
Учебное пособие о том, как создать свой собственный RAG и запустить его локально: Langchain + Ollama + Streamlit
15 декабря 2023 г.С появлением больших языковых моделей и их впечатляющими возможностями на базе таких гигантских поставщиков LLM, как OpenAI и Anthropic, создается множество необычных приложений. Мифом таких приложений является структура RAG, которая подробно описана в следующих статьях:
- Создание на основе RAG Приложения LLM для производства
- Описание извлеченной дополненной генерации (RAG): понимание ключевых понятий< /strong>
- Что такое генерация с расширенным поиском?
Для знакомства с RAG рекомендую просмотреть эти статьи. Однако в этой статье мы пропустим основы и покажем вам, как создать собственное приложение RAG, которое можно будет запускать локально на вашем ноутбуке, не беспокоясь о конфиденциальности данных и стоимости токенов.
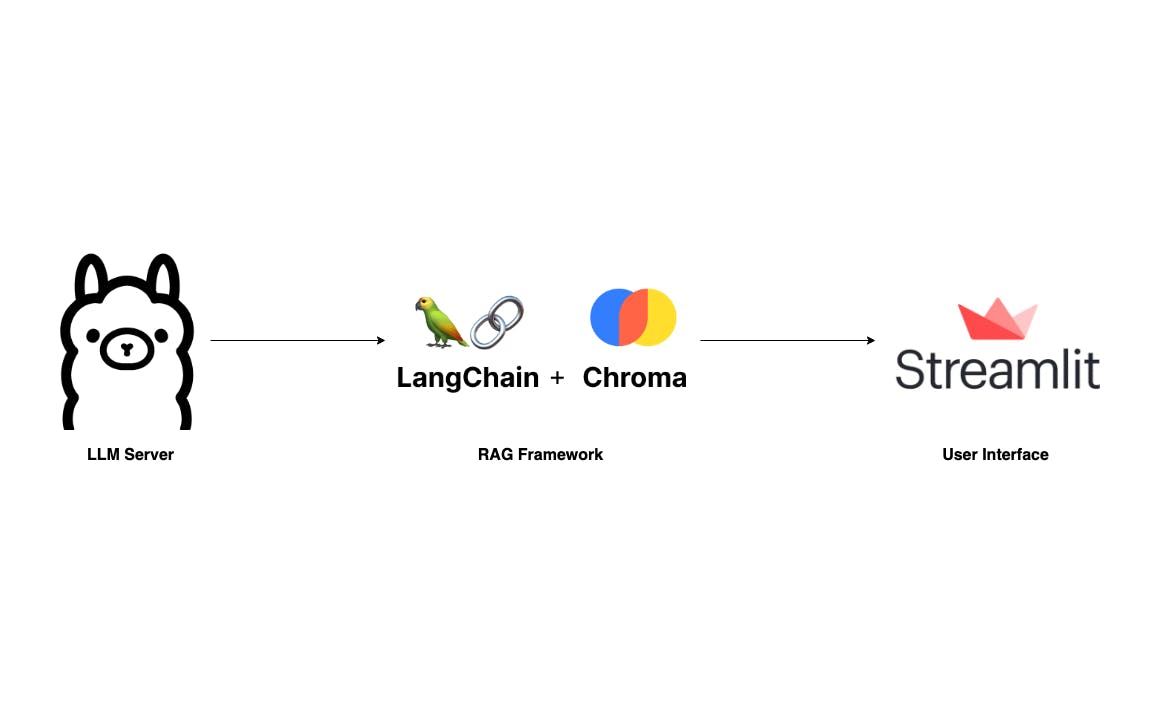
Мы создадим приложение, похожее на ChatPDF, но более простое. Где пользователи могут загружать PDF-документы и задавать вопросы через простой пользовательский интерфейс. Наш стек технологий очень прост: Langchain, Ollama и Streamlit.
- Сервер LLM. Наиболее важным компонентом этого приложения является сервер LLM. Благодаря Ollama у нас есть надежный LLM-сервер, который можно настроить локально, даже на ноутбуке. Хотя llama.cpp является вариантом, я считаю, что Ollama, написанная на Go, проще установить вперед и вперед.
* RAG: Несомненно, двумя ведущими библиотеками в области LLM являются Langchain и LLamIndex. В этом проекте я буду использовать Langchain, поскольку знаком с ним по профессиональному опыту. Важным компонентом любой среды RAG является векторное хранилище. Мы будем использовать здесь Chroma, поскольку он хорошо интегрируется с Langchain.
* Интерфейс чата. Пользовательский интерфейс также является важным компонентом. Хотя существует множество доступных технологий, для спокойствия я предпочитаю использовать Streamlit, библиотеку Python.
Хорошо, приступим к настройке.
Настройка Олламы
Как упоминалось выше, настройка и запуск Ollama просты. Сначала посетите ollama.ai и загрузите приложение, подходящее для вашей операционной системы.
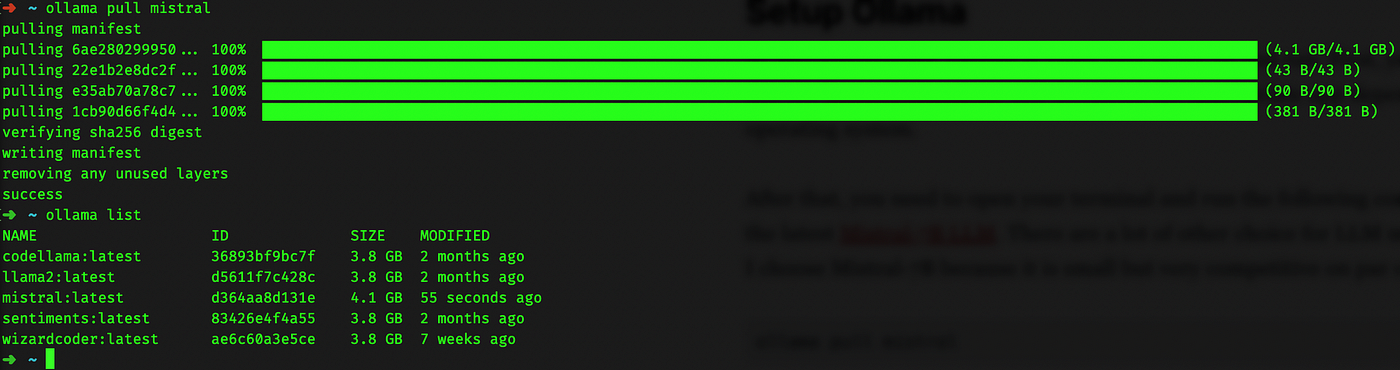
Затем откройте терминал и выполните следующую команду, чтобы получить последнюю версию Mistral-7B. Хотя существует множество других моделей LLM, я выбираю Mistral-7B из-за его компактных размеров и конкурентоспособного качества.< /п>
ollama pull mistral
После этого запустите ollama list, чтобы проверить, правильно ли была получена модель. Вывод терминала должен выглядеть следующим образом:
Теперь, если сервер LLM еще не запущен, запустите его с помощью ollama serve. Если вы столкнулись с сообщением об ошибке, например "Ошибка: прослушайте tcp 127.0.0.1:11434: привязка: адрес уже используется", это означает, что сервер уже запущен по умолчанию, и вы можете перейти к следующему шаг.
Создание конвейера RAG
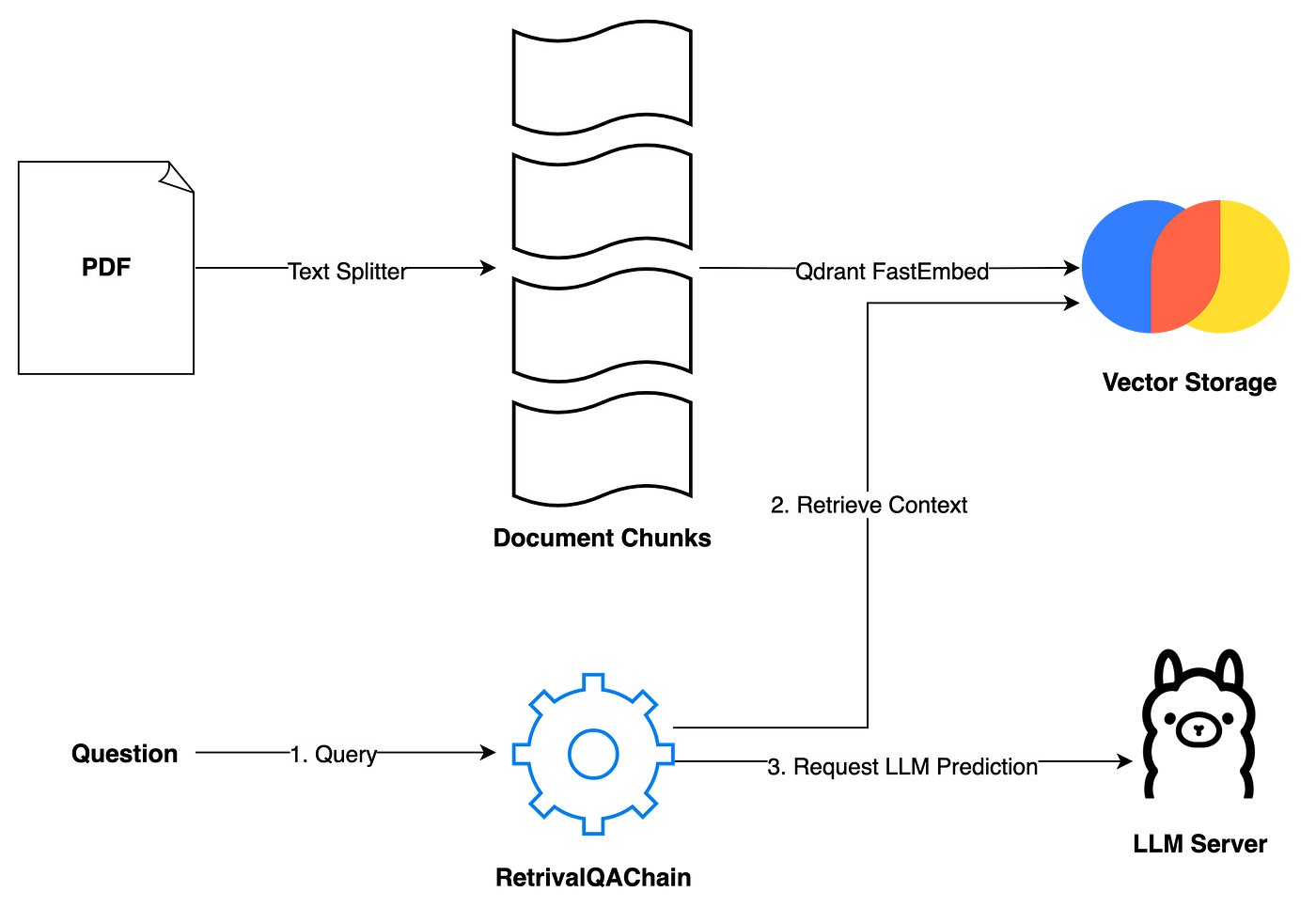
Вторым шагом в нашем процессе является создание конвейера RAG. Учитывая простоту нашего приложения, нам в первую очередь нужны два метода: ingest и ask.
Метод ingest принимает путь к файлу и загружает его в векторное хранилище в два этапа: во-первых, он разбивает документ на более мелкие фрагменты, чтобы соответствовать лимиту токенов LLM; во-вторых, он векторизует эти фрагменты с помощью Qdrant FastEmbeddings и сохраняет их в Chroma.
Метод ask обрабатывает запросы пользователей. Пользователи могут задать вопрос, а затем RetrivalQAChain извлекает соответствующие контексты (фрагменты документов), используя методы поиска векторного сходства.
Используя вопрос пользователя и полученные контексты, мы можем составить подсказку и запросить прогноз от сервера LLM.
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOllama
from langchain.embeddings import FastEmbedEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
from langchain.vectorstores.utils import filter_complex_metadata
class ChatPDF:
vector_store = None
retriever = None
chain = None
def __init__(self):
self.model = ChatOllama(model="mistral")
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100)
self.prompt = PromptTemplate.from_template(
"""
<s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context
to answer the question. If you don't know the answer, just say that you don't know. Use three sentences
maximum and keep the answer concise. [/INST] </s>
[INST] Question: {question}
Context: {context}
Answer: [/INST]
"""
)
def ingest(self, pdf_file_path: str):
docs = PyPDFLoader(file_path=pdf_file_path).load()
chunks = self.text_splitter.split_documents(docs)
chunks = filter_complex_metadata(chunks)
vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings())
self.retriever = vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"k": 3,
"score_threshold": 0.5,
},
)
self.chain = ({"context": self.retriever, "question": RunnablePassthrough()}
| self.prompt
| self.model
| StrOutputParser())
def ask(self, query: str):
if not self.chain:
return "Please, add a PDF document first."
return self.chain.invoke(query)
def clear(self):
self.vector_store = None
self.retriever = None
self.chain = None
Приглашение получено из хаба Langchain: Langchain RAG Prompt для Mistral . Эта подсказка была протестирована и загружена тысячи раз и служит надежным ресурсом для изучения методов подсказок LLM.
Вы можете узнать больше о методах подсказок LLM здесь.
Подробнее о реализации:
* ingest: мы используем PyPDFLoader для загрузки PDF-файла, загруженного пользователем. RecursiveCharacterSplitter, предоставленный Langchain, затем разбивает этот PDF-файл на более мелкие фрагменты. Важно отфильтровывать сложные метаданные, не поддерживаемые ChromaDB, с помощью функции filter_complex_metadata из Langchain.
Для векторного хранения используется Chroma в сочетании с Qdrant FastEmbed в качестве модели внедрения. Эта облегченная модель затем преобразуется в ретривер с порогом оценки 0,5 и k=3, что означает, что она возвращает 3 верхних фрагмента с наивысшими оценками выше 0,5. Наконец, мы создаем простую цепочку диалогов, используя LECL.
* ask: этот метод просто передает вопрос пользователя в нашу предопределенную цепочку, а затем возвращает результат.
* clear: этот метод используется для очистки предыдущего сеанса чата и хранилища при загрузке нового PDF-файла.
Набросок простого пользовательского интерфейса
Для простого пользовательского интерфейса мы будем использовать Streamlit, инфраструктуру пользовательского интерфейса, предназначенную для быстрого создания прототипов ИИ. /ML-приложения.
import os
import tempfile
import streamlit as st
from streamlit_chat import message
from rag import ChatPDF
st.set_page_config(page_title="ChatPDF")
def display_messages():
st.subheader("Chat")
for i, (msg, is_user) in enumerate(st.session_state["messages"]):
message(msg, is_user=is_user, key=str(i))
st.session_state["thinking_spinner"] = st.empty()
def process_input():
if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0:
user_text = st.session_state["user_input"].strip()
with st.session_state["thinking_spinner"], st.spinner(f"Thinking"):
agent_text = st.session_state["assistant"].ask(user_text)
st.session_state["messages"].append((user_text, True))
st.session_state["messages"].append((agent_text, False))
def read_and_save_file():
st.session_state["assistant"].clear()
st.session_state["messages"] = []
st.session_state["user_input"] = ""
for file in st.session_state["file_uploader"]:
with tempfile.NamedTemporaryFile(delete=False) as tf:
tf.write(file.getbuffer())
file_path = tf.name
with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"):
st.session_state["assistant"].ingest(file_path)
os.remove(file_path)
def page():
if len(st.session_state) == 0:
st.session_state["messages"] = []
st.session_state["assistant"] = ChatPDF()
st.header("ChatPDF")
st.subheader("Upload a document")
st.file_uploader(
"Upload document",
type=["pdf"],
key="file_uploader",
on_change=read_and_save_file,
label_visibility="collapsed",
accept_multiple_files=True,
)
st.session_state["ingestion_spinner"] = st.empty()
display_messages()
st.text_input("Message", key="user_input", on_change=process_input)
if __name__ == "__main__":
page()
Запустите этот код с помощью команды streamlit run app.py, чтобы увидеть, как он выглядит.
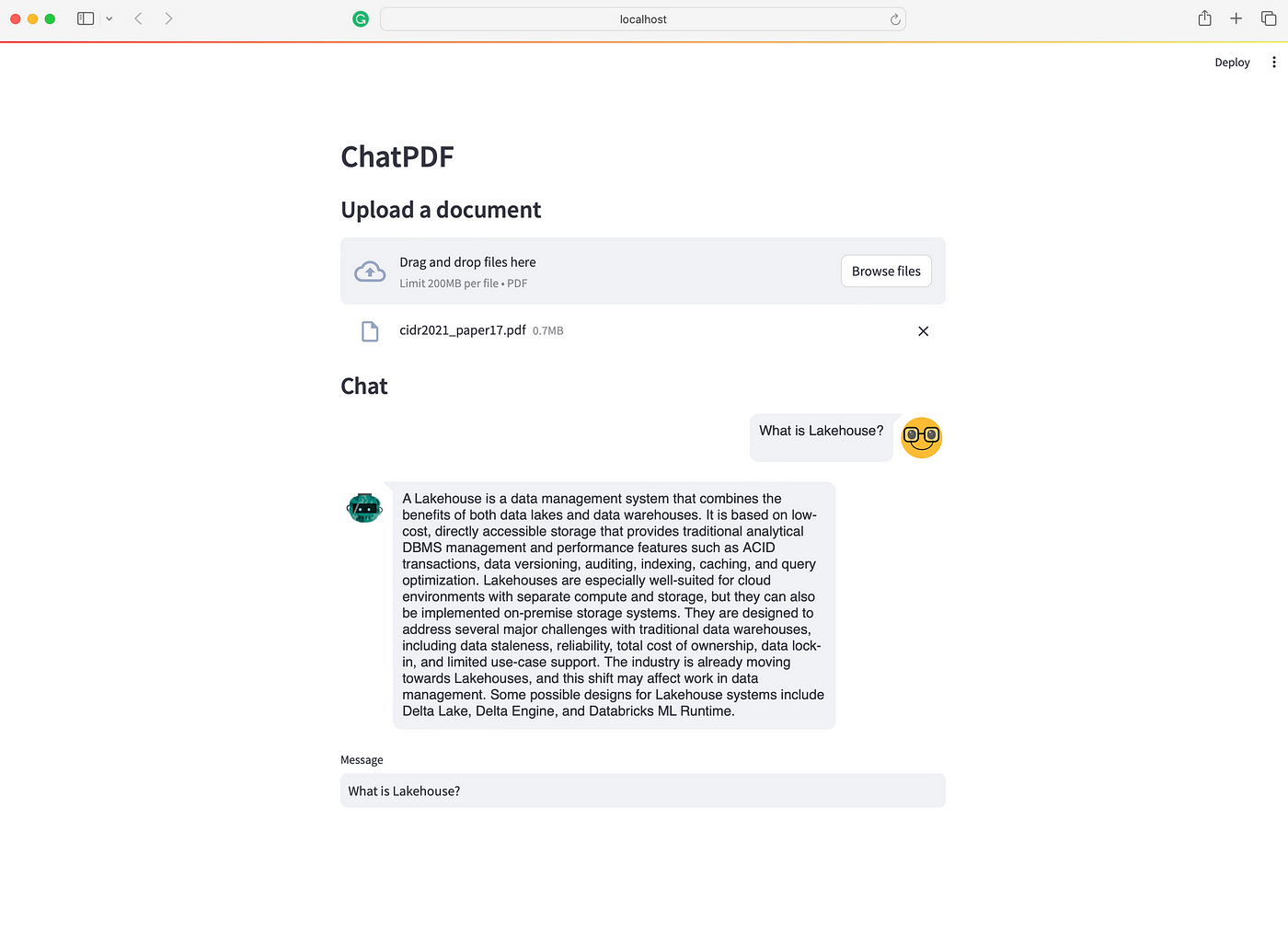
Хорошо, вот и все! Теперь у нас есть приложение ChatPDF, которое полностью работает на вашем ноутбуке. Поскольку этот пост в основном посвящен общему обзору того, как создать собственное приложение RAG, есть несколько аспектов, которые требуют тонкой настройки. Вы можете рассмотреть следующие предложения, чтобы улучшить свое приложение и развить свои навыки:
* Добавить память в цепочку разговора: в настоящее время он не запоминает ход разговора. Добавление временной памяти поможет вашему помощнику понимать контекст.
* Разрешить загрузку нескольких файлов: можно обсуждать одновременно один документ. Но представьте, если бы мы могли обсуждать несколько документов — вы могли бы поместить туда всю свою книжную полку. Это было бы очень круто!
* Используйте другие модели LLM. Хотя Mistral эффективен, существует множество других альтернатив. Возможно, вы найдете модель, которая лучше соответствует вашим потребностям, например LlamaCode для разработчиков. Однако помните, что выбор модели зависит от вашего оборудования, особенно от объема оперативной памяти 💵
* Расширение конвейера RAG: внутри RAG есть место для экспериментов. Возможно, вы захотите изменить метрику поиска, модель внедрения или добавить слои, например систему повторного ранжирования, чтобы улучшить результаты.
Наконец, спасибо за чтение. Если вы считаете эту информацию полезной, рассмотрите возможность подписки на мой Substack или мой личный блог. Я планирую написать больше о приложениях RAG и LLM, и вы можете предлагать темы, оставив комментарий ниже. Ура!
Полный исходный код: https://github.com/vndee/local-rag-example
Оригинал