

Достижение соответствующих ответов LLM путем решения общих проблем поиска дополненной генерации
17 января 2024 г.Разработка приложений генеративного ИИ с помощью дополненная генерация извлечения (RAG) и векторные базы данных могут быть сложной задачей. Вам часто придется устранять неполадки в реализациях RAG, которые полагаются на векторные базы данных, чтобы гарантировать получение соответствующего контекста; это очень важно, поскольку этот контекст затем включается в приглашение к большой языковой модели для получения более точных результатов.
В предыдущей статье этой серии мы рассмотрели конвейер внедрения, который заполняет база данных векторов с встраиваниями и рассмотрела три области, которые могут привести к плохим результатам: неоптимальные модели встраивания, неэффективные стратегии разбивки на фрагменты и отсутствие фильтрации метаданных.
Здесь мы рассмотрим фактическое взаимодействие с LLM и рассмотрим пару распространенных проблем, которые могут привести к плохим результатам: неточные подсказки и недостаточные подходы к генерации.
Быстрое уточнение
Даже самые лучшие стратегии внедрения и фрагментации не могут заменить потребность в качестве оперативное проектирование. Это подразумевает, что подсказки станут более явными, конкретными и соответствующими желаемому результату. Для более точной настройки процесса RAG следует протестировать различные форматы, длину и лексический выбор подсказок.
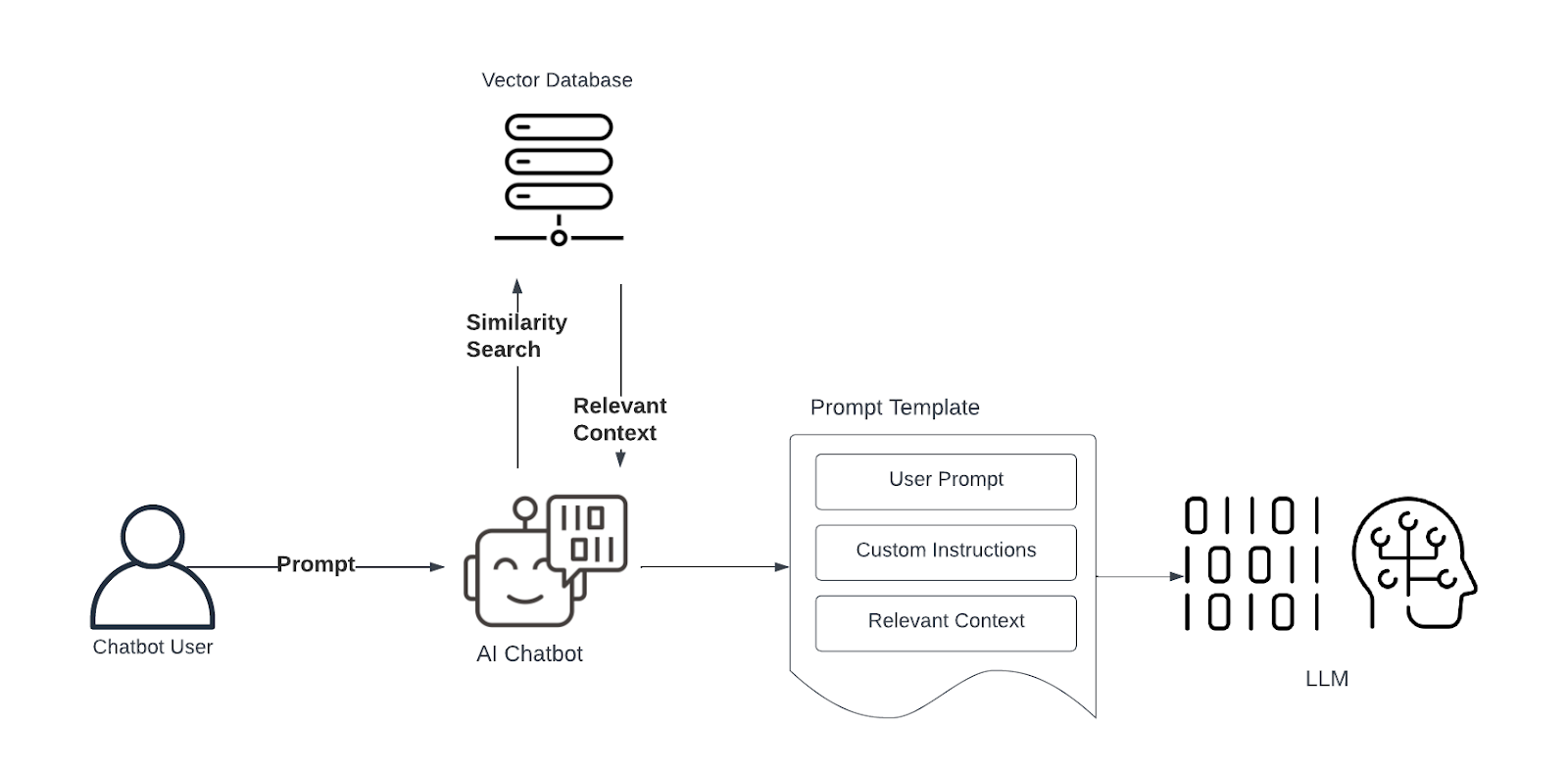
В частности, есть несколько вещей, которые следует учитывать при создании подсказок для приложений RAG. К ним относятся:
Сообщите LLM о его роли. При взаимодействии с агентами LLM, такими как ChatGPT, они по умолчанию действуют как полезный чат-бот. Однако вы можете изменить характер ответов, которые будут генерироваться, проинструктировав LLM действовать определенным образом. Примерами могут быть такие вещи, как «вы являетесь адвокатом, оценивающим, нарушает ли какая-либо из сторон соглашение» или «вы являетесь агентом по обслуживанию клиентов интернет-провайдера; ваша работа — помогать людям решать проблемы с Интернетом» или что-то еще, что имеет смысл в вашей конкретной ситуации.
Явно сообщите LLM использовать предоставленный контекст. Дайте понять LLM, что вы предоставляете контекст и хотите, чтобы сгенерированный ответ отражал этот контекст. Вы можете сделать это, сказав что-то вроде «ваш ответ должен учитывать следующий контекст», а затем контекст. Используйте примеры: В только что упомянутом сценарии, когда вы просите LLM выступить в качестве адвоката по оценке контрактов, вы можете включить в подсказку несколько примеров. Например, вы можете привести пример контракта, в котором указано, что оплата должна быть произведена в течение 30 дней, но покупатель не отправил платеж до истечения 40 дней после подписания контракта и, следовательно, нарушил соглашение. Вы можете привести дополнительные примеры прав на возмещение и возможные способы устранения нарушений контракта.
Укажите формат вывода. Если ваш вариант использования требует определенного вывода, вы можете указать формат, которому должен соответствовать сгенерированный вывод. Вы можете объединить этот метод с приведенным выше советом, чтобы предоставить примеры, которые пояснят LLM как то, как вы хотите, чтобы он реагировал, а также ключевые моменты информации, которую вы ожидаете в сгенерированном ответе.
Используйте цепочку мыслей. В случаях, когда для определения подходящего ответа требуется рассуждение, вы можете рассмотреть возможность использования метода под названием цепочка мыслей, чтобы объяснить шаги, которые вы хотите, чтобы LLM выполнил, чтобы получить сгенерированный ответ. Например, в случае с юридическими контрактами вы можете провести LLM через логические шаги, которым должен следовать человек, чтобы определить, было ли нарушено условие контракта. Например, при работе с юридическими контрактами вы можете попросить LLM сначала поискать положения, определяющие условия оплаты, затем определить количество времени, в течение которого покупатель должен был отправить платеж, а затем подсчитать количество дней между моментом получения платежа и датой получения платежа. дату подписания договора. Тогда, если оплата заняла больше времени, чем оговорено, покупатель нарушил соглашение.
Использование этих методов для улучшения оперативного проектирования может оказать существенное влияние на качество получаемых результатов, которые вы можете получить в своих приложениях RAG. Однако иногда вам придется использовать методы, предполагающие множественный обмен информацией с LLM, чтобы получить приемлемый ответ.
Расширенные шаблоны
ВСПЫШКА
Упреждающий активный поиск, или FLARE, — это пример RAG с несколькими запросами. метод, который включает в себя итеративный вызов LLM с использованием специальных инструкций в подсказке, которые просят LLM предоставить дополнительные вопросы о ключевых фразах, которые помогут ему сгенерировать лучший ответ. Как только LLM имеет контекст без пробелов, он завершается окончательным ответом. В процессе добавляется цикл между LLM и ИИ-агентом (ИИ-чат-бот на диаграмме), чтобы облегчить эти итерации:
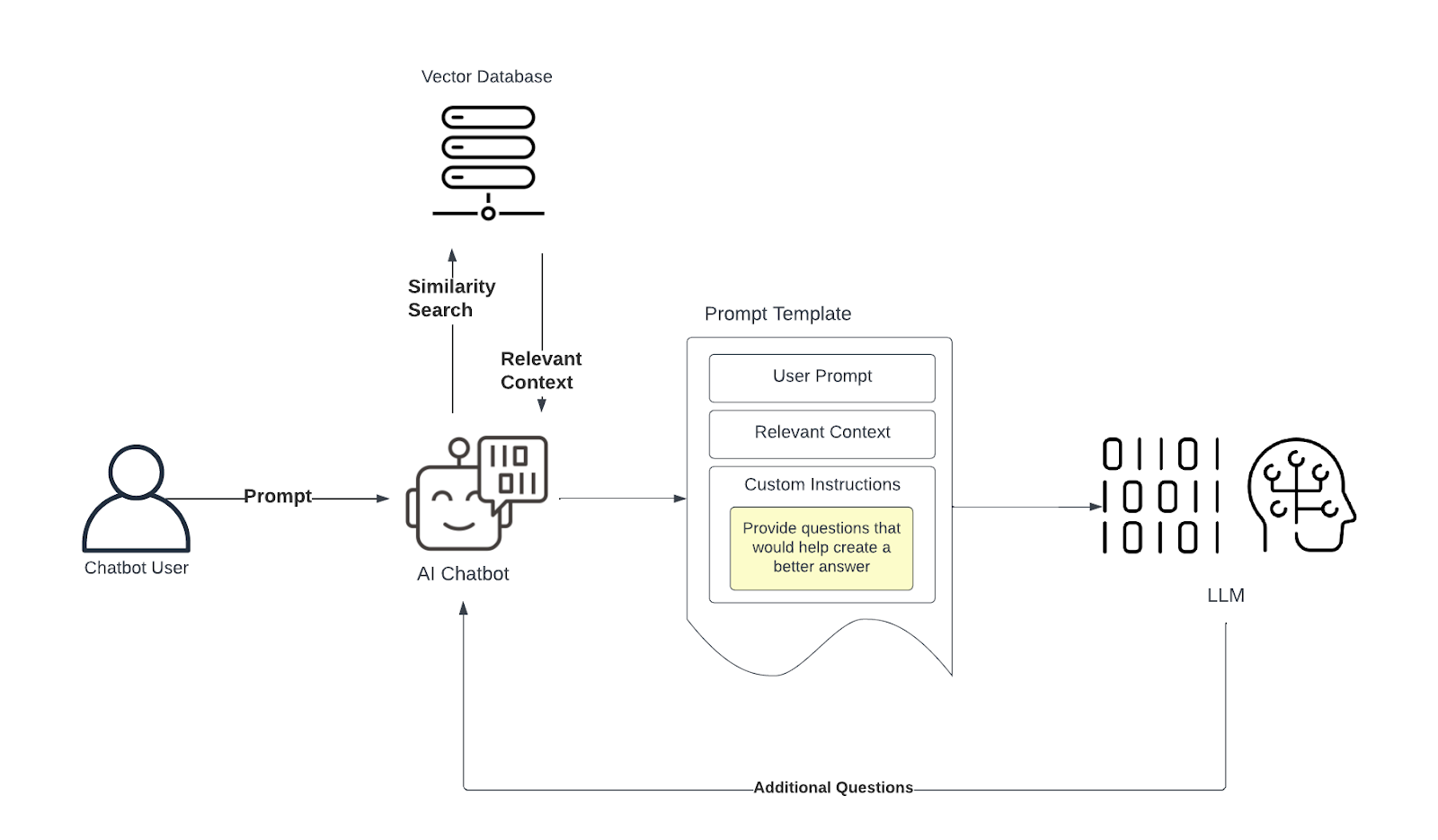
Вы можете увидеть пример того, как работает FLARE, в примере кулинарной книги LangChain FLARE. .
РАГ Фьюжн
Создавая запросы, аналогичные запросу пользователя, и получая соответствующий контекст как для исходного запроса, так и для сгенерированных похожих запросов, мы можем повысить вероятность того, что мы выбрали наиболее полезный контекст для получения точных результатов. Процесс, получивший название «RAG-слияние», выглядит следующим образом:
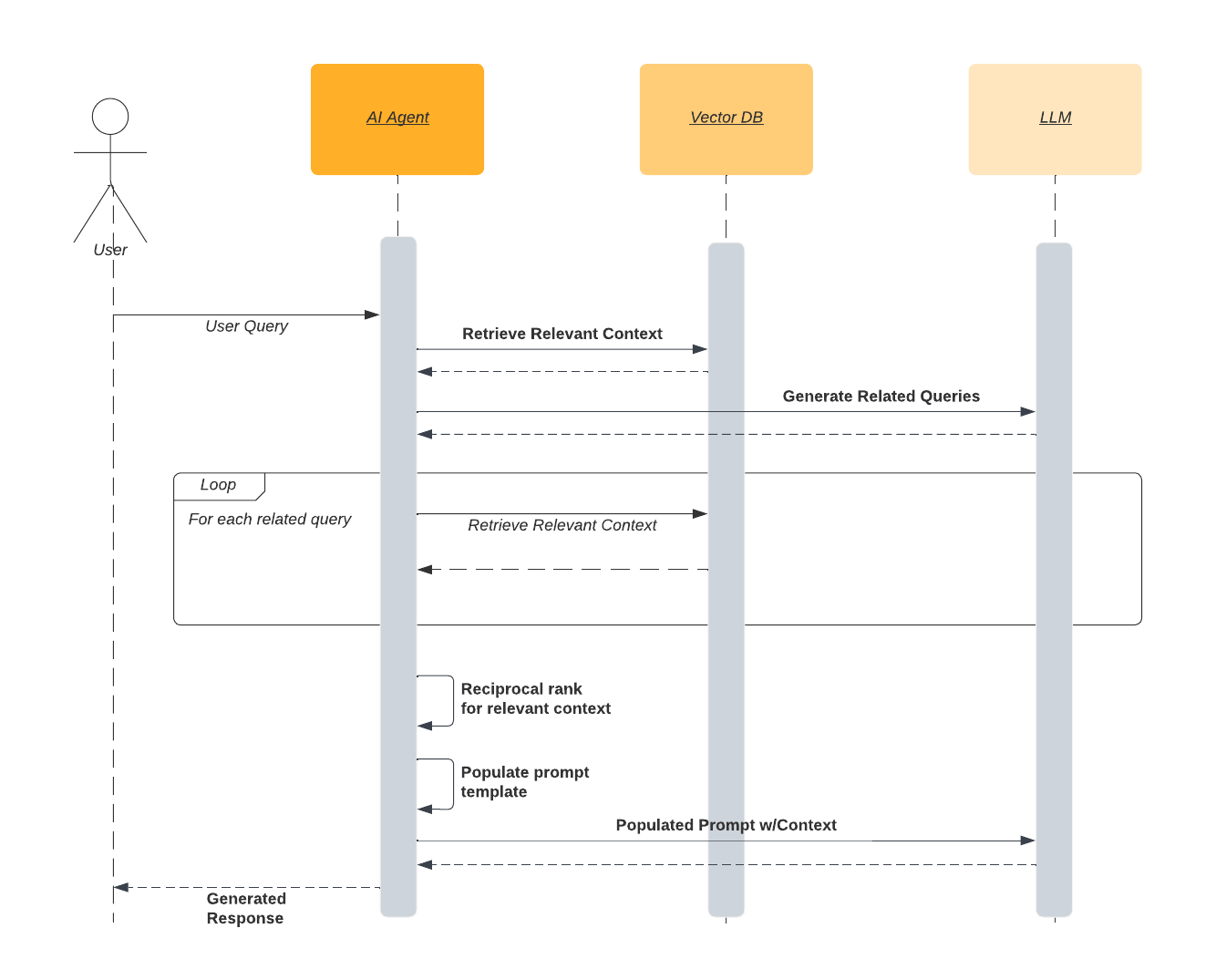
Ключевым шагом здесь является использование функции взаимного ранга для дальнейшего уточнения результатов ИНС, чтобы определить наиболее релевантный контекст, который следует использовать для генерации ответа.
Заключение
RAG – это подход, с которым легко начать, но он часто приводит разработчиков к разочарованию из-за неудовлетворительных результатов по неясным причинам. На актуальность результатов в приложениях генеративного искусственного интеллекта с поддержкой RAG может влиять несколько факторов. Тщательно выбирая модели внедрения, формулируя стратегии разбиения на блоки и разрабатывая подсказки, вы можете значительно повысить качество и точность генерируемых ответов в системах, работающих на основе LLM, таких как ChatGPT. Надеемся, эти советы помогут вам создавать более полезные приложения RAG, которые обеспечат тот опыт и ценность, к которым вы стремитесь.
Попробуйте DataStax Astra DB, единственную векторную базу данных для создания приложений искусственного интеллекта промышленного уровня на основе данных в реальном времени.
Крис Латимер, DataStax
:::информация Также появляется здесь.
:::
Оригинал