
6 прорывных методов обучения для дистанционного зондирования
11 июня 2025 г.Таблица ссылок
- Аннотация и введение
- Фон
- Тип данных датчика дистанционного зондирования
- Clarkmark Demote Sensing Dataets для оценки моделей обучения
- Метрики оценки для нескольких ударов дистанционного зондирования
- Недавние методы обучения в дистанционном зондировании
- Обнаружение и сегментация объекта на основе нескольких выстрелов в дистанционном зондировании
- Обсуждения
- Численные эксперименты нескольких выстрелов в наборе данных на основе БПЛА
- Объяснимый ИИ (XAI) в дистанционном зондировании
- Выводы и будущие направления
- Благодарности, декларации и ссылки
6 недавних методов обучения в дистанционном зондировании
В области дистанционного зондирования пересечение с компьютерным зрением привлекло значительное внимание и исследовательский интерес, что свидетельствует о многочисленных работах, таких как те, которые предприняты [8] и [38], которые углубляются в различные рамки активного машинного обучения. Кроме того, тонкости гиперспектральной классификации изображений и современных разработок в области машинного обучения и методов компьютерного зрения изучаются [39]. Комплексный и исчерпывающий анализ алгоритмов глубокого обучения, используемых для обработки изображений дистанционного зондирования, при этом подробно описывает текущие практики и доступные ресурсы, предоставляется [40]. Кроме того, [8] представляет обзор подходов, основанных на трансформаторах, к дистанционному зондированию, с особым вниманием к визуализации с очень высоким разрешением, гиперспектральной и радиолокационной томографией. В этом обзоре наше конкретное внимание уделяется недавним прорывам в области нескольких выстрелов методов обучения для дистанционного зондирования. Мы стремимся провести углубленное исследование последствий таких достижений для классификации и понимания сцен на платформах сбора данных на основе спутников и на основе БПК. Включение объясняемого ИИ может помочь понять причины результатов классификации, обеспечивая большую прозрачность и уверенность в процессах принятия решений.
6.1.
В области дистанционного зондирования мало выстрела получило значительную поддержку, как показано во вводном разделе. В этом конкретном разделе мы сосредоточимся на методах, выдвинутых как для однородной, так и для многоамериканской классификации дистанционного зондирования в контексте платформ как спутниковых, так и на основе БПК. Стоит отметить, что, если не указано иное, все показатели оценки, используемые в рассмотренных исследованиях в этом разделе, охватывают OA, AA и κ.
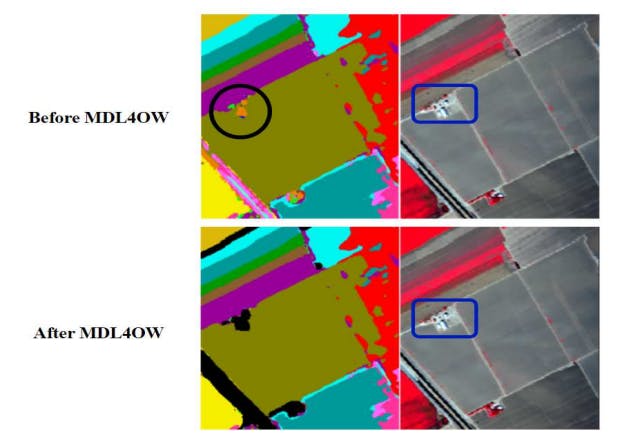
Модель MDL4OW, представленная [41], использует архитектуру глубокого обучения на основе глубокого обучения для классификации пяти неизвестных классов посредством обучения на девяти известных классах. Примечательно, что предложенная модель отходит от традиционных центриидных методов, вместо этого используя теорию экстремальных значений из статистической модели, как показано на рисунке 3. Кроме того, авторы представили новую метрику оценки, ошибку отображения, которая особенно чувствительна к дисбалансированным сценариям классификации, часто встречающейся в данных гиперпроизводственных определяющих изображений. Математическое выражение ошибки отображения для классов C приводится в 10 при условии ограничений, выраженных в 11 и 12.
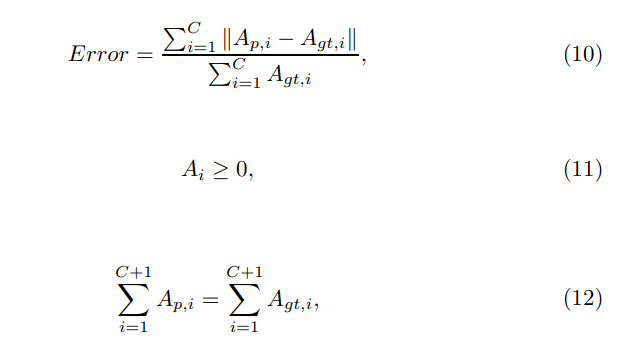
Математическое выражение 10 представляет ошибку отображения, где AP, я обозначает прогнозируемую область класса ITH и AGT, я обозначает соответствующую область земли. Здесь C представляет общее количество известных классов (как в случае их работы, где она равна 9), в то время как C + 1 относится к общему количеству неизвестных классов (которые в их работе составляют 5). Набор данных Pavia, набор данных Indian Pines и набор данных Valines Valinas - это наборы данных, которые оцениваются в их исследовании. Помимо ошибки отображения, метрика OpenSess [42] также рассматривается как эталон для их оценки, которая оценивает степень открытости для данного набора данных в классификации открытого мира, в дополнение к ОА и показателю Micro F1.
Уравнение 13 выясняет связь между открытой полосой и количеством данных обучения и тестирования, NTRAIN и NTEST, соответственно.
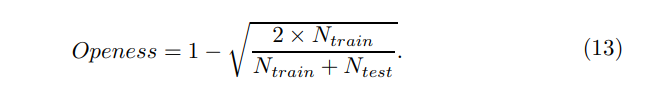
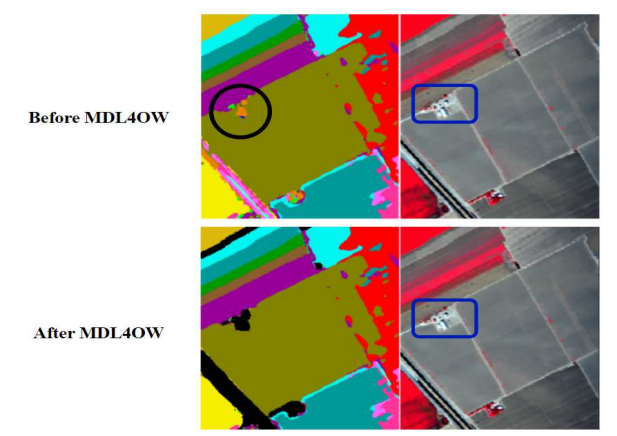
На рисунке 5 представлена иллюстрация того, как методология MDL4OW эффективно идентифицирует неизвестные классы, как показано с помощью примера изображения. Верхняя часть фигуры подчеркивает дорогу (обозначенную черным) и Дом (прилагаемый темно-голубой границей), оба из которых не могут быть назначены каким-либо известным классам, поскольку они не были представлены априори. Тем не менее, стандартная модель глубокого обучения по -прежнему потребует назначения им метки, поскольку она не была обучена распознавать эти конкретные этикетки. Напротив, подход MDL4OW (изображенный в нижней части рисунка) является искусным при выявлении и маркировке неизвестных классов (обозначенных черным), эффективно применяя предложенную схему.
Используя методы адаптивного подпространства и функциональных преобразований (SSFT) [43], направленные на улучшение разнообразия функций и минимизацию переживания. В частности, они включили трехмерную остаточную сеть локального канала для извлечения функций, и оценили свой алгоритм против SOTA, используя наборы данных Salinas, Pavia и Indian Pines. Чтобы сравнить с другими SOTA, они выполнили 5-выстрел, 10-выстрел, 15 выстрелов, 20 выстрелов и 25-х подход. В исследовании, проведенном [44], был принят псевдообогающий подход, чтобы увеличить процедуру извлечения признаков их сети с использованием ограниченных образцов, а также уменьшить переосмысление. Мягкая псевдо -метка была рассчитана с учетом евклидового расстояния между некалеванными образцами и другими агентами с каждым помеченным образцом, действующим в качестве эталона. Были предложены два подсчета, а именно 3D-CNN и SSRN (на основе RESNET), чтобы функционировать в качестве экстрактора признаков. Набор данных, используемый для оценки, состоял из Павии, индийских сосен и долины Салинас. Для сравнения с другими подходами SOTA был использован подход с 1 выстрелом, 3 выстрелом и 5 выстрелом. Результаты показали, что предложенная модель превзошла все существующие подходы SOTA во всех трех параметрах оценки.
Используя трехмерную остаточную сверточную сеть внимания блоков (R3CBAM), авторы [45] продемонстрировали, как эффективно изучать спектральные пространственные особенности более заметным образом с небольшими обучающими образцами. CBAM включен как сеть внимания. Используется мета-обучение, где используется набор евклидовых расстояний из тестового запроса из известных прототипов класса, а неизвестные запросы класса помечены как выбросы и расположены без установки порогового значения заранее. Оценка их подхода была выполнена на наборах данных индийских сосен, Павии, салиана и Хьюстона. Во время обучения их сети был сгенерирован набор запросов из шести базовых классов, выбранных, и набор поддержки был сформирован из образцов с использованием трех случайно выбранных классов запросов. Была проведена оценка производительности OSR с 1 выстрелом и 5 выстрелом и сравнивалась с методами SOTA. Как при оценках OSR с 1 выстрелом и 5 выстрелом, результаты показали, что предложенный метод превзошел методы SOTA.
Расширяясь на предыдущих работах, [46] предложил подход гетерогенного меньшего количества обучения (HFSL) для классификации дистанционного зондирования с несколькими образцами на класс. Метод первоначально учится на данных, случайным образом отобранным из набора данных Mini-Imagenet для получения передаваемых знаний, а затем разделение данных на наборы поддержки и запросов. Предполагается, что спектрально-пространственная модель обучения, которая извлекает спектральную информацию через 1D-математические операции и пространственную информацию через CNN с VGG16, предварительно обученными весами в первом уровне. Их подход к оценке включает в себя наборы данных Павия и Хьюстон, с 5 выстрелами оценки эффективности по сравнению с самыми современными методами. Опираясь на это, [47] добавляет дистилляцию знаний (KD) к подходу, что упрощает определение важных частей небольших выборок, даже с более мелкой сетью. Дополнительная передача знаний и тонкая настройка модели классификатора выполняются с оценкой на наборах данных Павии Университета и индийских Pines.
Используя Dirichlet-Net для извлечения функций, [48] предложил несколько выстрелов в многократно-задача, которая направлена на то, чтобы поддерживать точность классификации в нескольких областях. Ключевая концепция состоит в том, чтобы извлечь фундаментальные представления, которые являются общими для одного и того же типа объектов по доменам, с целью обхода требования к большему количеству меток с землей из целевой области. Набор данных Университета Павия использовался для оценки их подхода с стратегией оценки 5 выборки (то есть 5-выстрел). Результаты показали, что предложенный метод был способен точно классифицировать невидимые образцы целевого домена, демонстрируя эффективность подхода.
Авторы [49] предложили новую свертому графическому графическому графику (AWGCN) для нескольких выстрелов для количественной оценки и корреляции внутренних функций в гиперспектральных данных. За этим следует полуоттрагиваемое распространение метки метки узлов (функции) от поддержки к набору запросов через GCN, используя обученные веса графиков внимания. В отличие от других подходов, они не полагались на предварительно обученные веса на основе CNN в качестве экстракторов признаков, а вместо этого использовали подход на основе графика. Предложенный метод был оценен в наборе данных «Индийские сосны» с использованием 1-выстрела, 3-выстрел и 5-выстрел и на наборе данных Университета Павия с использованием 5-выстрела. Аналогичным образом, [50] предложил подход, основанный на графике, который использует информацию о спектральных и пространственных объектах для значительного снижения алгоритмического пространства и времени. Их подход оценивался в Павии Университет, Индийские Сосны и набор данных Кеннеди Космического центра с использованием подхода к оценке 30-летних на класс для обучения и подходов к оценке с 15 матчами для класса для проверки. Их результаты продемонстрировали повышенную точность по сравнению с другими современными методами, с повышением точности на наборе данных Университета Павия на 6,7% и увеличением набора данных индийских Pines на 5,2%. Кроме того, набор данных космического центра Кеннеди повысил точность на 7,1%, что делает их подход сильным претендентом на дальнейшие исследования. Это улучшение в точности указывает на то, что их подход более эффективен, чем другие методы, и может быть потенциальным решением для будущих приложений.
Предложенный метод [51], самоотвращение и индивидуальное обучение в отношении индивидуального обучения (SMA-FSL) использует 3D-сверточную сеть, внедряющую спектрально-пространственную экстракцию, в сочетании с модулем самостоятельного прихода для извлечения прототипов из каждого класса в наборе поддержки и модуля взаимного внимания, которые обновляют и используют эти категории с помощью набора категорий. Подчеркивается обучение на основе внимания, где важные особенности улучшаются, в то время как шумные особенности уменьшаются. Чтобы оценить эффективность их подхода, он оценивается на наборах данных Houston, Botswana [28], Chikusei [52] и Kennedy Space Center с использованием подходов с 1 выстрелом, 5 выстрелом и 15 выстрелами. Эти наборы данных выбираются для их разнообразного ассортимента местности и растительности, что позволяет провести всестороннюю оценку эффективности модели. Результаты оценки показывают, что подход эффективен во всех наборах данных, демонстрируя ее универсальность в разных средах.
Предложенная работа [53] представляет собой постепенный метод, основанный на обучении, который постоянно обновляет классификатор, используя несколько выстрелов, позволяя распознавать новые классы при сохранении знаний о предыдущих классах. Модуль экстрактора функций реализован с использованием 20-слойного Resnet, а инкрементное обучение класса с несколькими выстрелами (FSCIL) проводится через постоянно обновленный классификатор (CUC), который дополнительно усиливается путем включения механизма внимания для измерения сходства прототипа между каждым обучением и тестовым образцом. Набор данных Университета Павия использовался для оценки эффективности этого подхода с использованием 5-выстрела в стратегии оценки. Полученные результаты показали, что предложенный FSCIL с CUC и механизмом внимания достигли превосходной производительности по сравнению с базовым методом. Кроме того, было также отмечено, что производительность улучшилась с увеличением количества выстрелов.
В большинстве предыдущих работ использовались архитектуры на основе CNN для нескольких выстрелов в классификации гиперспектральной изображения. Тем не менее, CNN могут бороться с моделированием долгосрочных зависимостей в спектральных пространственных данных, когда обучающие образцы мало. Это мотивировало недавний интерес к архитектурам трансформатора в качестве альтернативы.
В заметном вкладе Shi et al. [54] рассматривали проблему деградации производительности, наблюдаемой в методах классификации гиперспектральной изображения, когда для обучения доступно только ограниченное количество меченых образцов. Они предложили унифицированную структуру с энкодером трансформатора и сверточными блоками для улучшения извлечения признаков без необходимости дополнительных данных. Трансформерный кодер предоставляет глобальные рецептивные поля для захвата долгосрочных зависимостей, в то время как сверточные блоки моделируют локальные отношения. Их метод достиг современных результатов по нескольким выстрелам гиперспектральных задач с использованием публичных наборов данных, демонстрируя потенциал трансформаторов для продвижения нескольких выстрелов в этой области.
Huang et al. [55] также признали ограничения моделей на основе CNN для небольшого количества гиперспектральной классификации изображений. Они подчеркнули неотъемлемая сложность CNN в эффективном захвате долгосрочных пространственных спектральных зависимостей, особенно в сценариях с ограниченными данными обучения. Они предложили улучшенный пространственный спектральный трансформатор (HFC-SST), чтобы преодолеть это, вдохновленные сильными возможностями трансформаторов на дальние отношения. HFC-SST генерирует локальные пространственные спектральные последовательности в качестве входных данных на основе анализа корреляции между спектральными полосами и соседними пикселями. Затем сеть, основанная на трансформаторах, извлекает дискриминационные пространственные спектральные особенности из этой последовательности, используя только несколько меченных образцов. Эксперименты по нескольким наборам данных продемонстрировали, что HFC-SST превосходит CNNS и предыдущие методы обучения, эффективно моделируя локальные долгосрочные зависимости в ограниченных учебных данных. Это также подчеркивает потенциал трансформаторов для продвижения нескольких выстрелов гиперспектральной классификации посредством надежного обучения пространственной спектральной функции.
Работа Wang et al. [56] также исследует междоменное обучение с небольшим выстрелом для классификации гиперспектральной изображения, где маркировки с мечеными образцами в целевом домене мало. Они предлагают подход на основе немногих выстрелов на основе трансформаторов (CTFSL) в рамках мета-обучения. Большинство предыдущих междоменных методов, которые полагаются на CNN, для извлечения статистических особенностей, которые отражают только локальную пространственную информацию. Чтобы решить эту проблему, CTFSL включает в себя сеть сверточных трансформаторов для извлечения как локальных, так и глобальных функций. Выравнивание домена отображает источники и целевые домены в одном и том же пространстве, в то время как дискриминатор уменьшает сдвиг домена и различает происхождение функций. Комбинируя несколько выстрелов по доменам, извлечения функций на основе трансформаторов и выравнивания доменов, их метод превосходит современные методы на наборах данных об публичных гиперспектральных данных. Это демонстрирует потенциал трансформаторов и стратегий обучения междоменного обучения, чтобы продвигать несколько выстрелов гиперспектральной классификации с ограниченными меченными данными.
Недавно Ran et al. [57] предложили новую структуру глубокого трансформатора и нескольких выстрелов (DTFSL) для гиперспектральной классификации изображений, которая направлена на преодоление ограничений CNNS. DTFSL включает в себя пространственное внимание и спектральные модули запроса, чтобы захватить дальние зависимости между нелокальными пространственными образцами. Это помогает уменьшить неопределенность и лучше представлять основные спектральные пространственные функции с ограниченными учебными данными. Сеть обучена с использованием эпизодов и стратегий, основанных на задачах для изучения адаптивного метрического пространства для нескольких выстрелов. Адаптация домена также интегрирована для выравнивания распределений и уменьшения изменений между доменами. Эксперименты по трем публичным наборам данных HSI продемонстрировали, что подход DTFSL на основе трансформаторов превосходит современные методы, эффективно моделируя взаимосвязь между нелокальными пространственными образцами в нескольких выстрелах. Это указывает на то, что трансформаторы могут быть многообещающей альтернативой CNN для нескольких выстрелов гиперспектральной классификации.
В другой работе [58] представляет архитектуру на основе Vision Transformer (VIT) для FSL, которая использует обучение обратной связи. Сеть трансформаторов нескольких выстрелов (FFTN), разработанная [58], объединяет пространственное и спектральное внимание извлеченных признаков, изученных компонентом трансформатора. Внедряя XAI, процесс принятия решений модели может быть сделан более прозрачным и интерпретируемым, тем самым повышая ее надежность и снижая риск предубеждений. Кроме того, сеть включает в себя мета-обучение с усиленным обучением обратной связи на исходном наборе в качестве первого шага к улучшению способности сети идентифицировать неправильно классифицированные образцы посредством подкрепления. Вторым этапом является обучение на целевое обучение с обучением трансдуктивной обратной связи по целевому образцу, чтобы узнать распределение немеченых образцов. Этот двухэтапный процесс помогает сети адаптироваться к целевой области, тем самым повышая ее точность и снижая риск переживания.
В таблице 3 представлен обзор некоторых из существующих методов для нескольких подходов в классификации гиперспектральных изображений. Он перечисляет используемый набор данных и метрики, а также тип подхода экстрактора функций для каждого метода
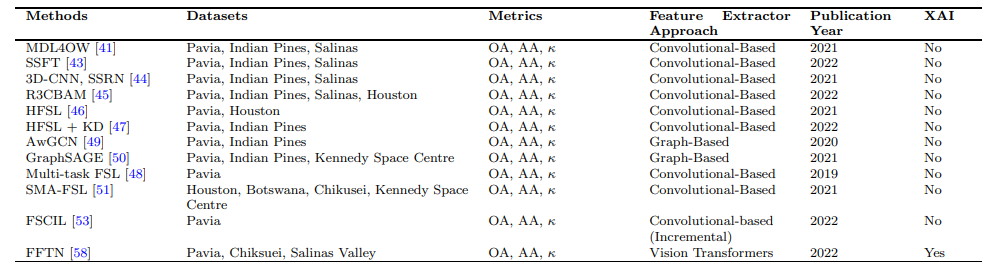
и год публикации. Добавление методов XAI может повысить прозрачность и интерпретацию этих методов.
Метод оценки из 5 выстрелов в основном используется для измерения того, насколько хорошо предложенные методы работают на наборах данных Чикусея, Салинас-Вэлли и Павии. В таблице 3 приведен обзор обсуждаемых методов, включая наборы данных и показатели оценки, использованные методы обучения, и год, когда был опубликован статья. Из работ, о которых говорилось, ясно, что наборы данных Pavia, Indian Pines и Salinas Valley чаще всего используются для сравнения алгоритмов.
В таблице 3 большинство из нескольких выстрелов для классификации гиперспектральных изображений не включали XAI для лучшей интерпретации. Тем не менее, добавление методов XAI может повысить прозрачность и дать представление о процессе принятия решений моделями. Одним из способов включения XAI является использование методов визуализации для выделения функций или областей изображения, которые способствуют прогнозу модели. Другой подход заключается в использовании карт значимости для определения наиболее важных областей входного изображения, которые влияют на решение модели. Кроме того, методы-модельные методы, такие как извести или соревнования, могут дать представление о процессе принятия решений моделями. В целом, включение методов XAI в несколько выстрелов для классификации гиперспектральной изображения может улучшить прозрачность и интерпретацию моделей и облегчить их принятие в реальных приложениях.
6.2 несколько выстрелов в классификации изображений VHR
Все исследования в этом разделе используют метрику ОА, если не указано иное. [59] предлагает новую схему с нулевым выстрелом для классификации сцен (ZSSC), основанной на визуальном сходстве изображений из того же класса. В их работе используется набор данных UC Merced для оценки, где ряд классов были случайным образом выбраны в качестве наблюдаемых классов, в то время как остальные были невидимыми классами. Кроме того, авторы включают набор данных RSSCN7 [60] и базу данных изображений на основе спутников VHR, состоящей из экземпляров как наблюдаемых, так и неизвестных классов в немеченых формате. Чтобы решить эту проблему, авторы принимают модель Word2VEC [61] для представления каждого класса в качестве семантического вектора и используют модель на основе графика соседей (KNN), чтобы реализовать разреженное обучение для уточнения этикетки. Уточнение также помогает денузировать любую шумную метку во время схемы классификации с нулевым выстрелом. Их предлагаемая модель достигает значительного повышения производительности по сравнению с существующими моделями обучения SOTA Zero-Shot с линейной вычислительной сложностью. Кроме того, предложенная модель может обрабатывать большое количество классов с минимальными требованиями к памяти. Некоторые из новейших попыток использовать несколько выстрелов и данные на основе БПЛА были выполнены [62, 63].
Работа, представленная [64], предложила иерархическую прототипическую сеть (HPN) в качестве нового подхода для нескольких выстрелов, который оценивается в наборе данных Resisc45. Модель HPN предназначена для проведения анализа агрегированной информации на высоком уровне на изображении, за которой следует агрегированная информационная вычисление и прогнозирование с точным уровнем с использованием прототипов, связанных с каждым уровнем иерархии, как описано в (4). Протокол оценки включает в себя 5-сетевой подход к 1-выстрелу и 5-й 5-выстрелу в рамках стандартной структуры мета-обучения. В предлагаемом подходе модель Resnet-12 служит основой для первой стадии извлечения признаков. Извлеченные функции затем пропускаются через линейный слой, чтобы получить окончательное представление признаков. Это представление функции используется для задачи классификации на втором этапе.
В попытке увеличить производительность нескольких выстрелов, специфичных для задачи контрастного обучения (TSC), [65] ввел модуль самосоглаживания и взаимопонимания (SMAM), который изучает корреляции признаков с целью уменьшения любого фонового помех. Принятие контрастной стратегии обучения облегчает сочетание данных с использованием оригинальных изображений с разнообразных точек зрения. В конечном счете, вышеупомянутый подход расширяет потенциальность для различения функций изображения внутри класса и между классом. Наборы данных NWPU-RESISC45, WHU-RS19 и UC Merced были использованы для их алгоритмической оценки, которая включала 5-часовую и 5-сильную 5-выстрел, которая была изучена и сравнивалась. Кроме того, [66] ввел подход с множественным вниманием, который одновременно фокусируется на глобальной и локальной шкале функций как часть их многоаттестационной дистанции Deep Earth Mover (MAEMD), предложенной сетью. Местное внимание направлено на захват значительных и тонких локальных особенностей, подавляя другие, тем самым улучшая производительность репрезентативного обучения и смягчение небольших межклассных и больших внутриклассовых различий. Их подход оценивался на наборах данных UC-MERCED, помощи и оптимального 31 [67] с 1-выстрелом, 5-сильным 5-выстрелом и 10-выстрелом. В качестве доказательства успеха локальной стратегии внимания, результаты показали, что модель достигла современной производительности во всех наборах данных.
Еще одна иллюстрация модели, основанной на внимании, представлена [68] с внедрением сети выбора функций самостоятельного приспособления (Saffnet). Эта модель направлена на интеграцию функций по нескольким масштабам с использованием модуля самопричастования, аналогичным моделям сети пространственной пирамиды. Модуль «Выбор функций» (SAFS) используется для лучшего сопоставления функций из набора запросов с плавными функциями в наборе поддержки, определенного классом. Экспериментальный анализ был проведен на наборах данных UC-MERCED, RESISC45 и помощи с использованием подхода к оценке классификации с 1 выстрелом и 5 выстрелом. Результаты показали, что SAFS смог повысить производительность базовой модели для всех наборов данных, с наибольшим улучшением, наблюдаемым в наборе данных помощи.
Включая энкодер функции для изучения встроенных функций входных изображений в качестве шага предварительного обучения, [69] предложил адаптивную задачу сеть встраивания (TAE-NET). Чтобы выбрать наиболее информативные встроенные функции во время учебной задачи адаптивно, используется модуль адаптивного внимания, адаптивное, адаптируемое на задачу. Используя только ограниченные образцы поддержки, прогноз выполняется по запросу мета-обученной сетью. Для их алгоритмической оценки они использовали набор данных NWPU-RESISC45, WHU-RS19 и UC Merced. Для сравнения был реализован 5-часовый и 5-бочный 5-выстрел. Результаты были оценены на основе показателей точности, точности, отзывов и показателей F1. Кроме того, модели сравнивались с точки зрения их времени обучения и использования памяти.
Исследование, проведенное [70], направлено на получение нескольких выстрелов в глубоких экономических сетях. Глубокая экономическая сеть включает в себя двухэтапный процесс упрощения для сокращения параметров обучения и вычислительных затрат в глубоких нейронных сетях. Сокращение избыточности при входном изображении, каналах и пространственных особенностях в глубоких слоях достигается. Кроме того, знание учителей используется для улучшения классификации с ограниченными образцами. Последний блок в модели включает в себя глубинные и точечные совет, которые эффективно изучают взаимодействие по перекрестному каналу и повышают вычислительную эффективность. Алгоритмическая оценка модели проводится на трех наборах данных, а именно в UC-MERCED, RESISC45 и RSD46-WHU. Оценка проводится с использованием 1-выстрела и 5-выстрела в RESISC45 и RSD46-WHU, а в наборе данных UC-MERC реализуется дополнительная 10-каштальная оценка. Модель показывает многообещающую производительность во всех наборах данных, причем самая высокая точность получает 10 выстрелов.
Внедрение дискриминационного обучения сети адаптивной совпадения (DLA-MatchNet) для нескольких выстрелов по [71] включало механизм внимания в канале и пространственные домены для определения различных областей признаков в изображениях путем изучения их межканальных и межпространственных отношений. Чтобы решить проблемы, связанные с большими различиями внутриклассов и межклассовым сходством, дискриминационные особенности как наборов поддержки, так и запросов были объединены, и наиболее важные пары выборок были адаптивно отобраны сочетания, который проявлялся в качестве многослойного восприятия. Наборы данных UC-MERCED, RESISC45 и WHU-RS19 были использованы для современной оценки (SOTA), с использованием 5-канального 1-выстрела и 5 выстрела для всех наборов данных. Результаты подтвердили превосходную точность предложенного метода над SOTA, доказывая его полезность для поиска изображения дистанционного зондирования.
Методы на основе графиков также использовались в домене с очень высоким разрешением (VHR) для нескольких выстрелов. В связи с этим [72] предложил многомасштабный подход функций на основе графиков (MGFF), который включает в себя модель конструкции функций, которая преобразует типичные функции на основе пикселей в функции на основе графиков. Впоследствии модель слияния функций объединяет функции графика в нескольких шкалах, что повышает различительную способность модели посредством интеграции основной полученной информации о функциях и, тем самым, улучшая возможности классификации с небольшим выстрелом. Авторы провели алгоритмическую оценку на наборах данных RESISC45 и WHU-RS19, используя 5-часовой 1-выстрел и 5-часовой 5-выстрел. Кроме того, [73] предложил график, внедряющую сеть гладкости (GES-NET), которая реализует встраиваемое сглаживание для упорядочения встроенных функций. Это не только эффективно извлекает отношения с функциями более высокого порядка, но и вводит реляционное представление на уровне задач, которое отражает графические отношения между узлами на уровне всей задачи, тем самым усиливая отношения узлов и функции проницательных возможностей сети. Работа оценивается на наборах данных Resisc45, WHU-RS19 и UC Merced с использованием 5-часовых 1-выстрел и 5-выстрелов. Эпизодическое обучение было принято, где каждый эпизод относится к задаче и состоит из n единообразных категорий без замены, а также набора запросов и поддержки. Набор поддержки содержит k образцов из каждой из N -категорий, а набор запросов содержит единую выборку из каждой из N -категорий. Образцы в наборах запросов и поддержки выбираются из более крупного пула доступных образцов случайным образом, гарантируя, что каждый эпизод является уникальным.
Несколько выстрелов для классификации изображений VHR могут извлечь большую пользу от применения методов XAI, таких как объяснимые нейронные сети графика и механизмы внимания. Прозрачность, подотчетность, обнаружение смещения и проблемы справедливости могут быть улучшены с помощью XGNN, поскольку они проливают свет на процесс принятия решений модели. Чтобы сделать решения модели более понятными и прозрачными, механизмы внимания могут сосредоточиться на ключевых особенностях и узлах на графике. В принципе, эти методы могут сделать модели на основе нескольких выстрелов на основе графиков более надежными и простыми для понимания.
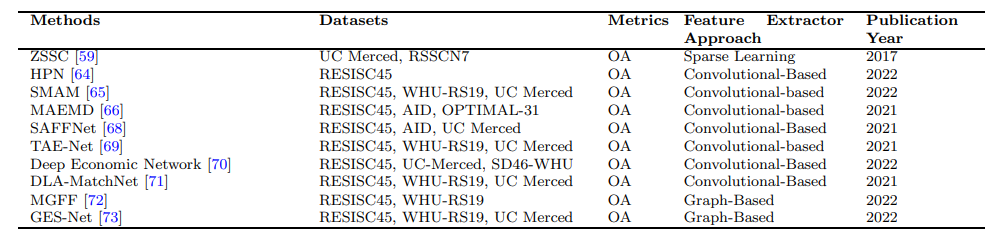
В таблице 4 представлен аналогичный формат до таблицы 3, изображая всестороннюю резюме вышеупомянутых методов в домене классификации с очень высоким разрешением (VHR). Можно наблюдать, что набор данных Resisc45, UC-MERCED и WHU-RS19 являются одними из наиболее часто используемых для алгоритмического сравнения, как видно в подмножестве существующих работ.
Кроме того, большинство подходов, представленных в таблице 4, включают механизмы внимания и методы на основе графиков для нескольких выстрелов классификации VHR. Подход MGFF, представленный [72], является примером метода, основанного на графике, в то время как DLA-Matchnet, представленный [71], является примером подхода, который использует механизмы внимания. Точно так же GES-Net, представленная [73], также использует методы на основе графиков в своем подходе. Эти методы направлены на то, чтобы извлечь более актуальные и информативные функции из входных изображений, которые могут повысить производительность систем классификации нескольких выстрелов.
6.3 несколько выстрелов в классификации изображений SAR
SAR (радар-синтетический апертуру) является технологией дистанционного зондирования для захвата изображений высокого разрешения поверхности Земли независимо от погодных условий, что делает его ценным инструментом в различных приложениях, таких как сельское хозяйство, лесное хозяйство и управление землепользой. Тем не менее, доступность данных на основе SAR часто ограничена по сравнению с гиперспектральными или VHR данных, в основном из-за высокой стоимости датчиков SAR и сложности обработки данных SAR. В результате традиционные подходы классификации для данных SAR часто оспариваются недостаточными данными обучения и высокой вариабельности внутри класса, что приводит к насущной потребности в разработке нескольких выстрел методов обучения, которые могут эффективно решать эти проблемы. Таким образом, обзор новых методов обучения в области классификации на основе SAR очень желателен для продвижения современного и обеспечения более точной и эффективной классификации данных SAR.
Интеграция методов XAI, таких как объяснимые нейронные сети графиков (XGNN) и механизмы внимания, может значительно улучшить предложенную методику обучения в нескольких выстрелах для классификации изображений SAR [74]. В этом новом подходе используется модуль внимания без подключения для выборочной передачи общих функций между SAR и электрооптическими (EO) изображением доменов, снижая зависимость от дополнительных образцов SAR, которые могут быть невозможны в определенных сценариях. Используя XGNN, авторы могут дать представление о процессе принятия решений, повышении прозрачности и подотчетности, что особенно важно для классификации изображений SAR из-за ограниченного доступа к данным и высоким затратам на приобретение. Механизм внимания может выделять соответствующие особенности и узлы на графике, улучшая интерпретацию и прозрачность модели, а также, в конечном счете, ее производительность и надежность. Кроме того, авторы внедрили байесовскую сверточную нейронную сеть для обновления только соответствующих параметров и отказаться от тех, кто имеет высокую неопределенность. Оценка проводилась на трех наборах данных EO, которые включали корабли, самолеты и автомобили, с изображениями SAR, полученными из [75], [76] и MSTAR. Значение точности классификации (OA) использовалось в качестве метрики производительности, причем 10-боковой подход K-STEC достигал ОА приблизительно 70%, что превзошло другие подходы. В целом, включение методов XAI может потенциально повысить производительность и надежность предлагаемой методики обучения с несколькими выстрелами для классификации изображений SAR.
В стремлении к эффективной классификации с небольшим выстрелом [77] предложил модуль вставки в ручной работы (HCFIM), который сочетает в себе изученные особенности CNN с функциями ручной работы с помощью подхода с взвешенным конкатенированием для агрегации более априорных знаний. Их многомасштабный модуль слияния функций (MSFFM) используется для агрегирования информации из разных слоев и масштабов, что помогает более легко отличить образцы целевых из того же класса. Комбинация MSFFM и HCFIM формирует их предлагаемую многофункциональную сеть слияния (MFFN). Чтобы решить проблему высокого сходства в межклассах на изображениях SAR, авторы предложили взвешенный классификатор расстояния (WDC), который вычисляет специфические для класса веса для образцов запросов в направлении данных, распределенного с использованием евклидового расстояния в качестве руководства. Они также включили потерю генерации веса, чтобы направлять процесс генерации веса. Для оценки использовался набор данных MSTAR и предлагаемый набор данных и набор самолетов (VA), где для VA использовался 4-часовой 5-выстрел, и для VA использовался 4-часовой подход к оценке. Средняя точность (AA) использовалась в качестве метрики оценки повсюду. Результаты оценки продемонстрировали, что набор данных VA имел более высокий AA, чем MSTAR, что указывает на то, что он лучше подходит для мелкозернистых задач классификации.
В исследовании [36] новый подход к классификации нескольких выстрелов вводится посредством интеграции мета-обучения. Этот метод характеризуется синергетическим использованием двух первичных компонентов: мета-обучатого и базового обучения. Основная функция мета-обучения-определить и сохранить скорости обучения, а также обобщенные параметры, относящиеся как к экстрактору, так и классификатору. Его цель состоит в том, чтобы различить параметр оптимальной инициализации, тем самым уточнив стратегии обновления, тщательно изучив распределение нескольких выстрелов. Эта оптимальная инициализация способствует установлению алгоритма на пути, который потенциально ускоряет конвергенцию и повышает производительность. После этого мета-производитель играет ключевую роль в направлении базового обучения. Здесь базовый обучатор концептуализируется как модель классификатора, специально предназначенную для обнаружения целей на основе SAR. Его дизайн обеспечивает повышенную эффективность сходимости под руководством мета-обучения.
Признавая проблемы, связанные с более сложными задачами, исследование дополнительно увеличивает его методологию с помощью метода жесткой задачи. Это особенно ценно при подборе и решении задач, которые по своей сути более сложны. Для приобретения передачи знаний-важнейшего аспекта обучения с несколькими выстрелами-сеть 4Conv используется на этапе мета-тренировки. Эффективность этого подхода, названного MSAR в публикации, была строго протестирована на двух наборах данных: набор данных MSTAR и недавно предложенный набор данных Nist-SAR. Оценки проводились с использованием 5-часовых 1-выстрел и 5-часовых 5-выстрелов, с средней точностью (AA), служащим в качестве контрольной метрики. Эмпирические результаты были показательными; Метод MSAR превзошел базовые методологии производительности для обеих задач. В частности, он достиг впечатляющего АА в размере 86,2% для 5-часовой задачи 1-выстрела и еще более похвальной 97,5% для 5-й 5-выстрел.
В статье по [37] был представлен новый подход к обучению переносам с несколькими выстрелами для передачи знаний из электрооптического (EO) домена в домен синтетической апертурой (SAR). Это достигается путем использования энкодера в каждом домене для извлечения и встраивания отдельных функций в общее встроенное пространство. Кодированные параметры непрерывно обновляются путем минимизации расхождений в предельных распределениях вероятности между двумя встроенными доменами. Поскольку распределения, как правило, неизвестны в нескольких выстрелах, авторы приближают оптимальную метрику измерения расхождения транспорта, используя нарезанное расстояние Wasserstein (SWD) для более эффективных вычислений. Подход оценивается на наборе данных SAR -изображений, полученных [78] для обнаружения наличия или отсутствия кораблей. Точность классификации (ОА) используется в качестве показателя оценки для этого подхода. Результаты показывают, что этот подход может достичь ОА более 90%, что указывает на то, что это надежный и точный метод для обнаружения судов.
В своем исследовании по распознаванию судов с несколькими выстрелами с использованием набора данных MSTAR [79] предложил подход глубокого обучения ядра (DKL), который использует непараметрическую адаптивность гауссовых процессов (GP). Функция ядра, используемая в их подходе, математически определена в (14) как гауссовое ядро

Методы обучения на основе графиков приобрели популярность в классификации изображений SAR, аналогичной гиперспектральной и VHR-классификации. Чтобы улучшить обучение сходства функций среди изображений запросов и более эффективно поддержать графики, [80] предложила сеть взаимосвязи, основанную на сети встраивания для извлечения функций и нейронных сетей на основе внимания (GNN) в форме метрической сети [81]. Модуль внимания канала в CBAM включен в GNN. MSTAR используется для оценки, а 5-серийное сравнение 1-выстрела используется с точностью классификации (OA) в качестве метрики. Кроме того, Yang предложил сеть внимания смешанного графа (MGA-Net), в которой используется многослойный GAT в сочетании с обучением смешанного потери (потери и потери классификации) для повышения отдельной отдельной класса и ускорения конвергенции. Набор данных MSTAR и OpenSarship
Набор данных был использован для сравнения, и 3-серия 1-выстрела и трехсторонней 5-выстрел была использована для сравнения результатов, представленных точностью классификации (ОА) и матрицей путаницы. Результаты показали, что MGA-NET достигла лучшей производительности, чем базовые модели в обоих наборах данных, что указывает на то, что многослойное обучение GAT и Mixed Loss оказало положительное влияние на точность классификации.
Недавно Zhao et al. [82] предложили модель трансформатора с учетом экземпляра (IAT) для нескольких выстрелов-синтетической апертурой автоматического распознавания цели (SAR-ATR). Они признают, что моделирование отношений между запросом и поддержкой изображений имеет решающее значение для нескольких выстрелов SAR-ATR. IAT использует трансформаторы и внимание к совокупным функциям поддержки для каждого изображения запроса. Он строит карты внимания на основе сходства между запросами и функциями поддержки для использования информации из всех случаев. Общие модули кросс-трансформатора выравнивают запросы и функции поддержки. Экземпляр косинус расстояние во время тренировок поднимает экземпляры в том же классе ближе, чтобы улучшить компактность. Эксперименты на нескольких наборах данных SAR-ATR показывают, что IAT превосходит современные методы. Визуализации также демонстрируют улучшенную внутриклассовую компактность и межклассное разделение. Это подчеркивает потенциал трансформаторов и внимания к классификации нескольких выстрелов, эффективно связывая запросы с поддержкой и дискриминационными выравниваниями обучения.
CNN были доминирующими для SAR-ATR, но борются с ограниченными учебными данными. Чтобы решить это, Wang et al. [83] предложили архитектуру сверточного трансформатора (конну), адаптированную для нескольких выстрелов SAR ATR. Они признают, что CNN затрудняют узкие рецептивные поля и неспособность захватывать глобальные зависимости в нескольких выстрелах. Convt создает иерархические особенности и модели глобальные отношения локальных функций на каждом уровне для более надежного представления. Функция гибридной потерь, основанная на метках распознавания и контрастных пар изображений, обеспечивает достаточный надзор за ограниченными данными. Автоматическое увеличение дополнительно увеличивает разнообразие при одновременном сокращении переживания. Без необходимости дополнительных наборов данных Convt достигает современной производительности SAR ATR на MSTAR путем эффективного объединения трансформаторов с CNNS. Это демонстрирует трансформаторы, которые могут преодолеть ограничения CNN для классификации нескольких выстрелов, интегрируя локальные и глобальные зависимости внутри и между уровнями.
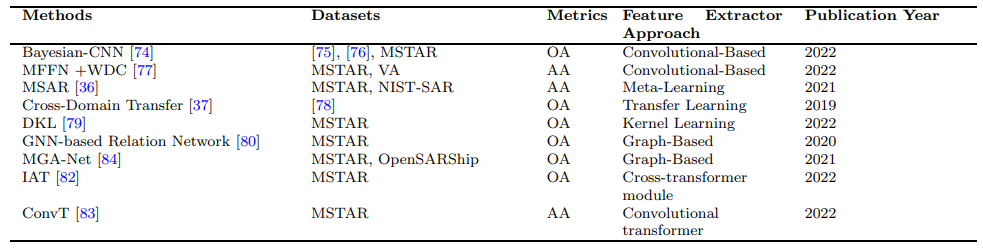
В таблице 5 представлен обзор различных методов обучения, которые были предложены для классификации SAR. В таблице приведены ключевые аспекты каждого подхода, включая название метода, год публикации, набор данных, используемый для оценки, и используемую метрику оценки. Следует отметить, что среди подмножества существующих работ, описанных в этом обзоре, набор данных MSTAR является наиболее часто используемым для алгоритмических сравнений. Набор данных MSTAR широко использовался в классификации SAR из -за его относительно большого размера и разнообразия целевых типов, которые он содержит. В целом, методы, обсуждаемые в таблице 5, подчеркивают потенциал нескольких подходов к обучению в домене SAR и демонстрируют эффективность различных методов, таких как обучение на основе графиков, обучение глубоким ядрам и мета-обучение. Эти подходы имеют потенциал для обеспечения более эффективной и точной классификации данных SAR, которые могут иметь важные приложения в таких областях, как дистанционное зондирование, наблюдение и защита. Методы XAI могут быть действительно полезны для идентификации объектов на радиолокационных изображениях. Поскольку исследователи обычно имеют ограниченный доступ к радиолокационным данным, и это дорого получать новые радиолокационные изображения, полезны новые радарные изображения, такие методы, как объяснимые нейронные сети и механизмы внимания.
Авторы:
(1) Гао Ю Ли, Школа электротехники и электронных инженеров, Нанянг Технологический университет, 50 Нанянг -авеню, 639798, Сингапур (Gaoyu001@e.ntu.edu.sg);
(2) Плотина Танмой, Школа машиностроения и аэрокосмической инженерии, Технологический университет Наняна, 65 Нанянг Драйв, 637460, Сингапур и Департамент компьютерных наук, Университет Нью -Орлеана, Новый Орлеан, 2000 Лейкшор Драйв, LA 70148, США (США (США.tanmoy.dam@ntu.edu.sg);
(3) MD Meftahul Ferdaus, Школа электротехники и электронного инженера, Нанянг Технологический университет, 50 Nanyang Ave, 639798, Сингапур (mferdaus@uno.edu);
(4) Даниэль Пуйу Понар, Школа электротехники и электронных инженеров, Технологический университет Наняна, пр. Наняна, 639798, Сингапур (Epdpuiu@ntu.edu.sg);
(5) Vu N. Duong, Школа машиностроения и аэрокосмической инженерии, Nanyang Technological University, 65 Nanyang Drive, 637460, Сингапур (vu.duong@ntu.edu.sg)
Эта статья есть
Оригинал