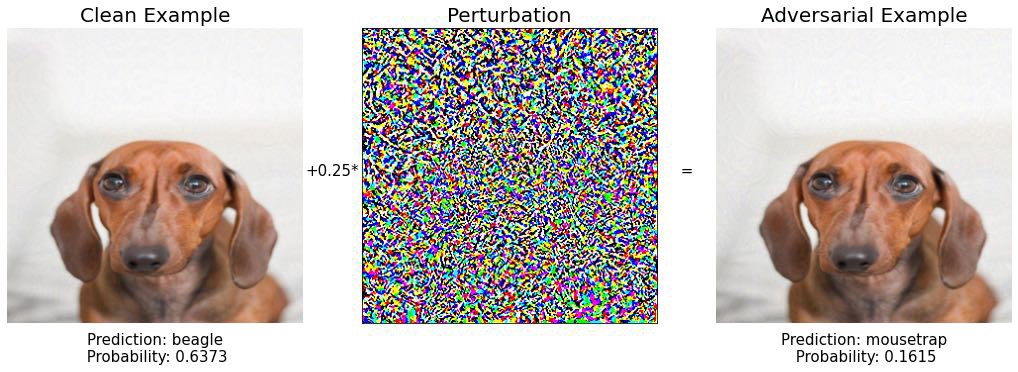
Пойдем дальше.
Шаг 4: Еще одна порода собак, скучная…
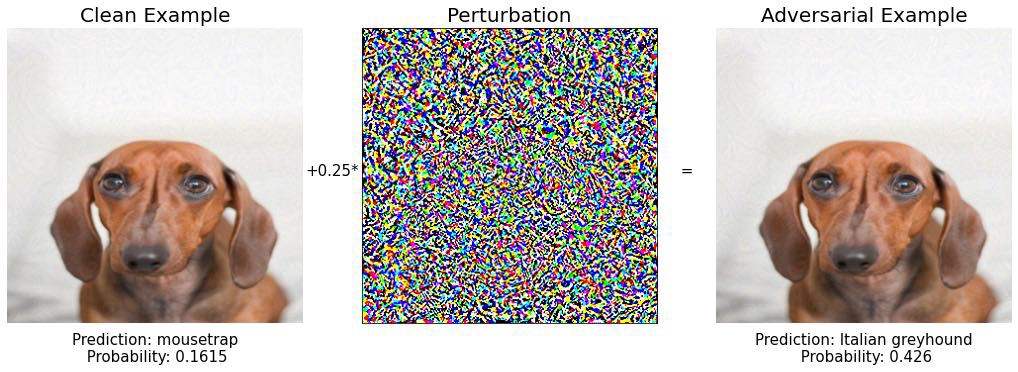
Шаг 5: снова бигль..
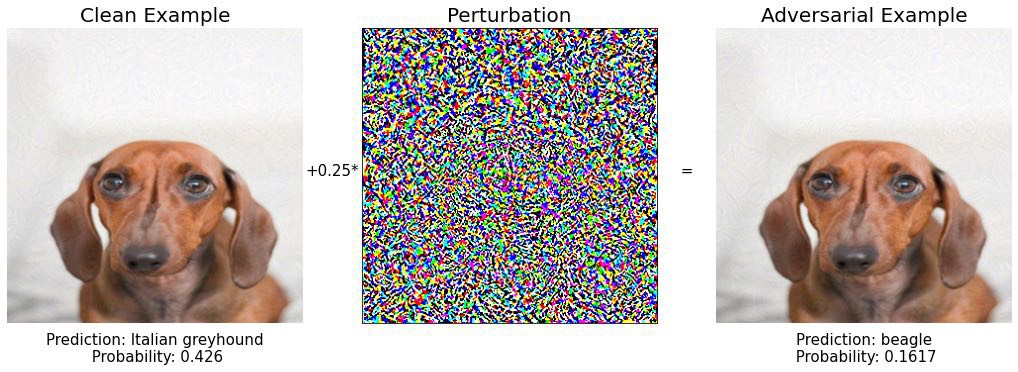
Шаг 6:
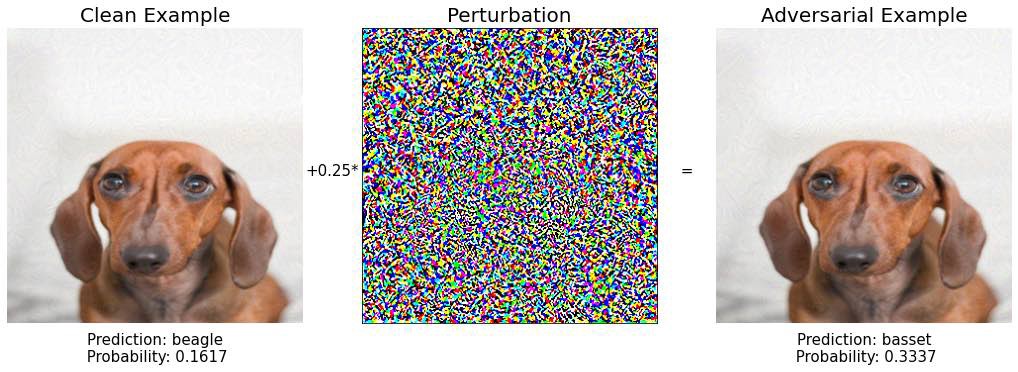
Шаг 7: снова красная кость. Сохраняйте спокойствие и продолжайте идти в пространстве изображения.
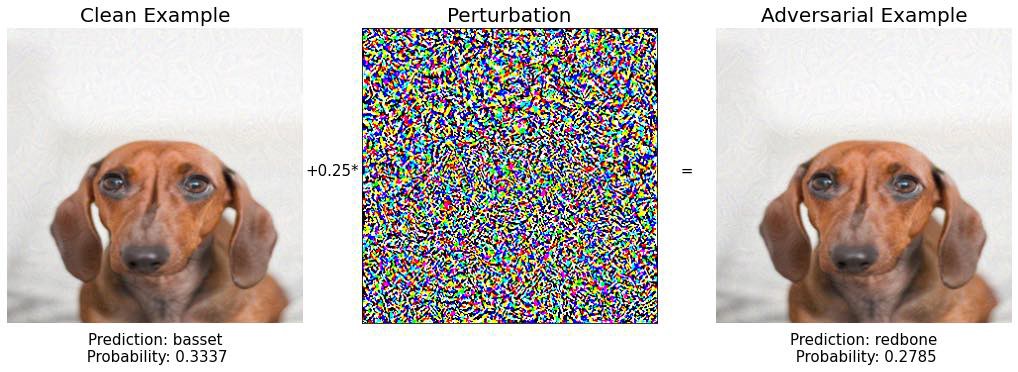
Шаг 8:
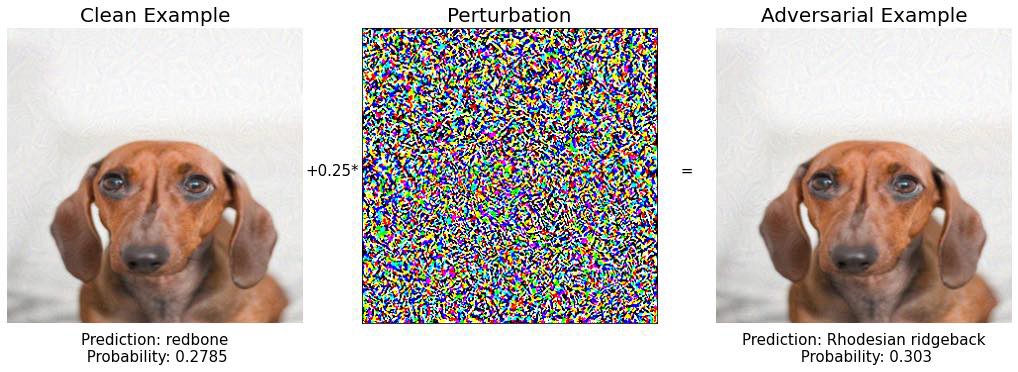
Шаг 9: БИНГО! 🔥🔥🔥
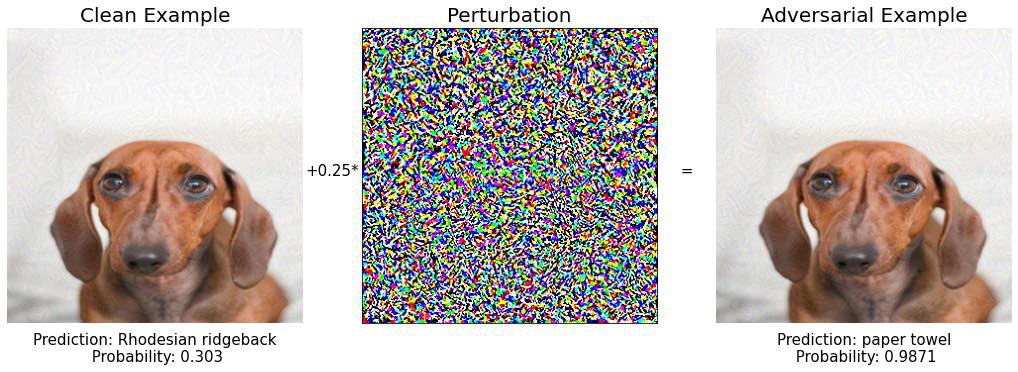
Какое экзотическое бумажное полотенце. И модель довольно уверена в своем прогнозе, почти на 99%.
Если вы сравните начальное и конечное изображение, которое мы нашли на шаге 9

вы видите, что они по сути одинаковы, щенок, но для модели Inception V3 это две совершенно разные вещи.
Я был очень удивлен, когда впервые увидел такое. Как небольшие изменения изображения могут привести к неправильному поведению модели. Этот пример забавный, но если вы подумаете о последствиях для концепции беспилотного автомобиля, вы можете начать немного беспокоиться.
Модели глубокого обучения, развернутые в критических задачах, должны правильно обрабатывать состязательные примеры, но как?
4. Как защитить свои модели от состязательных примеров?
По состоянию на ноябрь 2021 года не существует универсальной стратегии защиты, которой вы могли бы следовать, чтобы защититься от враждебных примеров. Другими словами, атаковать модель состязательными примерами легче, чем защищать ее.
Наилучшей универсальной стратегией, способной защитить от любой известной атаки, является использование состязательных примеров при обучении модели.
Если модель «видит» состязательные примеры во время обучения, ее производительность во время прогнозирования будет лучше для состязательных примеров, сгенерированных таким же образом. Эта техника называется состязательной тренировкой.
Вы генерируете их на лету, когда обучаете модель, и настраиваете функцию потерь, чтобы учитывать как чистые, так и враждебные входные данные.

Например, мы могли бы устранить враждебные примеры, которые мы нашли в предыдущем разделе, если бы мы добавили 10+ примеров в обучающий набор и пометили их все как красная кость.
Эта защита очень эффективна против атак, использующих метод Fast Gradient Sign. Однако существуют более мощные атаки, которые мы не рассмотрели в этом посте и которые могут обойти эту защиту. Если вы хотите узнать больше, я рекомендую вам прочитать эту замечательную статью Николаса Карлини и Дэвида Вагнера.
Именно по этой причине противоборствующая защита является открытой проблемой в машинном обучении и кибербезопасности.
Вывод
Враждебные примеры — увлекательная тема на стыке кибербезопасности и машинного обучения. Тем не менее, это все еще открытая проблема, ожидающая своего решения.
В этом посте я дал практическое введение в тему с примерами кода. Если вы хотите продолжить работу, я предлагаю cleverhans, библиотеку Python для состязательного машинного обучения, разработанную великими Яном Гудфеллоу и Николасом Папернотом, и в настоящее время поддерживается Университетом Торонто.
Весь исходный код, показанный в этой статье, находится в этом репозитории Github.
Хотите стать профессионалом в области машинного обучения?
Я предлагаю практические материалы по реальному машинному обучению, которые помогут вам получить лучшую работу в мире данных.
👉🏽 Подпишитесь на datamachinesновостную рассылку.
👉🏽 Следите за мной в LinkedIn и Twitter.
Хорошего дня 🧡
Пау
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27175)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)