

Быстрое руководство по технологии генерации кодов LLM и ее пределов
5 августа 2025 г.Таблица ссылок
Аннотация и 1 введение
2. Предыдущие концептуализации интеллектуальной помощи для программистов
3. Краткий обзор больших языковых моделей для генерации кода
4. Коммерческие инструменты программирования, которые используют большие языковые модели
5. Надежность, безопасность и последствия безопасности моделей ИИ, генерирующих код,
6. Изузаение юзабилити и дизайна программирования A-ассистентного
7. Опыт отчетов и 7.1. Писать эффективные подсказки сложно
7.2 Активность программирования сдвигается в сторону проверки и незнакомой отладки
7.3. Эти инструменты полезны для шаблона и повторного использования кода
8. Неадекватность существующих метафор для программирования A-A-Advisted
8.1. Помощь ИИ в качестве поиска
8.2. Помощь ИИ в качестве компиляции
8.3. Помощь ИИ в качестве парного программирования
8.4. Отчетливый способ программирования
9. Проблемы с применением программирования конечного пользователя
9.1. Выпуск 1: Спецификация намерений, разложение проблемы и вычислительное мышление
9.2. Выпуск 2: Правильность кода, качество и (над) уверенность
9.3. Выпуск 3: Понимание и обслуживание кода
9.4. Выпуск 4: Последствия автоматизации в программировании конечных пользователей
9.5. Выпуск 5: Код без кода и дилемма прямого ответа
10. Заключение
A. Источники отчета о испытании
Ссылки
3. Краткий обзор больших языковых моделей для генерации кода
3.1. Архитектура трансформатора и большие наборы данных включают большие предварительно обученные модели
В 2010 -х годах обработка естественного языка развивалась при разработке языковых моделей (LMS) и оценки. Mikolov et al. (2013) введены Word2VEC, где векторы присваиваются словам, подобным тому, что подобные слова сгруппированы вместе. Он опирается на совместные действия в тексте (например, статьи Википедии), хотя простые экземпляры игнорируют тот факт, что слова могут иметь множество значений в зависимости от контекста. Длинная кратковременная память (LSTM) нейронные сети (Hochreiter & Schmidhuber, 1997; Sutskever et al., 2014) и более поздние сети энкодера-декодера, учетная запись за порядок в входной последовательности. Самоализация (Vaswani et al., 2017) значительно упростило предыдущие сети, заменив каждый элемент на входе на средневзвешенное значение остальной части ввода. Трансформеры объединили преимущества (мульти-головного внимания и встроения слов, обогащенные позиционными кодировками (которые добавляют информацию о порядок в слово «встраиваемые») в одну архитектуру. Несмотря на то, что есть много альтернатив трансформаторам для языкового моделирования, в этой статье, когда мы упоминаем языковую модель, мы обычно подразумеваем языковую модель на основе трансформатора.
Существуют большие коллекции некабельности для некоторых широко говорящих естественных языков. Например, проект Common Crawl [1] производит около 20 ТБ текстовых данных (с веб -страниц) ежемесячно. Данные с маркировкой задачи менее распространены. Это делает неконтролируемое обучение привлекательным. Предварительно обученные LMS (J. Li et al., 2021) обычно обучаются выполнять прогнозирование следующего слова (например, GPT (Brown et al., 2020)) или заполнения разрыва в последовательности (например, Bert (Devlin et al., 2019)).
В идеале, «общие знания», изученные предварительно обученным LMS, могут затем быть переданы в нижестоящие языковые задачи (где у нас есть менее помеченные данные), такие как ответ на вопрос, генерацию художественной литературы, текстовое обобщение и т. Д. Пылая настройка-это процесс адаптации заданного предварительно обученного LM к различным задачам ниже по течению, внедряя дополнительные параметры и обучение их используемым задачами объективными функциями. В некоторых случаях объектив предварительного обучения также корректируется, чтобы лучше соответствовать задаче нисходящего. Вместо (или на вершине) тонкую настройку, нижняя задача может быть переформулирована, чтобы она была похожа на оригинальное обучение LLM. На практике это означает выражение задачи как набор инструкций для LLM через подсказку. Таким образом, цель, вместо того, чтобы определять цель обучения для данной задачи, состоит в том, чтобы найти способ запросить LLM, чтобы напрямую предсказать для нижестоящей задачи. Иногда это называется предварительным, предсказанным, предсказанным. [2]
3.2. Языковые модели, настроенные для генерации исходного кода
Нисходящая задача интереса для нас в этой статье - генерация кода, где вход в модель представляет собой смесь комментариев естественного языка и фрагментов кода, а вывод - новый код. В отличие от других нисходящих задач, большой корпус данных доступен в репозиториях общедоступного кода, таких как GitHub. Генерация кода может быть разделена на многие подзадачи, такие как генерация типа переменной, например, (J. Wei et al., 2020), генерация комментариев, например, (Liu et al., 2021), Дубликатное обнаружение, например (Mou et al., 2016), миграция кода с одного языка на другой, например, (Nguyen et al., 2015) и т. Д.
Технология LLM привела нас в пределах досягаемости генерации полной сети. Codex (Chen, Tworek, Jun, Yuan, Ponde, et al., 2021), версия GPT-3, настраиваемой для генерации кода, может решить в среднем 47/164 задачи в эталоне генерации кода Humaneval, в одной попытке. Humaneval представляет собой набор из 164 рукописных задач программирования, которые включают подпись функции, Docstring, тело и несколько модульных тестов, в среднем 7,7 тестов на проблему. Меньшие модели следовали за кодексом, например, GPT-J [3] (тонко настроенный на вершине GPT-2), CodeParrot [4] (также тонко настраиваемый на вершине GPT-2, нацеливается на поколения Python), Polycoder (Xu, Alon, et al., 2022) (GPT-2, но подготовлен непосредственно по коду).
LLMS, сопоставимые по размеру с кодексом, включают альфакод (Y. Li et al., 2022a) и пальмовый кодер (Chowdhry et al., 2022). Альфакод обучается непосредственно на данные GitHub и точно настроен на проблемы соревнований по кодированию. Он вводит метод уменьшения от большого количества потенциальных решений (до миллионов) до нескольких кандидатов (соревнования позволяют максимум 10). В наборе данных из 10000 задач программирования Codex решает около 3% проблем в пределах 5 попыток, по сравнению с альфакодом, который решает 4-7%. В соревнованиях, для которых он был тонко настроен (кодовые) Альфакод достигает 34% успеха, наравне со средним конкурентом человека.
Несмотря на многообещающие результаты, есть известные недостатки. Модели могут напрямую копировать полные решения или ключевые части решений из учебных данных, а не генерировать новый код. Хотя разработчики прилагают усилия по очистке и удержанию только высококачественного кода, нет никаких гарантий правильности, и ошибки могут быть непосредственно распространяться в течение поколений.
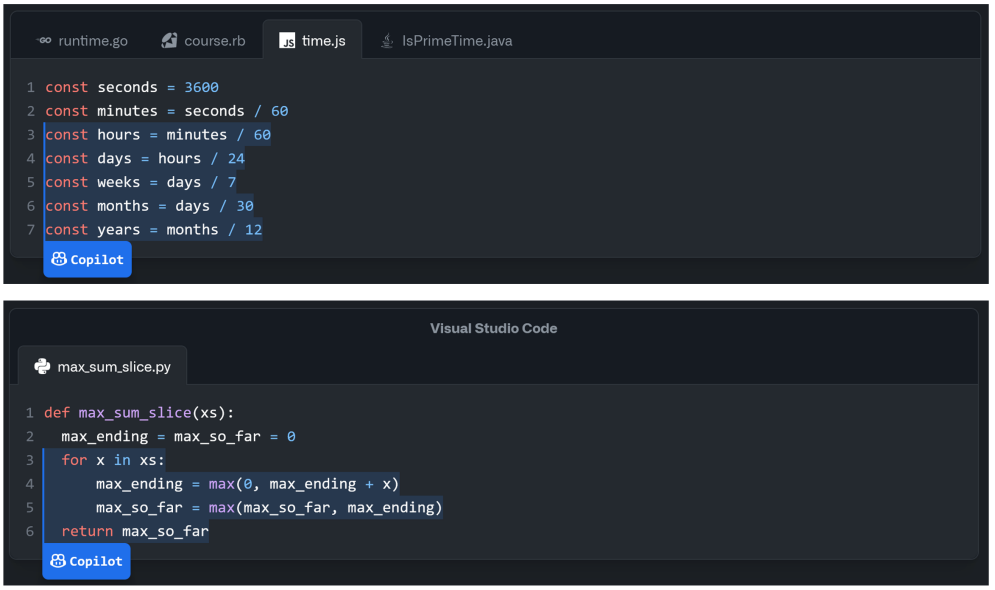
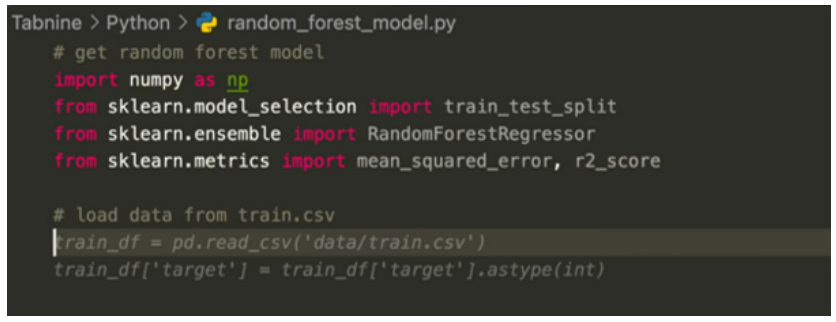
Codex также может создавать синтаксически неверный или неопределенный код, а также может вызывать функции, переменные и атрибуты, которые являются неопределенными или вне сферы действия. Более того, Кодекс изо всех сил пытается проанализировать все более длительные и более высокие спецификации или системного уровня, которые могут привести к ошибкам в операциях связывания с переменными, особенно когда количество операций и переменных в DocString большое. Были исследованы различные подходы, чтобы отфильтровать плохие поколения или восстановить их, особенно для синтаксических ошибок.
Последовательность - это еще одна проблема. Существует компромисс между нетерминизмом и разнообразием поколений. Некоторые настройки параметров могут контролировать разнообразие генерации (то есть, насколько разнообразными могут быть разные поколения для одной подсказки), но нет никакой гарантии, что мы получим одинаковое поколение, если запустим систему в разное время в одном и том же настройках. Чтобы облегчить эту проблему в измерениях, такие показатели, как Pass@K (имеют решение, которое проходит тесты в рамках K попытки) были изменены, чтобы быть вероятностными.
Авторы:
(1) Advait Sarkar, Microsoft Research, Кембриджский университет (advait@microsoft.com);
(2) Эндрю Д. Гордон, Microsoft Research, Эдинбургский университет (adg@microsoft.com);
(3) Карина Негрину, Microsoft Research (cnegreanu@microsoft.com);
(4) Christian Poelitz, Microsoft Research (cpoelitz@microsoft.com);
(5) Sruti Srinivasa Ragavan, Microsoft Research (a-srutis@microsoft.com);
(6) Бен Зорн, Microsoft Research (ben.zorn@microsoft.com).
Эта статья есть
[1] https://commoncrawl.org/
[2] http://pretrain.nlpedia.ai/
[3] https://huggingface.co/docs/transformers/main/model_doc/gptj
[4] https://huggingface.co/blog/codeparrot
Оригинал