

Новая порода чат -ботов тихо меняет управление продуктом
15 июля 2025 г.Если вы менеджер по продукту, чувствуя себя перегруженным своими днями, попавшими в вихрь отзывов клиентов, вы не одиноки! Вот где поиск дополненного поколения (RAG) станет мощным союзником, помогая тихо трансформировать способ взаимодействия с информацией.
Представьте, что вы используете веб-сайт магазина электронной коммерции с сотнями продуктов, каждая из которых имеет свою собственную документацию (ручное, часто задаваемые вопросы, руководства по устранению неисправностей и т. Д.). Клиенты часто спрашивают о конкретных функциях продукта, гарантийной информации или общих проблемах и проблемах. Регулярный чат-бот, обученный исключительно общим данным в Интернете, вероятно, будет бороться за то, чтобы предоставить точные и современные ответы, характерные для ваших продуктов, что приведет к разочарованным клиентам и увеличению билетов на поддержку.
Вот гдеПоиск дополненного поколения (Rag)Приходит на помощь! (В качестве примера!) RAG объединяет мощность больших языковых моделей (LLMS) с пользовательской базой знаний, позволяя LLM доступ и использовать конкретную, соответствующую, соответствующую информацию, на которую она изначально не была обучена.
Проблема с традиционными LLMS
Большие языковые модели, такие как GPT-4 или Gemini, предлагают мощные возможности для понимания языка, поколения и даже написания кода. Тем не менее, их знания «заморожены» во время их последних учебных данных. Они не могут получить доступ к информации в режиме реального времени, проприетарных документов вашей компании или нишевых деталей, недоступных в Интернете. Быть восприимчивым к:
- Галлюцинации:Изготовление ответов вместо того, чтобы признать, что они не знают правильного ответа.
- Устаревшая информация:Предоставление ответов на основе устаревших данных недостаточно.
- Отсутствие специфичности:Невозможно ответить на вопросы, требующие особого знания в области. В контексте поддержки клиентов и внутреннего обмена знаниями требуется постоянная обратная связь от менеджеров по продуктам, чтобы прояснить любые моменты, которые могут быть неясными.
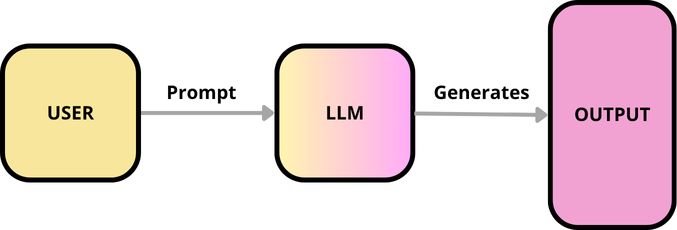
Использование тряпки с LLM помогает решить некоторые из этих проблем. Когда LLM имеет доступ ко всей жизненно важной информации для вашего конкретного приложения, он может лучше ответить на вопросы по темам, на которые она не была специально обучена, что помогает минимизировать шансы на его ошибки или «галлюцинации».
Поигрывательный поколение (RAG) улучшает крупные языковые модели (LLMS) за счет определения наиболее релевантных кусков документов из внешней базы знаний, благодаря сложным расчетам семантического сходства.
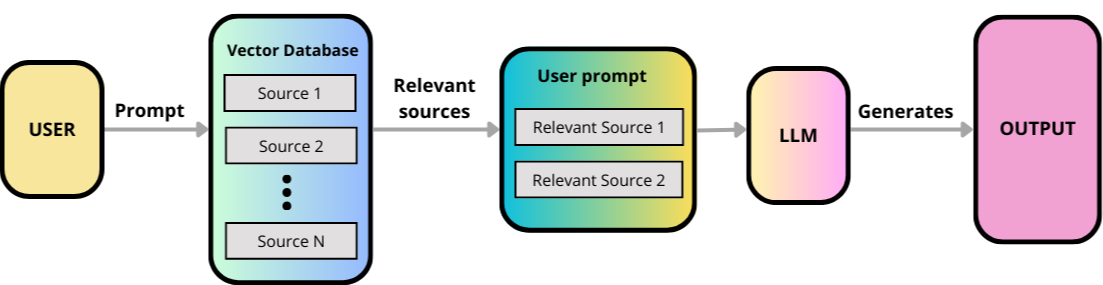
Рэг -решение: пример "Smart Chatbot"
Давайте воспользуемся нашим чат-ботом поддержки клиентов в качестве практического приложения. Вместо того, чтобы зависеть от предварительно обученных статических знаний LLM, наш чат-бот «увеличит» свои ответы, получая соответствующую информацию из небольшой, моделируемой базы знаний о документах продуктов.
Создание базы знаний (фаза проглатывания)
Мы разработаем специализированную базу знаний, содержащую некоторые фиктивные текстовые файлы, которые наша Rag System будет «читать», чтобы получить свои знания. Эти файлы будут представлять нашу вымышленную документацию «продукт XYZ».
Мы будем использовать Python для создания этих файлов напрямую.
import os
# Define the directory for our simulated documents
DOCS_DIR = "product_docs"
os.makedirs(DOCS_DIR, exist_ok=True)
# Content for our dummy product documents
doc_contents = {
"product_manual_xyz.txt": """
Product Manual for XYZ Wireless Earbuds
1. Introduction:
Welcome to your new XYZ Wireless Earbuds! These earbuds offer high-quality audio and a comfortable fit.
2. Charging:
To charge your earbuds, place them in the charging case. The LED indicator on the case will show battery status. A full charge takes approximately 1.5 hours.
3. Pairing:
Open the charging case. The earbuds will automatically enter pairing mode. On your device (phone/laptop), go to Bluetooth settings and select "XYZ Earbuds". The earbuds will emit a sound upon successful connection.
4. Controls:
- Single tap (left/right): Play/Pause
- Double tap (right): Next song
- Double tap (left): Previous song
- Triple tap (left/right): Activate voice assistant
5. Troubleshooting:
- If earbuds are not connecting, ensure they are charged and try resetting them (see section 6).
- If audio is distorted, check your device's volume and ensure no interference.
6. Resetting the Earbuds:
To reset your XYZ Wireless Earbuds to factory settings, place both earbuds in the charging case. Press and hold the button on the charging case for 15 seconds until the LED light blinks red three times. Then, close the case and reopen it.
""",
"faq_warranty.txt": """
Frequently Asked Questions (FAQ) - XYZ Wireless Earbuds
Q: What is the warranty period for the XYZ Earbuds?
A: The XYZ Wireless Earbuds come with a 1-year limited warranty from the date of purchase. Please retain your proof of purchase for warranty claims.
Q: How do I claim warranty?
A: To claim warranty, please visit our support page at [www.xyztech.com/support](https://www.xyztech.com/support) and fill out the warranty claim form, attaching your receipt. Our team will contact you within 2-3 business days.
Q: Are the XYZ Earbuds waterproof?
A: The XYZ Earbuds are splash-resistant (IPX4 rating), meaning they can withstand light rain and sweat. They are NOT designed for submersion in water.
Q: What devices are compatible?
A: The earbuds are compatible with any Bluetooth-enabled device, including smartphones, tablets, and laptops.
""",
"troubleshooting_guide.txt": """
Troubleshooting Guide for XYZ Wireless Earbuds
Issue: Earbuds not charging.
Solution: Ensure the charging case has power. Check the charging cable and adapter. Clean the charging contacts on both earbuds and the case with a dry cotton swab. If still not charging, contact support.
Issue: One earbud not working.
Solution:
1. Ensure both earbuds are charged.
2. Try resetting the earbuds (refer to the product manual for instructions).
3. Re-pair the earbuds with your device.
4. If the issue persists, it might be a hardware problem.
Issue: Low volume or distorted sound.
Solution:
1. Check the volume level on your connected device.
2. Ensure there's no obstruction in the earbud's speaker grill.
3. Try playing audio from a different source to rule out the media file.
4. Clean the earbuds.
"""
}
# Write the content to files
for filename, content in doc_contents.items():
filepath = os.path.join(DOCS_DIR, filename)
with open(filepath, "w") as f:
f.write(content.strip()) # .strip() removes leading/trailing whitespace for cleaner files
print(f"Created: {filepath}")
Ответ на запрос пользователя (фазы поиска и увеличения)
Когда клиент задает вопрос: «Как мне сбросить продукт XYZ?», Вот что происходит:
- Chunking:Мы разбиваем эти большие документы на более мелкие, управляемые «куски» (например, параграфы, разделы). Чтобы получить определенные части информации.
- Внедрение:Каждый из этих текстовых кусков преобразуется в численное представление, называемое «встраивание» (вектор чисел), используя «модель встраивания». Подумайте о встраивании, чтобы захватитьзначениетекста в математической форме. Текстовые кусочки с похожими значениями будут иметь встраиваемые встроены друг на друга в многомерном пространстве.
- Векторная база данных:Эти встраивания хранятся в специализированной базе данных, называемой «векторной базой данных» (например, Pinecone, Weaviate или даже простой в памяти в малой масштабе). Эта база данных оптимизирована для быстрого поиска сходства.
- Запрос внедрения:Вопрос клиента также преобразуется в внедрение с использованиемтакой жеВстроенная модель, используемая для нашей базы знаний.
- Поиск сходства:Система выполняет «поиск сходства» в векторной базе данных, чтобы найти кусочки документа продукта, встроенные по внедрению, внедрение запроса клиента. Эффективно получение наиболее важных фрагментов информации из нашей базы знаний о продуктах.
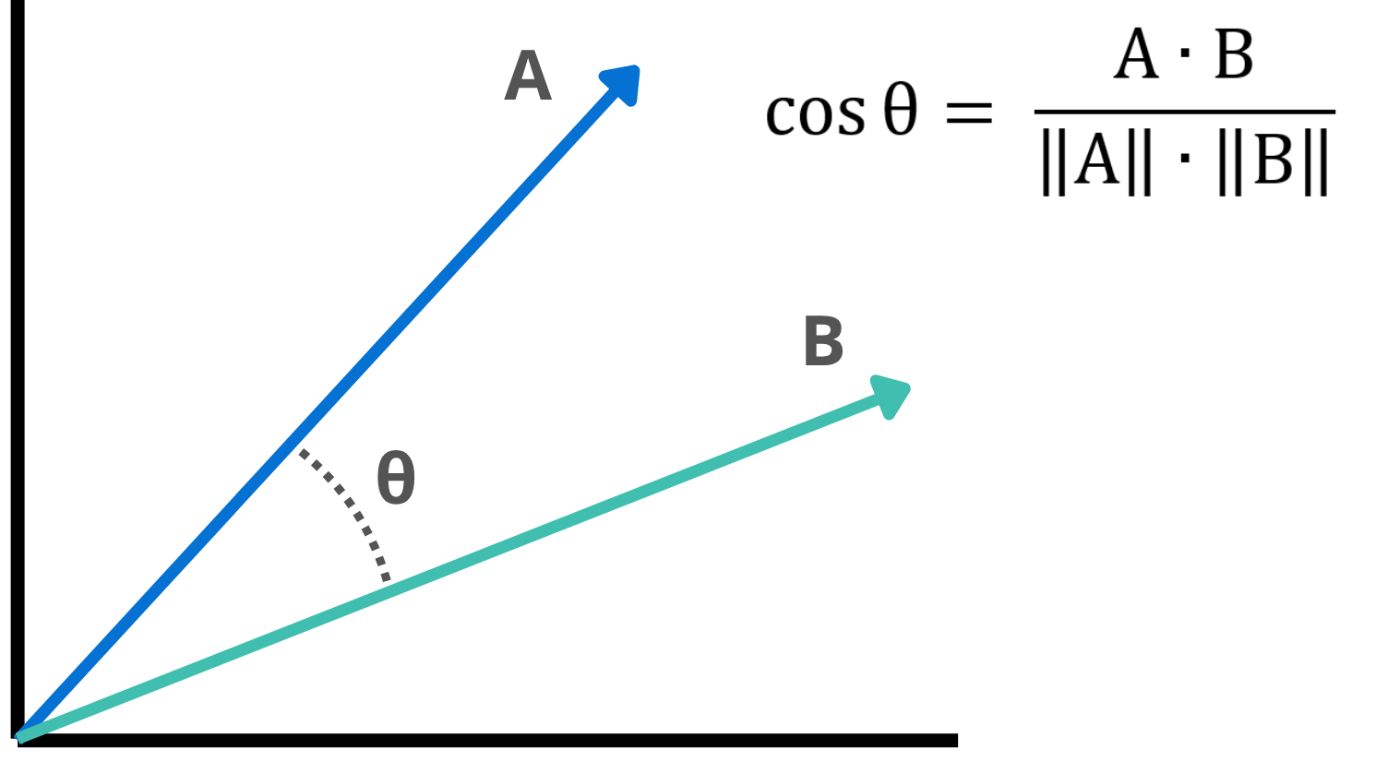
Когда мы говорим: «Встроения близки», мы по сути говорим об измерении расстояния или сходства между этими векторами. Стандартный метод для этого - использовать сходство косинуса.
import numpy as np
from typing import List, Dict, Tuple
import glob # To find our created text files
class DocumentChunk:
"""Represents a chunk of text from our knowledge base."""
def __init__(self, text: str, source_file: str, chunk_id: str):
self.text = text
self.source_file = source_file
self.chunk_id = chunk_id
self.embedding: List[float] = [] # To be filled by the embedding model
def __repr__(self):
return f"DocumentChunk(id='{self.chunk_id}', source='{self.source_file}', text='{self.text[:50]}...')"
class EmbeddingModel:
"""
A conceptual embedding model.
In a real scenario, this would use a pre-trained model to convert text into meaningful vectors.
For simplicity, we're generating dummy embeddings based on a hash.
"""
def get_embedding(self, text: str) -> List[float]:
# Generating a very simple, non-semantic dummy embedding
# In a real application, use a library like 'sentence-transformers' or a model API
np.random.seed(hash(text) % (2**32 - 1)) # Seed for reproducibility based on text
return np.random.rand(768).tolist() # Return a list of 768 random floats
def cosine_similarity(self, vec1: List[float], vec2: List[float]) -> float:
"""Calculates cosine similarity between two vectors."""
vec1_np = np.array(vec1)
vec2_np = np.array(vec2)
dot_product = np.dot(vec1_np, vec2_np)
norm_vec1 = np.linalg.norm(vec1_np)
norm_vec2 = np.linalg.norm(vec2_np)
if norm_vec1 == 0 or norm_vec2 == 0:
return 0.0 # Avoid division by zero
return dot_product / (norm_vec1 * norm_vec2)
class VectorDatabase:
"""
A highly simplified in-memory vector database.
In a real system, this would be a dedicated vector database for efficient large-scale search.
"""
def __init__(self, embedding_model: EmbeddingModel):
self.store: Dict[str, DocumentChunk] = {}
self.embedding_model = embedding_model
self._chunk_counter = 0
def add_document(self, filepath: str):
"""Reads a file, chunks its content, and adds to the store with embeddings."""
with open(filepath, 'r') as f:
full_text = f.read()
# Simple chunking: split by paragraphs or double newlines
# For more advanced chunking, consider libraries like LangChain's TextSplitter
chunks = [c.strip() for c in full_text.split('\n\n') if c.strip()]
print(f"Processing {len(chunks)} chunks from {filepath}...")
for i, text in enumerate(chunks):
chunk_id = f"{os.path.basename(filepath).replace('.', '_')}_chunk_{self._chunk_counter}"
doc_chunk = DocumentChunk(text=text, source_file=filepath, chunk_id=chunk_id)
doc_chunk.embedding = self.embedding_model.get_embedding(text)
self.store[chunk_id] = doc_chunk
self._chunk_counter += 1
print(f"Finished processing {filepath}.")
def find_similar_chunks(self, query_embedding: List[float], top_k: int = 3) -> List[Tuple[DocumentChunk, float]]:
"""
Finds the top_k most similar document chunks to the query embedding.
Returns a list of (DocumentChunk, similarity_score) tuples.
"""
if not self.store:
return []
similarities = []
for chunk_id, chunk in self.store.items():
if chunk.embedding:
score = self.embedding_model.cosine_similarity(query_embedding, chunk.embedding)
similarities.append((chunk, score))
# Sort by similarity score in descending order
similarities.sort(key=lambda x: x[1], reverse=True)
return similarities[:top_k]
def simulated_llm(prompt: str) -> str:
"""
A simplified Large Language Model (LLM) stand-in.
In a real application, this would be an API call to a powerful LLM.
It tries to give a slightly more "aware" response if relevant keywords are in the prompt context.
"""
prompt_lower = prompt.lower()
if "reset" in prompt_lower and "xyz wireless earbuds" in prompt_lower and "button" in prompt_lower:
return "Based on the provided information, to reset your XYZ Wireless Earbuds, place both earbuds in the charging case, then press and hold the button on the charging case for 15 seconds until the LED light blinks red three times. After that, close the case and reopen it."
elif "warranty" in prompt_lower and "xyz wireless earbuds" in prompt_lower and "1-year" in prompt_lower:
return "The XYZ Wireless Earbuds come with a 1-year limited warranty from the date of purchase. Remember to keep your proof of purchase for any warranty claims."
elif "pairing" in prompt_lower and "bluetooth" in prompt_lower:
return "According to the manual, to pair your XYZ Earbuds, open the charging case to enter pairing mode. Then, go to your device's Bluetooth settings and select 'XYZ Earbuds'."
elif "waterproof" in prompt_lower or "submersion" in prompt_lower:
return "The XYZ Earbuds are splash-resistant (IPX4 rating) and can handle light rain or sweat. However, they are NOT designed for submersion in water."
elif "low volume" in prompt_lower or "distorted sound" in prompt_lower:
return "If you're experiencing low volume or distorted sound, check your device's volume, ensure no obstruction in the earbud's speaker grill, and try playing audio from a different source. Cleaning the earbuds might also help."
else:
return "I couldn't find specific information about that in my current knowledge base. Could you please rephrase your question or provide more details? You can also visit our website for comprehensive support."
Теперь давайте загрузим контент из наших моделируемых текстовых файлов в нашиVectorDatabaseПолем Каждый соответствующий раздел будет превращен вDocumentChunkраздел и встроен.
# Initialize the embedding model and vector database
embedding_model = EmbeddingModel()
vector_db = VectorDatabase(embedding_model)
# Find all text files in our DOCS_DIR
document_files = glob.glob(os.path.join(DOCS_DIR, "*.txt"))
# Add each document to our vector database
if document_files:
for doc_file in document_files:
vector_db.add_document(doc_file)
print(f"\nKnowledge base built with {len(vector_db.store)} chunks from {len(document_files)} files.")
else:
print("No document files found. Please ensure files were created correctly.")
Генерирование ответа (фаза генерации)
На этапе поколения происходит:
- Обработка LLM:LLM теперь получает вопрос клиентавместе сВысокий актуальный контекст из наших документов продукта.
- Заземленный ответ:С помощью этой конкретной информации LLM может генерировать точный, точный и полезный ответ, непосредственно ссылаясь на руководство по продукту или FAQ. Это «обосновано» в наших проприетарных данных.
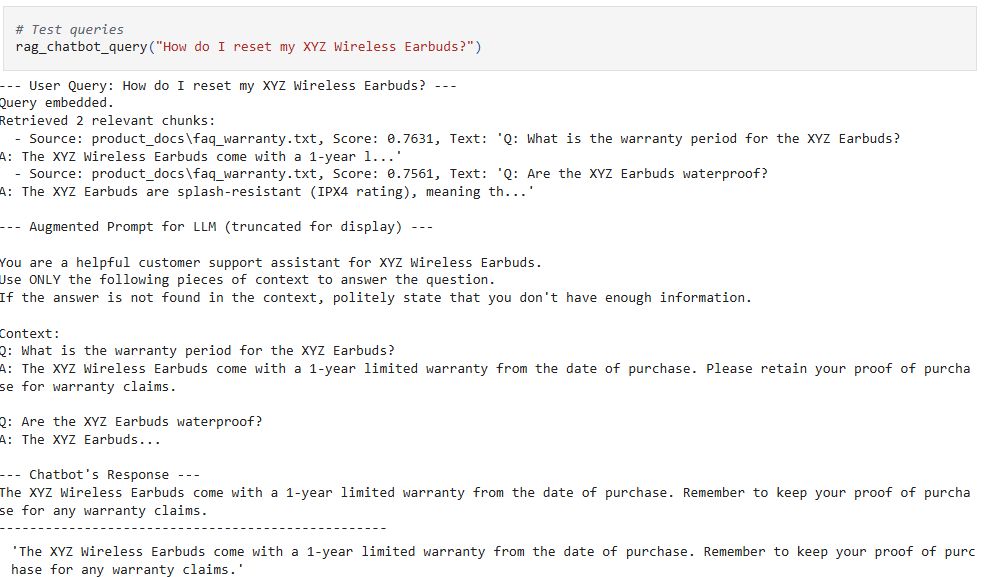
def rag_chatbot_query(user_query: str, top_k_chunks: int = 2):
"""
Main RAG chatbot function.
Processes a user query by retrieving relevant context and augmenting an LLM prompt.
"""
print(f"\n--- User Query: {user_query} ---")
# 1. Embed the user's query
query_embedding = embedding_model.get_embedding(user_query)
print("Query embedded.")
# 2. Retrieve relevant chunks from the vector database
# Get (chunk, similarity_score) tuples
relevant_chunks_with_scores = vector_db.find_similar_chunks(query_embedding, top_k=top_k_chunks)
if not relevant_chunks_with_scores:
print("No relevant chunks found.")
context = "No specific context found in the knowledge base."
else:
print(f"Retrieved {len(relevant_chunks_with_scores)} relevant chunks:")
for chunk, score in relevant_chunks_with_scores:
print(f" - Source: {chunk.source_file}, Score: {score:.4f}, Text: '{chunk.text[:100]}...'")
# 3. Augment the prompt with retrieved context
context = "\n\n".join([chunk.text for chunk, _ in relevant_chunks_with_scores])
# Construct the augmented prompt for the LLM
augmented_prompt = f"""
You are a helpful customer support assistant for XYZ Wireless Earbuds.
Use ONLY the following pieces of context to answer the question.
If the answer is not found in the context, politely state that you don't have enough information.
Context:
{context}
Question: {user_query}
Answer:
"""
print("\n--- Augmented Prompt for LLM (truncated for display) ---")
print(augmented_prompt[:500] + "..." if len(augmented_prompt) > 500 else augmented_prompt)
# 4. Generate the response using the LLM
response = simulated_llm(augmented_prompt)
print("\n--- Chatbot's Response ---")
print(response)
print("-" * 50)
return response
Преимущества тряпки
RAG усиливает методологии только LLM, добавляя дополнительный специфический контекст в языковую модель, а также предлагая преимущества по сравнению с системами, только для поиска.
- Точность и фактическая деятельность:Уменьшает «галлюцинации», заземляя ответы в подтверждаемых данных.
- Приложение RAG может включать в себя запатентованные данные.
- Сообщенная информация:Можно включить новые данные, просто обновив базу знаний, не переподшив весь LLM.
- Снижение затрат на обучение:Не нужно настраивать массивные LLM для определенных доменов.
- Прозрачность:Это потенциально позволяет ссылаться на источники, так как извлеченные куски служат основой для ответа.
По сути, RAG повышает интеллект и надежность LLMS для задач, специфичных для домена, и открывает широкий спектр возможностей, от передовой поддержки клиентов до персонализированных научных сотрудников и внутренних систем управления знаниями.
Преимущества тряпки для менеджеров по продуктам
Как менеджер продуктов, вы постоянно ищете способы улучшения пользовательского опыта, оптимизации внутренних операций и принятия решений, управляемых данными. Вот гдеПоиск дополненного поколения (Rag)Сияет, молча трансформируя то, как вы взаимодействуете с информацией, и, в конечном счете, как вы создаете и поддерживаете свой продукт.
Рассмотрим пример нашего магазина электронной коммерции. Как менеджер по продукту, вы очень обеспокоены удовлетворенностью клиентов (оценки CSAT) и эффективностью операций поддержки (центры затрат). Чат-бот с тряпкой может значительно преобразовать эти аспекты:
- Улучшение того, как мы помогаем нашим клиентам, давая быстрые и точные ответы, делает их опыт более приятным. Все получают выгоду, когда мы делаем вещи проще и более дружелюбны!
- Большинство запросов клиентов могут быть автоматизированы, что позволяет команде поддержки сосредоточиться на более сложных проблемах. Повышение эффективности эксплуатации и снижение затрат.
- Нет необходимости ждать переподготовки LLM, когда изменяются функции; Документация может быть обновлена, отображается, а система RAG обновляется автоматически.
- Понимание, управляемые данными: Вопросы журнала и поиск документов показывают, где клиенты борются, указывая на улучшения документации или новые функции.
- Внутреннее управление знаниями: тряпка не только для внешних чат -ботов. Представьте себе внутреннюю тряпную систему, которая позволяет вашей команде продаж быстро находить ответы на сравнение продуктов, позволяет маркетингу проверять претензии и облегчает более быстрый доступ к внутренней документации.
- Конкурентный анализ и исследование рынка: используйте RAG с внешними данными (публичные отчеты, веб -сайты конкурентов) для быстрого синтеза понимания рыночных тенденций или конкурентов, поддерживая стратегию вашей продукции.
По сути, Rag превращает LLM от поставщиков общих знаний в экспертов, специфичных для домена, непосредственно обращаясь к многим болевым точкам менеджера продукта. Используя ваши проприетарные данные, Rag позволяет вам предоставить более точный, отзывчивый и интеллектуальный опыт продукта, облегчая вашу жизнь и ваш продукт более успешным.
Надеюсь, вам понравились мои размышления. Для дальнейшей ссылки на код, не стесняйтесь проверить мойGitHubПолем Если у вас есть какие -либо мысли или отзывы, я бы хотел услышать от вас. Счастливого кодирования!
Оригинал