

537 историй о науке о данных, которые стоит узнать
8 января 2024 г.Давайте узнаем о науке о данных из этих 537 бесплатных историй. Они упорядочены по времени чтения, созданного на HackerNoon. Посетите /Learn Repo, чтобы найти самые читаемые истории о любой технологии.
Наука об использовании компьютерных программ для анализа тысяч точек данных, а затем использования компьютерных программ для представления этих данных в визуальном формате.
1. Как парсить Google с помощью Python

2. Для анализа данных вам не нужен дорогой компьютер: используйте эти облачные платформы!
 Вам не нужен модный компьютер, чтобы начать заниматься наукой о данных и машинным обучением. Эти 5 облачных платформ просты в настройке и бесплатны в использовании.
Вам не нужен модный компьютер, чтобы начать заниматься наукой о данных и машинным обучением. Эти 5 облачных платформ просты в настройке и бесплатны в использовании.
3. Как превратить ваши данные в помощника по голосовому искусственному интеллекту
 Руководители RAIN подробно рассказывают о конструкции и возможностях голосовых помощников с искусственным интеллектом.
Руководители RAIN подробно рассказывают о конструкции и возможностях голосовых помощников с искусственным интеллектом.
4. Как использовать Google Colab с VS Code
 Google Colab и VS Code — популярные инструменты редактирования. Узнайте, как использовать Google Colab с VS Code и воспользоваться преимуществами полноценного редактора кода.
Google Colab и VS Code — популярные инструменты редактирования. Узнайте, как использовать Google Colab с VS Code и воспользоваться преимуществами полноценного редактора кода.
5. 7 эффективных способов работы с небольшим набором данных
 В реальных условиях у вас часто есть только небольшой набор данных для работы. Модели, обученные на небольшом количестве наблюдений, имеют тенденцию переобучаться и давать неточные результаты. Узнайте, как избежать переобучения и получать точные прогнозы, даже если доступных данных недостаточно.
В реальных условиях у вас часто есть только небольшой набор данных для работы. Модели, обученные на небольшом количестве наблюдений, имеют тенденцию переобучаться и давать неточные результаты. Узнайте, как избежать переобучения и получать точные прогнозы, даже если доступных данных недостаточно.
6. Взлом Pornhub во время пандемии коронавируса
 Пандемия коронавируса 2019–2020 годов — продолжающаяся пандемия коронавирусного заболевания 2019 года (COVID-19), вызванная тяжелым острым респираторным синдромом коронавируса 2 (SARS-CoV-2). Вспышка была впервые выявлена в Ухане, Хубэй, Китай, в декабре 2019 года и признана Всемирной организацией здравоохранения (ВОЗ) пандемией 11 марта 2020 года.
Пандемия коронавируса 2019–2020 годов — продолжающаяся пандемия коронавирусного заболевания 2019 года (COVID-19), вызванная тяжелым острым респираторным синдромом коронавируса 2 (SARS-CoV-2). Вспышка была впервые выявлена в Ухане, Хубэй, Китай, в декабре 2019 года и признана Всемирной организацией здравоохранения (ВОЗ) пандемией 11 марта 2020 года.
7. Как извлекать знания из Википедии в стиле Data Science
 Люди, работающие с данными, склонны думать, что они разрабатывают и экспериментируют со сложными и сложными алгоритмами и получают самые современные результаты. Во многом это правда. Это то, чем больше всего гордится специалист по данным, и это самая инновационная и полезная часть. Но чего люди обычно не замечают, так это того, сколько труда они тратят, собирая, обрабатывая и обрабатывая данные, что приводит к великолепным результатам. Вот почему вы можете видеть, что SQL встречается в большинстве требований к должностям специалиста по данным.
Люди, работающие с данными, склонны думать, что они разрабатывают и экспериментируют со сложными и сложными алгоритмами и получают самые современные результаты. Во многом это правда. Это то, чем больше всего гордится специалист по данным, и это самая инновационная и полезная часть. Но чего люди обычно не замечают, так это того, сколько труда они тратят, собирая, обрабатывая и обрабатывая данные, что приводит к великолепным результатам. Вот почему вы можете видеть, что SQL встречается в большинстве требований к должностям специалиста по данным.
8. Вводное руководство по переменным и типам данных в Go
 Привет! Итак, сегодня мы будем изучать переменные Go и различные типы данных, связанные с Go.
Привет! Итак, сегодня мы будем изучать переменные Go и различные типы данных, связанные с Go.
9. Что такое аннотация изображения? – Знакомство с 5 службами аннотаций изображений
 Аннотации изображений — одна из важнейших задач компьютерного зрения. Благодаря многочисленным приложениям компьютерное зрение, по сути, стремится дать машине глаза – способность видеть и интерпретировать мир. Иногда кажется, что проекты машинного обучения открывают футуристические технологии, которые мы никогда не считали возможными. Приложения на базе искусственного интеллекта, такие как дополненная реальность, автоматическое распознавание речи и нейронный машинный перевод, могут изменить жизнь и бизнес по всему миру. Точно так же технологии, которые может дать нам компьютерное зрение (автономные транспортные средства, распознавание лиц, беспилотные дроны), просто необыкновенны.
Аннотации изображений — одна из важнейших задач компьютерного зрения. Благодаря многочисленным приложениям компьютерное зрение, по сути, стремится дать машине глаза – способность видеть и интерпретировать мир. Иногда кажется, что проекты машинного обучения открывают футуристические технологии, которые мы никогда не считали возможными. Приложения на базе искусственного интеллекта, такие как дополненная реальность, автоматическое распознавание речи и нейронный машинный перевод, могут изменить жизнь и бизнес по всему миру. Точно так же технологии, которые может дать нам компьютерное зрение (автономные транспортные средства, распознавание лиц, беспилотные дроны), просто необыкновенны.
10. Что такое горячее кодирование? Почему и когда вам нужно его использовать?

11. Основы обработки естественного языка за 10 минут
 Вы также хотите изучить НЛП как можно быстрее? Возможно, вы здесь, потому что тоже хотите как можно быстрее освоить обработку естественного языка, как и я.
Вы также хотите изучить НЛП как можно быстрее? Возможно, вы здесь, потому что тоже хотите как можно быстрее освоить обработку естественного языка, как и я.
12. Случайная лесная регрессия в R: код и интерпретация
 В этой статье рассматривается регрессия случайного леса в R с упором на понимание результатов и важности переменных.
В этой статье рассматривается регрессия случайного леса в R с упором на понимание результатов и важности переменных.
13. Автоматический выбор функций в Python: основное руководство
 Выбор объектов в Python — это процесс, в котором вы автоматически или вручную выбираете объекты в наборе данных, которые больше всего способствуют вашему прогнозу.
Выбор объектов в Python — это процесс, в котором вы автоматически или вручную выбираете объекты в наборе данных, которые больше всего способствуют вашему прогнозу.
14. 6 самых больших ограничений технологии искусственного интеллекта
 Хотя выпуск GPT-3 знаменует собой важную веху в развитии искусственного интеллекта, путь вперед все еще неясен. Сегодня все еще существуют определенные ограничения для этой технологии. Вот шесть основных ограничений, с которыми сегодня сталкиваются ученые, работающие с данными.
Хотя выпуск GPT-3 знаменует собой важную веху в развитии искусственного интеллекта, путь вперед все еще неясен. Сегодня все еще существуют определенные ограничения для этой технологии. Вот шесть основных ограничений, с которыми сегодня сталкиваются ученые, работающие с данными.
15. Как я создал приложение для работы с электронными таблицами на Python, чтобы упростить обработку данных
 Сегодня я открываю исходный код Grid Studio — веб-приложения для работы с электронными таблицами с полной интеграцией языка программирования Python.
Сегодня я открываю исходный код Grid Studio — веб-приложения для работы с электронными таблицами с полной интеграцией языка программирования Python.
16. 10 курсов по машинному обучению, науке о данных и глубокому обучению для программистов в 2020 году

17. Теоремы, которые необходимо знать программистам
 Программирование – сложная и многогранная область, охватывающая широкий спектр математических и вычислительных концепций и методов.
Программирование – сложная и многогранная область, охватывающая широкий спектр математических и вычислительных концепций и методов.
18. Введение в возможности векторного поиска для начинающих
 Введение в поиск по нейронным векторам в сравнении с поиском по ключевым словам.
Введение в поиск по нейронным векторам в сравнении с поиском по ключевым словам.
19. Пять лучших платформ машинного обучения, за которыми стоит следить в 2022 году
 Операции машинного обучения (MLOps) — это форма DevOps в развивающейся области. В этой статье мы обсудим 5 лучших платформ машинного обучения, на которые стоит обратить внимание в 2022 году.
Операции машинного обучения (MLOps) — это форма DevOps в развивающейся области. В этой статье мы обсудим 5 лучших платформ машинного обучения, на которые стоит обратить внимание в 2022 году.
20. Как аутентифицировать пользователя с помощью распознавания лиц в вашем веб-приложении
 Аутентификация на основе распознавания лиц для проверки пользователя в веб-приложении обсуждается в удобной для новичков форме с использованием API FaceIO.
Аутентификация на основе распознавания лиц для проверки пользователя в веб-приложении обсуждается в удобной для новичков форме с использованием API FaceIO.
21. Типы линейной регрессии
 Линейную регрессию обычно делят на два типа:
Линейную регрессию обычно делят на два типа:
22. 3 лучших способа импортировать внешние данные в Google Таблицы [автоматически]

23. Более 160 вопросов для собеседования по Data Science
 Типичный процесс собеседования на должность специалиста по анализу данных включает несколько раундов. Часто один из таких раундов посвящен теоретическим концепциям, цель которого — определить, знает ли кандидат основы машинного обучения.
Типичный процесс собеседования на должность специалиста по анализу данных включает несколько раундов. Часто один из таких раундов посвящен теоретическим концепциям, цель которого — определить, знает ли кандидат основы машинного обучения.
24. Преимущества совместного использования Интернета вещей и искусственного интеллекта
 Сочетание искусственного интеллекта (ИИ) и Интернета вещей (IoT) произвело революцию в работе различных отраслей и предприятий. Интернет вещей в сочетании с искусственным интеллектом используется для создания интеллектуальных машин, которые имитируют умные действия и помогают принимать решения с минимальным вмешательством человека. При совместном использовании эти две мощные технологии позволяют предприятиям осуществить настоящую цифровую трансформацию.
Сочетание искусственного интеллекта (ИИ) и Интернета вещей (IoT) произвело революцию в работе различных отраслей и предприятий. Интернет вещей в сочетании с искусственным интеллектом используется для создания интеллектуальных машин, которые имитируют умные действия и помогают принимать решения с минимальным вмешательством человека. При совместном использовании эти две мощные технологии позволяют предприятиям осуществить настоящую цифровую трансформацию.
25. Устранение различий между аналитиками бизнес-аналитики, аналитиками данных и специалистами по данным 🚀
 Было время, когда аналитик данных в команде был человеком, который продвигал цифровизацию в авантюрном поиске данных... а затем инженеры взяли верх.
Было время, когда аналитик данных в команде был человеком, который продвигал цифровизацию в авантюрном поиске данных... а затем инженеры взяли верх.
26. Воспроизводимые конвейеры обучения машинному обучению с помощью dstack и WandB
 Как настроить воспроизводимые конвейеры для отслеживания инфраструктуры, кода, данных, гиперпараметров, показателей эксперимента и т. д. с помощью интеграции WandB и dstack.
Как настроить воспроизводимые конвейеры для отслеживания инфраструктуры, кода, данных, гиперпараметров, показателей эксперимента и т. д. с помощью интеграции WandB и dstack.
27. 4 ценных урока, которые я усвоил, изучая науку о данных
 Я никогда не хотел изучать науку о данных.
Я никогда не хотел изучать науку о данных.
28. 3 лучших способа импортировать JSON в Google Таблицы [Полное руководство]

29. Лучшие (и худшие) шутки, которые поймут только ученые, работающие с данными
 В первом посте KDnuggets на Hacker Noon мы представляем вам более легкую версию очень занудного компьютерного юмора из серии самореферентных шуток, стартовавших в Твиттере ранее на этой неделе. Вот некоторые из наших любимых.
В первом посте KDnuggets на Hacker Noon мы представляем вам более легкую версию очень занудного компьютерного юмора из серии самореферентных шуток, стартовавших в Твиттере ранее на этой неделе. Вот некоторые из наших любимых.
Если вы понимаете все шутки, то вы поздравляете себя с отличными знаниями в области науки о данных и машинного обучения! Если вы действительно посмеялись над двумя или более шутками, то вы заработали степень магистра компьютерного юмора! Если вы только ухмыльнулись, то, вероятно, у вас докторская степень. А про AGI у меня есть отличная шутка, но она будет готова лет через 10.
Наслаждайтесь, а если у вас есть еще, добавьте их в комментариях ниже!
Ян ЛеКун, @ylecun
30. Учебное пособие по НЛП: моделирование тем на Python с помощью BerTopic
 Тематическое моделирование — это метод машинного обучения без учителя, который может автоматически идентифицировать различные темы, присутствующие в документе (текстовые данные). Данные стали ключевым активом/инструментом для управления многими предприятиями по всему миру. С помощью тематического моделирования вы можете собирать неструктурированные наборы данных, анализировать документы и получать нужную и нужную информацию, которая поможет вам принять лучшее решение.
Тематическое моделирование — это метод машинного обучения без учителя, который может автоматически идентифицировать различные темы, присутствующие в документе (текстовые данные). Данные стали ключевым активом/инструментом для управления многими предприятиями по всему миру. С помощью тематического моделирования вы можете собирать неструктурированные наборы данных, анализировать документы и получать нужную и нужную информацию, которая поможет вам принять лучшее решение.
31. Разработка показателей качества программного обеспечения в качестве специалиста по данным: 5 извлеченных уроков
 Показатели качества программного обеспечения являются важными инструментами, обеспечивающими максимальное удобство использования продукта для пользователей. Вот несколько советов для (не только) специалистов по обработке данных.
Показатели качества программного обеспечения являются важными инструментами, обеспечивающими максимальное удобство использования продукта для пользователей. Вот несколько советов для (не только) специалистов по обработке данных.
32. Вопросы для собеседования по техническим данным: SQL и кодирование
 Интервью по науке о данных состоит из нескольких раундов. Один из таких раундов включает в себя теоретические вопросы, которые мы рассмотрели ранее в разделе «160+ вопросов для интервью по науке о данных».
Интервью по науке о данных состоит из нескольких раундов. Один из таких раундов включает в себя теоретические вопросы, которые мы рассмотрели ранее в разделе «160+ вопросов для интервью по науке о данных».
33. 14 открытых наборов данных для классификации текста в машинном обучении
 Наборы данных классификации текста используются для категоризации текстов на естественном языке в соответствии с содержанием. Например, подумайте о классификации новостных статей по темам или классификации рецензий на книги на основе положительных или отрицательных отзывов. Классификация текста также полезна для определения языка, организации обратной связи с клиентами и обнаружения мошенничества. Хотя этот процесс занимает много времени, если выполнять его вручную, его можно автоматизировать с помощью моделей машинного обучения. Результат экономит время компаний, а также предоставляет ценные данные.
Наборы данных классификации текста используются для категоризации текстов на естественном языке в соответствии с содержанием. Например, подумайте о классификации новостных статей по темам или классификации рецензий на книги на основе положительных или отрицательных отзывов. Классификация текста также полезна для определения языка, организации обратной связи с клиентами и обнаружения мошенничества. Хотя этот процесс занимает много времени, если выполнять его вручную, его можно автоматизировать с помощью моделей машинного обучения. Результат экономит время компаний, а также предоставляет ценные данные.
34. Введение в базы данных: использование различных моделей данных и визуальное представление баз данных
 Когда вы начнете изучать базы данных и науку о данных, первое, что вам нужно будет освоить, — это отношения между сущностями в вашей базе данных. Это важно, поскольку данные, которые вы используете, должны быть абсолютно эффективными для их дальнейшей реализации.
Когда вы начнете изучать базы данных и науку о данных, первое, что вам нужно будет освоить, — это отношения между сущностями в вашей базе данных. Это важно, поскольку данные, которые вы используете, должны быть абсолютно эффективными для их дальнейшей реализации.
35 . Инновации в области науки о данных: 5 основных препятствий в процессе внедрения и как их преодолеть
 Наука о данных — быстро развивающаяся отрасль исследований. Его главная цель — превратить огромные объемы записей в ценные бизнес-идеи. Внедрение инструментов, основанных на науке о данных, в вашей компании может быть очень полезным. Программное обеспечение искусственного интеллекта более эффективно и точно, чем когда-либо было у людей.
Наука о данных — быстро развивающаяся отрасль исследований. Его главная цель — превратить огромные объемы записей в ценные бизнес-идеи. Внедрение инструментов, основанных на науке о данных, в вашей компании может быть очень полезным. Программное обеспечение искусственного интеллекта более эффективно и точно, чем когда-либо было у людей.
36. Неконтролируемое увеличение данных
 Чем больше у нас данных, тем большей производительности мы можем достичь. Однако аннотировать большой объем обучающих данных — слишком роскошь. Поэтому правильное увеличение данных полезно для повышения производительности вашей модели. Авторы книги «Неконтролируемое увеличение данных» (Xie et al., 2019) предложили, чтобы неконтролируемое увеличение данных (UDA) помогло нам построить лучшую модель, используя несколько методов увеличения данных.
Чем больше у нас данных, тем большей производительности мы можем достичь. Однако аннотировать большой объем обучающих данных — слишком роскошь. Поэтому правильное увеличение данных полезно для повышения производительности вашей модели. Авторы книги «Неконтролируемое увеличение данных» (Xie et al., 2019) предложили, чтобы неконтролируемое увеличение данных (UDA) помогло нам построить лучшую модель, используя несколько методов увеличения данных.
37. 10 лучших наборов данных фондового рынка для машинного обучения
 Для тех, кто хочет создавать прогнозные модели, в этой статье будут представлены 10 наборов данных о фондовом рынке и криптовалютах для машинного обучения.
Для тех, кто хочет создавать прогнозные модели, в этой статье будут представлены 10 наборов данных о фондовом рынке и криптовалютах для машинного обучения.
38. «Опыт — палка о двух концах»: Кайл Кирван, генеральный директор Bigeye
 Интервью с основателем и генеральным директором Bigeye, платформы для наблюдения за данными.
Интервью с основателем и генеральным директором Bigeye, платформы для наблюдения за данными.
39. 9 лучших курсов по инженерии данных, которые стоит пройти в 2023 году
 В этом списке вы найдете одни из лучших курсов по разработке данных и карьерные пути, которые помогут вам начать свой путь в области разработки данных!
В этом списке вы найдете одни из лучших курсов по разработке данных и карьерные пути, которые помогут вам начать свой путь в области разработки данных!
40. Предварительная обработка данных: 6 необходимых шагов для специалистов по данным
 Привет всем, я вернулся с другой темой — предварительная обработка данных. Это часть процесса анализа данных и машинного обучения, на которую специалисты по данным тратят большую часть своего времени. В этой статье я подробно раскрою эту тему, почему мы ее используем и необходимые шаги.
Привет всем, я вернулся с другой темой — предварительная обработка данных. Это часть процесса анализа данных и машинного обучения, на которую специалисты по данным тратят большую часть своего времени. В этой статье я подробно раскрою эту тему, почему мы ее используем и необходимые шаги.
41. Обработка текста и анализ тональности данных Twitter
 Полное руководство по обработке текста с использованием данных Twitter и R.
Полное руководство по обработке текста с использованием данных Twitter и R.
42. Разрушение финансовых мифов: «Невежественный розничный инвестор»
 Если вы введете в Google фразу «невежественные розничные торговцы», вы найдете упоминания в Financial Times, Seeking Alpha, Wired, Berkshire Money Management, The Street и даже в The South China Morning Post.
Если вы введете в Google фразу «невежественные розничные торговцы», вы найдете упоминания в Financial Times, Seeking Alpha, Wired, Berkshire Money Management, The Street и даже в The South China Morning Post.
43. Существует ли «GitHub для специалистов по данным»?
 Что, если я скажу, что есть место, где вы можете не только хранить свои проекты в области Data Science, но и экспериментировать с ними прямо здесь и сейчас?
Что, если я скажу, что есть место, где вы можете не только хранить свои проекты в области Data Science, но и экспериментировать с ними прямо здесь и сейчас?
44. 10 лучших библиотек диаграмм JavaScript для любых задач визуализации данных
 Существует множество библиотек диаграмм JavaScript. Чтобы облегчить вам жизнь, я решил поделиться своими подборками. Ознакомьтесь с лучшими JS-библиотеками для создания веб-диаграмм!
Существует множество библиотек диаграмм JavaScript. Чтобы облегчить вам жизнь, я решил поделиться своими подборками. Ознакомьтесь с лучшими JS-библиотеками для создания веб-диаграмм!
45. Бесплатный набор инструментов этической ОС для предприятий Woke AI
 Являются ли ваши алгоритмы прозрачными для тех, на кого они влияют? Ваша технология усиливает или усиливает существующую предвзятость?
Являются ли ваши алгоритмы прозрачными для тех, на кого они влияют? Ваша технология усиливает или усиливает существующую предвзятость?
46. Какие книги мы читаем об искусственном интеллекте и машинном обучении в 2020 году?
 Независимо от того, являетесь ли вы опытным профессионалом в этой отрасли или только начинаете окунаться в нее, всегда есть что узнать об искусственном интеллекте и машинном обучении.
Независимо от того, являетесь ли вы опытным профессионалом в этой отрасли или только начинаете окунаться в нее, всегда есть что узнать об искусственном интеллекте и машинном обучении.
47. Передача стиля изображения и преобразование видео в EbSynth

48. 6 лучших фреймворков для обработки данных на основе Python

49. Лучшие библиотеки машинного обучения C/C++ для анализа данных
 Важность C++ в науке о данных и больших данных
Важность C++ в науке о данных и больших данных
50. Как построить границу принятия решения для алгоритмов машинного обучения на Python
 Алгоритмы классификации учатся назначать метки классов примерам (наблюдениям или точкам данных), хотя их решения могут показаться непрозрачными.
Алгоритмы классификации учатся назначать метки классов примерам (наблюдениям или точкам данных), хотя их решения могут показаться непрозрачными.
51 . Python для науки о данных: как очистить данные веб-сайта с помощью 300 лучших API в Интернете

52. 20 лучших наборов данных изображений для машинного обучения и компьютерного зрения
 Компьютерное зрение позволяет компьютерам понимать содержание изображений и видео. Цель компьютерного зрения – автоматизировать задачи, которые может выполнять зрительная система человека.
Компьютерное зрение позволяет компьютерам понимать содержание изображений и видео. Цель компьютерного зрения – автоматизировать задачи, которые может выполнять зрительная система человека.
53. Как получить квалификацию для работы с большими данными для принятия решений
 Аналитика принятия решений, истории данных и облачные сервисы данных — это три тенденции, которые занимают высокие места в Data Analytics 2021.
Аналитика принятия решений, истории данных и облачные сервисы данных — это три тенденции, которые занимают высокие места в Data Analytics 2021.
54. Введение в анализ аудио: распознавание звуков с помощью машинного обучения

55. Сигналы данных против шума: вводящие в заблуждение показатели и заблуждения об аналитике криптоактивов
 Устойчивый рост рынка криптоактивов увеличил потребность и популярность продуктов рыночной разведки/аналитики. Однако, как и любому другому новому классу активов, методологиям и методам извлечения значимой информации о криптоактивах потребуется некоторое время для разработки. К счастью, рынок криптовалют зародился в золотой век науки о данных и машинного обучения, поэтому у него есть шанс создать самое сложное поколение продуктов для анализа рынка, когда-либо существовавших для данного класса активов. Как это ни парадоксально, но мы предпочитаем лениться и придумывать недоработанную аналитику с математической строгостью пятого класса.
Устойчивый рост рынка криптоактивов увеличил потребность и популярность продуктов рыночной разведки/аналитики. Однако, как и любому другому новому классу активов, методологиям и методам извлечения значимой информации о криптоактивах потребуется некоторое время для разработки. К счастью, рынок криптовалют зародился в золотой век науки о данных и машинного обучения, поэтому у него есть шанс создать самое сложное поколение продуктов для анализа рынка, когда-либо существовавших для данного класса активов. Как это ни парадоксально, но мы предпочитаем лениться и придумывать недоработанную аналитику с математической строгостью пятого класса.
56. 11 лучших наборов данных об изменении климата для проектов в области науки о данных
 Данные являются центральной частью дебатов об изменении климата. Используя наборы данных об изменении климата в этом списке, многие ученые, работающие с данными, создали визуализации и модели для измерения и отслеживания изменений температуры поверхности, уровня морского льда и многого другого. Многие из этих наборов данных были обнародованы, чтобы люди могли внести свой вклад и добавить ценную информацию о том, как меняется климат и его причины.
Данные являются центральной частью дебатов об изменении климата. Используя наборы данных об изменении климата в этом списке, многие ученые, работающие с данными, создали визуализации и модели для измерения и отслеживания изменений температуры поверхности, уровня морского льда и многого другого. Многие из этих наборов данных были обнародованы, чтобы люди могли внести свой вклад и добавить ценную информацию о том, как меняется климат и его причины.
57. Как создать парсер с помощью Python [Пошаговое руководство]
 На моем пути самообучения в области программирования мои интересы лежат в области машинного обучения (ML) и искусственного интеллекта (ИИ), а языком, который я выбрал для изучения, является Python.
На моем пути самообучения в области программирования мои интересы лежат в области машинного обучения (ML) и искусственного интеллекта (ИИ), а языком, который я выбрал для изучения, является Python.
58. Что такое обработка естественного языка? Краткий обзор
 Обработка естественного языка (НЛП) — это подобласть искусственного интеллекта. Это способность анализировать и обрабатывать естественный язык.
Обработка естественного языка (НЛП) — это подобласть искусственного интеллекта. Это способность анализировать и обрабатывать естественный язык.
59. Наборы данных НЛП от HuggingFace: как получить к ним доступ и обучить
 Библиотека наборов данных от Hugging Face обеспечивает очень эффективный способ загрузки и обработки наборов данных НЛП из необработанных файлов или данных в памяти. Эти наборы данных НЛП используются различными исследовательскими и практическими сообществами по всему миру.
Библиотека наборов данных от Hugging Face обеспечивает очень эффективный способ загрузки и обработки наборов данных НЛП из необработанных файлов или данных в памяти. Эти наборы данных НЛП используются различными исследовательскими и практическими сообществами по всему миру.
60. Введение в математику, лежащую в основе нейронных сетей
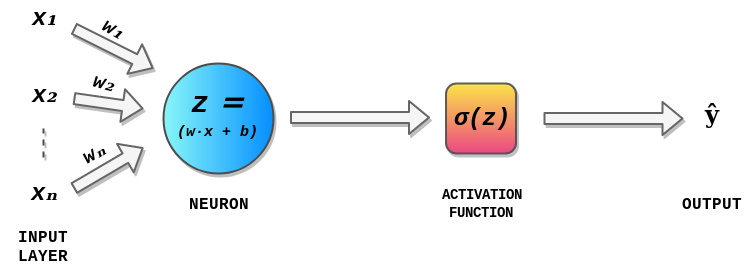 Сегодня с помощью библиотек программного обеспечения для машинного обучения с открытым исходным кодом, таких как TensorFlow, Keras или PyTorch, мы можем создать нейронную сеть даже с высокой структурной сложностью с помощью всего лишь нескольких строк кода. При этом математика, лежащая в основе нейронных сетей, до сих пор остается загадкой для некоторых из нас, и знание математики, лежащей в основе нейронных сетей и глубокого обучения, может помочь нам понять, что происходит внутри нейронной сети. Это также полезно при выборе архитектуры, точной настройке моделей глубокого обучения, настройке и оптимизации гиперпараметров.
Сегодня с помощью библиотек программного обеспечения для машинного обучения с открытым исходным кодом, таких как TensorFlow, Keras или PyTorch, мы можем создать нейронную сеть даже с высокой структурной сложностью с помощью всего лишь нескольких строк кода. При этом математика, лежащая в основе нейронных сетей, до сих пор остается загадкой для некоторых из нас, и знание математики, лежащей в основе нейронных сетей и глубокого обучения, может помочь нам понять, что происходит внутри нейронной сети. Это также полезно при выборе архитектуры, точной настройке моделей глубокого обучения, настройке и оптимизации гиперпараметров.
61. Spotify Audio поддерживает временные ряды в аддитивном анализаторе Spotify
 Есть много статей по анализу данных Spotify, а также многих приложений. Некоторые из них представляют собой однократный анализ музыкальной библиотеки человека, а некоторые представляют собой приложения для определенной цели. Это приложение отличается тем, что оно не делает ничего. Он предназначен для роста и предоставления места для дополнительного анализа. В этой статье рассказывается о том, как создавался временной ряд аудиофункций.
Есть много статей по анализу данных Spotify, а также многих приложений. Некоторые из них представляют собой однократный анализ музыкальной библиотеки человека, а некоторые представляют собой приложения для определенной цели. Это приложение отличается тем, что оно не делает ничего. Он предназначен для роста и предоставления места для дополнительного анализа. В этой статье рассказывается о том, как создавался временной ряд аудиофункций.
62. Как графические процессоры начинают вытеснять кластеры для больших данных и amp; Наука о данных
 Совсем недавно в своем путешествии по науке о данных я использовал низкокачественный потребительский графический процессор (NVIDIA GeForce 1060) для выполнения задач, которые раньше были реально возможны только в кластере — вот почему я думаю, что именно в этом направлении наука о данных пойдет в следующем направлении. 5 лет.
Совсем недавно в своем путешествии по науке о данных я использовал низкокачественный потребительский графический процессор (NVIDIA GeForce 1060) для выполнения задач, которые раньше были реально возможны только в кластере — вот почему я думаю, что именно в этом направлении наука о данных пойдет в следующем направлении. 5 лет.
63. Как создать фиктивные данные в Python
 Фиктивные данные — это случайно сгенерированные данные, которые можно заменить живыми данными. Независимо от того, являетесь ли вы разработчиком, инженером-программистом или специалистом по данным, иногда вам нужны фиктивные данные для проверки того, что вы создали: это может быть веб-приложение, мобильное приложение или модель машинного обучения.
Фиктивные данные — это случайно сгенерированные данные, которые можно заменить живыми данными. Независимо от того, являетесь ли вы разработчиком, инженером-программистом или специалистом по данным, иногда вам нужны фиктивные данные для проверки того, что вы создали: это может быть веб-приложение, мобильное приложение или модель машинного обучения.
64. Как обнаружить эмоции в тексте с помощью Python
 В этом уроке я расскажу вам, как распознавать эмоции, связанные с текстовыми данными, и как это можно применить в реальных приложениях.
В этом уроке я расскажу вам, как распознавать эмоции, связанные с текстовыми данными, и как это можно применить в реальных приложениях.
65. 13 лучших инструментов визуализации данных на 2023 год и последующий период
 Из-за огромных объемов данных визуализация данных стала наиболее востребованным методом изображения огромных чисел в более простых версиях карт или графиков.
Из-за огромных объемов данных визуализация данных стала наиболее востребованным методом изображения огромных чисел в более простых версиях карт или графиков.
66. Почему мы учим Pandas вместо SQL?
 Как я научился перестать использовать панды и полюбил SQL.
Как я научился перестать использовать панды и полюбил SQL.
67. Сбор ответов на твиты с помощью Python и Tweepy Twitter API [Пошаговое руководство]
 Быстрый способ бесплатного извлечения твитов и ответов
Быстрый способ бесплатного извлечения твитов и ответов
68. Создайте свою собственную модель распознавания голоса с помощью Tensorflow
 Хотя я обычно увлекаюсь JavaScript, есть множество вещей, которые Python упрощает выполнение. Распознавание голоса с помощью машинного обучения – одно из них.
Хотя я обычно увлекаюсь JavaScript, есть множество вещей, которые Python упрощает выполнение. Распознавание голоса с помощью машинного обучения – одно из них.
69. Введение в парсинг веб-страниц без кода
 Парсинг веб-страниц сломал барьеры программирования, и теперь его можно выполнять гораздо проще и легче, не используя ни единой строки кода.
Парсинг веб-страниц сломал барьеры программирования, и теперь его можно выполнять гораздо проще и легче, не используя ни единой строки кода.
70. Обучение классификатора изображений с нуля за 15 минут

71. 10 лучших наборов открытых данных для линейной регрессии
 На Hacker Noon я поделюсь некоторыми из моих самых эффективных статей по машинному обучению. Эта статья о наборах данных, созданных для задач регрессии или линейной регрессии, неоднократно поддерживалась на Reddit и десятки раз распространялась на различных платформах социальных сетей. Надеюсь, ученые, работающие с данными Hacker Noon, тоже найдут это полезным!
На Hacker Noon я поделюсь некоторыми из моих самых эффективных статей по машинному обучению. Эта статья о наборах данных, созданных для задач регрессии или линейной регрессии, неоднократно поддерживалась на Reddit и десятки раз распространялась на различных платформах социальных сетей. Надеюсь, ученые, работающие с данными Hacker Noon, тоже найдут это полезным!
72. Построение модели машинного обучения с помощью PySpark [Пошаговое руководство]
 Spark — это название механизма, реализующего кластерные вычисления, а PySpark — это библиотека Python для использования Spark.
Spark — это название механизма, реализующего кластерные вычисления, а PySpark — это библиотека Python для использования Spark.
73. 20 лучших наборов данных PyTorch для построения моделей глубокого обучения
 PyTorch завоевал репутацию платформы, ориентированной на исследования, и это лучшие наборы данных PyTorch для построения моделей глубокого обучения, доступные на сегодняшний день.
PyTorch завоевал репутацию платформы, ориентированной на исследования, и это лучшие наборы данных PyTorch для построения моделей глубокого обучения, доступные на сегодняшний день.
74. Действительно ли графический процессор необходим для работы с данными?
 Большой вопрос для разработчиков приложений машинного обучения и глубокого обучения — использовать или нет компьютер с графическим процессором, ведь графические процессоры по-прежнему очень дороги. Чтобы получить представление, посмотрите, сколько стоит типичный графический процессор для обработки искусственного интеллекта в Бразилии: от 1000 до 7000 долларов США (или больше).
Большой вопрос для разработчиков приложений машинного обучения и глубокого обучения — использовать или нет компьютер с графическим процессором, ведь графические процессоры по-прежнему очень дороги. Чтобы получить представление, посмотрите, сколько стоит типичный графический процессор для обработки искусственного интеллекта в Бразилии: от 1000 до 7000 долларов США (или больше).
75. 20 лучших ресурсов по машинному обучению для специалистов по данным

76. Машинное обучение для решения проблемы классификации рака кожи ISIC
 Это первая часть моей серии классификаций рака ISIC. Вы можете найти часть 2 здесь.
Это первая часть моей серии классификаций рака ISIC. Вы можете найти часть 2 здесь.
77. Как установить программное обеспечение KNIME Analytics для анализа данных
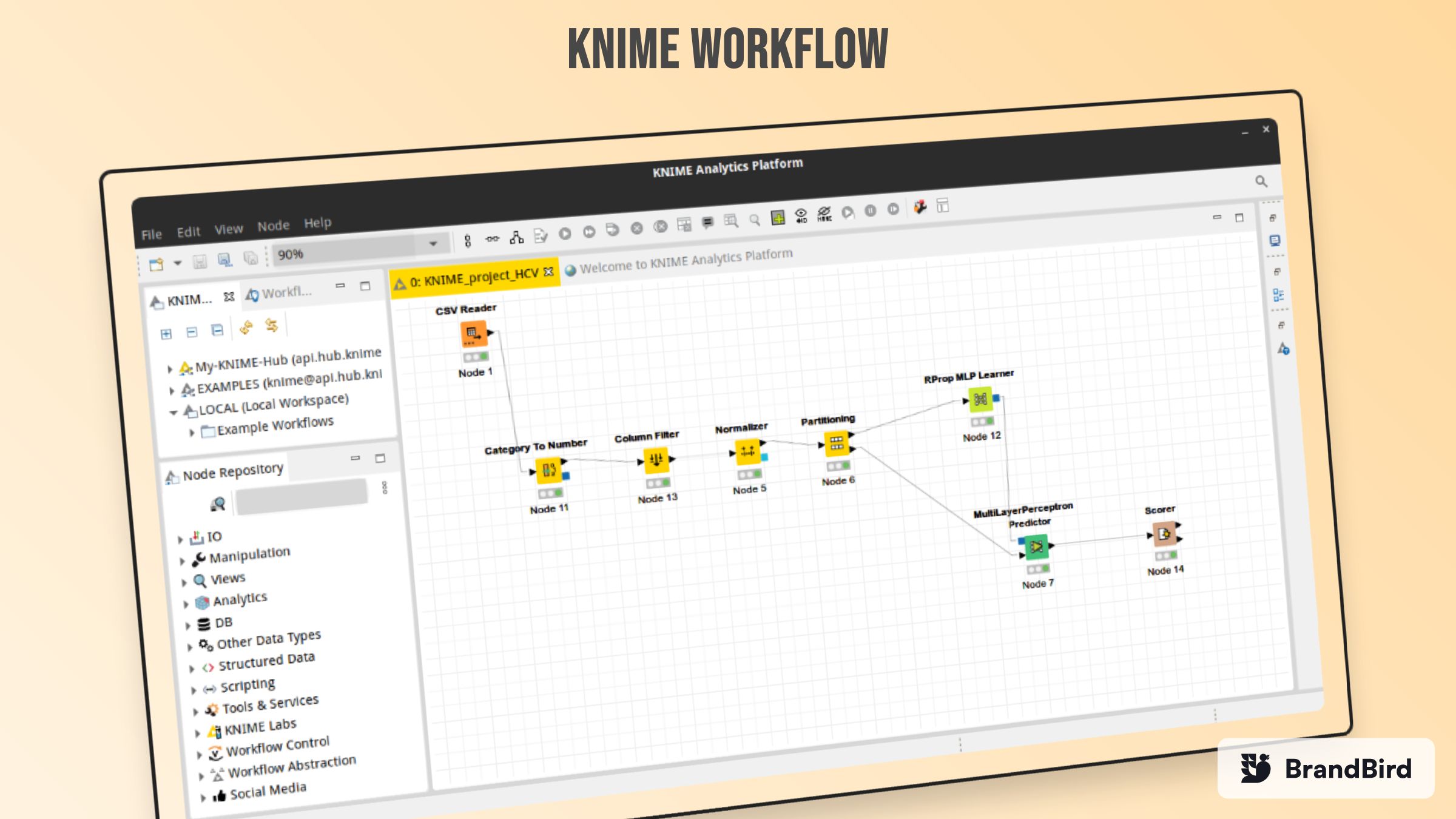 KNIME Analytics — это среда обработки данных, написанная на Java и построенная на Eclipse. Это программное обеспечение позволяет визуально программировать приложения для обработки данных.
KNIME Analytics — это среда обработки данных, написанная на Java и построенная на Eclipse. Это программное обеспечение позволяет визуально программировать приложения для обработки данных.
78. Karate Club — библиотека Python для изучения графических представлений
 Karate Club — это библиотека расширения неконтролируемого машинного обучения для пакета NetworkX Python. См. документацию здесь.
Karate Club — это библиотека расширения неконтролируемого машинного обучения для пакета NetworkX Python. См. документацию здесь.
79. Сколько криптовалют просто следуют за рынком?
 За последние несколько дней на рынке криптовалют произошел массовый разгром.
За последние несколько дней на рынке криптовалют произошел массовый разгром.
80. Что такое возможность аудита для систем искусственного интеллекта?
 До недавнего времени мы воспринимали теорию «черного ящика» об ИИ как неизбежное зло, которое нельзя экстраполировать отдельно от ИИ как концепции.
До недавнего времени мы воспринимали теорию «черного ящика» об ИИ как неизбежное зло, которое нельзя экстраполировать отдельно от ИИ как концепции.
81. Мои заметки о показателях ошибок MAE и MSE 🚀
 Мы сосредоточимся на метриках MSE и MAE, которые часто используются в регрессионных моделях.
Мы сосредоточимся на метриках MSE и MAE, которые часто используются в регрессионных моделях.
82. Fintech 2021: как финтех-компании эффективно используют большие данные?
 Согласно исследованию, 90% всех мировых данных было создано за последние два года. Звучит довольно круто, но что мир делает со всеми этими данными? Как это анализировать?
Согласно исследованию, 90% всех мировых данных было создано за последние два года. Звучит довольно круто, но что мир делает со всеми этими данными? Как это анализировать?
83. Как машинное обучение может прогнозировать фондовый рынок?
 Искусственный интеллект меняет мир, каким мы его знаем. Формируйте беспилотные автомобили для прогнозов погоды. Теперь он выходит на фондовый рынок. Вот как.
Искусственный интеллект меняет мир, каким мы его знаем. Формируйте беспилотные автомобили для прогнозов погоды. Теперь он выходит на фондовый рынок. Вот как.
84. Наш основанный на данных подход к осмыслению президентских выборов 2020 года
 Менее чем через пять месяцев внимание всего мира будет приковано к итогам президентских выборов в США.
Менее чем через пять месяцев внимание всего мира будет приковано к итогам президентских выборов в США.
85. Почему качество данных является ключом к успеху операций по машинному обучению
 В этой первой статье нашей серии, состоящей из двух частей, мы рассмотрим ML Ops и подчеркнем, как и почему качество данных является ключевым моментом в рабочих процессах ML Ops.
В этой первой статье нашей серии, состоящей из двух частей, мы рассмотрим ML Ops и подчеркнем, как и почему качество данных является ключевым моментом в рабочих процессах ML Ops.
86. Базовое понимание ARIMA/SARIMA и автоматического ARIMA/SARIMA с использованием прогнозов данных о Covid-19
 Мотивация
Мотивация
87. Ключевые тактики, которые используют профессионалы для извлечения признаков из временных рядов

88. 50 лучших сайтов для изучения науки о данных

89. Вариационные автоэнкодеры (VAE): как ИИ узнает, открыты или закрыты ваши глаза
 Классифицируйте открытые/закрытые глаза с помощью вариационных автоэнкодеров (VAE).
Классифицируйте открытые/закрытые глаза с помощью вариационных автоэнкодеров (VAE).
90. «Мы знаем о способности ИИ запоминать, но забываем о его способности забывать». - Валерия Садовых
 Поскольку наш мир приближается к тому времени, когда искусственный интеллект станет таким же распространенным, как электричество, мы встретились с Валерией Садовых, ведущим экспертом в области принятия решений и аспектов анализа решений в области ИИ. Валерия имеет степень доктора философии. окончила Школу бизнеса Университета Окленда и имеет более чем 10-летний опыт работы над новыми технологиями в PwC в Новой Зеландии, Сингапуре и США.
Поскольку наш мир приближается к тому времени, когда искусственный интеллект станет таким же распространенным, как электричество, мы встретились с Валерией Садовых, ведущим экспертом в области принятия решений и аспектов анализа решений в области ИИ. Валерия имеет степень доктора философии. окончила Школу бизнеса Университета Окленда и имеет более чем 10-летний опыт работы над новыми технологиями в PwC в Новой Зеландии, Сингапуре и США.
91. Последняя неделя в AI
 Каждую неделю моя команда в Invector Labs публикует информационный бюллетень, в котором отслеживаются самые последние разработки в области исследований и технологий искусственного интеллекта. Вы можете найти выпуск этой недели ниже. Зарегистрироваться на него можно по этой ссылке. Пожалуйста, сделайте это, наши ребята очень старались.
Каждую неделю моя команда в Invector Labs публикует информационный бюллетень, в котором отслеживаются самые последние разработки в области исследований и технологий искусственного интеллекта. Вы можете найти выпуск этой недели ниже. Зарегистрироваться на него можно по этой ссылке. Пожалуйста, сделайте это, наши ребята очень старались.
92. COVID-19: нам нужно больше, чем просто данные, нам нужна информация!
93. Что Apple и Spotify знают обо мне
 Неудивительно, что данные, которые наши приложения собирают о нас, впечатляют и вызывают беспокойство, хотя их может быть очень интересно просмотреть и изучить.
Неудивительно, что данные, которые наши приложения собирают о нас, впечатляют и вызывают беспокойство, хотя их может быть очень интересно просмотреть и изучить.
94. Как выбор данных влияет на производительность модели: AMA с SiaSearch
 SiaSearch — это берлинский стартап в области искусственного интеллекта, миссия которого заключается в ускорении разработки приложений компьютерного зрения.
SiaSearch — это берлинский стартап в области искусственного интеллекта, миссия которого заключается в ускорении разработки приложений компьютерного зрения.
95. Использование метода Монте-Карло для объяснения того, почему вы не выигрываете ежедневные фэнтезийные бейсбольные матчи
 Используйте моделирование Монте-Карло, чтобы понять риск, связанный с фэнтезийным бейсболом. Узнайте, почему оптимизация состава – сложная задача.
Используйте моделирование Монте-Карло, чтобы понять риск, связанный с фэнтезийным бейсболом. Узнайте, почему оптимизация состава – сложная задача.
96. Команды специалистов по обработке и анализу данных поступают неправильно: ставят технологии впереди людей
 Наука о данных и машинное обучение стали конкурентными преимуществами для организаций из разных отраслей. Но большое количество моделей ML так и не пошло в производство. Почему?
Наука о данных и машинное обучение стали конкурентными преимуществами для организаций из разных отраслей. Но большое количество моделей ML так и не пошло в производство. Почему?
97. Библиотеки Python для науки о данных
 Внедрение языка программирования Python в ведущих библиотеках обработки данных помогает разработчикам создавать автономные игры для ПК, мобильных устройств и других подобных корпоративных приложений. Python имеет более 137 000 библиотек, которые помогают во многих отношениях. В этом мире, ориентированном на данные, большинство потребителей требуют актуальной информации в процессе покупки. Компаниям также нужны ученые, работающие с данными, для достижения глубокого понимания путем обработки больших данных.
Внедрение языка программирования Python в ведущих библиотеках обработки данных помогает разработчикам создавать автономные игры для ПК, мобильных устройств и других подобных корпоративных приложений. Python имеет более 137 000 библиотек, которые помогают во многих отношениях. В этом мире, ориентированном на данные, большинство потребителей требуют актуальной информации в процессе покупки. Компаниям также нужны ученые, работающие с данными, для достижения глубокого понимания путем обработки больших данных.
98. 7 эффективных способов улучшить контент-маркетинг с помощью инструментов искусственного интеллекта
 Искусственный интеллект (ИИ) имеет множество вариантов использования в бизнесе и может применяться для обслуживания клиентов, продаж, привлечения потенциальных клиентов и маркетинга.
Искусственный интеллект (ИИ) имеет множество вариантов использования в бизнесе и может применяться для обслуживания клиентов, продаж, привлечения потенциальных клиентов и маркетинга.
99. Обучение с подкреплением: краткое введение в правила и их применение
 Мозг человеческого ребенка поразительно удивителен. Даже в любой ранее неизвестной ситуации мозг принимает решение, основываясь на своих первичных знаниях. В зависимости от результата он изучает и запоминает наиболее оптимальные варианты выбора в данном конкретном сценарии. На более высоком уровне этот процесс обучения можно понимать как процесс «проб и ошибок», когда мозг пытается максимизировать возникновение положительных результатов.
Мозг человеческого ребенка поразительно удивителен. Даже в любой ранее неизвестной ситуации мозг принимает решение, основываясь на своих первичных знаниях. В зависимости от результата он изучает и запоминает наиболее оптимальные варианты выбора в данном конкретном сценарии. На более высоком уровне этот процесс обучения можно понимать как процесс «проб и ошибок», когда мозг пытается максимизировать возникновение положительных результатов.
100. Как позиция IBM в отношении распознавания лиц повлияет на индустрию искусственного интеллекта
 В письме конгрессу, отправленном 8 июня, генеральный директор IBM Арвинд Кришна сделал смелое заявление относительно политики компании в отношении распознавания лиц. «IBM больше не предлагает универсальное программное обеспечение IBM для распознавания или анализа лиц», — говорит Кришна.
В письме конгрессу, отправленном 8 июня, генеральный директор IBM Арвинд Кришна сделал смелое заявление относительно политики компании в отношении распознавания лиц. «IBM больше не предлагает универсальное программное обеспечение IBM для распознавания или анализа лиц», — говорит Кришна.
101. Каннада-MNIST: новый набор данных рукописных цифр в городе ML
 TLDR:
TLDR:
102. 9 бесплатных инструментов искусственного интеллекта, которые должен попробовать каждый
 Раскройте возможности искусственного интеллекта с помощью этих 9 бесплатных инструментов! Повысьте производительность, улучшите процесс принятия решений и улучшить свою личную жизнь.
Раскройте возможности искусственного интеллекта с помощью этих 9 бесплатных инструментов! Повысьте производительность, улучшите процесс принятия решений и улучшить свою личную жизнь.
103. 20 подкастов по науке о данных, которые нельзя пропустить
 Подкасты однозначно стали одной из наиболее доминирующих форм медиапотребления в последние годы.
Подкасты однозначно стали одной из наиболее доминирующих форм медиапотребления в последние годы.
104. 15 статей о машинном обучении, которые стоит прочитать специалистам по обработке данных
 Как всегда, области глубокого обучения и обработки естественного языка заняты как никогда. Несмотря на то, что во многих странах карантинные ограничения тормозят работу многих отраслей, индустрия машинного обучения продолжает двигаться вперед.
Как всегда, области глубокого обучения и обработки естественного языка заняты как никогда. Несмотря на то, что во многих странах карантинные ограничения тормозят работу многих отраслей, индустрия машинного обучения продолжает двигаться вперед.
105. 10 стартапов в области компьютерного зрения на Product Hunt, получивших наибольшее количество голосов
 От беспилотных автомобилей и распознавания лиц до наблюдения за искусственным интеллектом и GAN, технология компьютерного зрения в последние годы стала образцом индустрии искусственного интеллекта. Благодаря такому сплоченному глобальному сообществу специалистов по данным, достижения были достигнуты как исследовательскими группами, так и крупными технологическими стартапами и стартапами в области компьютерного зрения.
От беспилотных автомобилей и распознавания лиц до наблюдения за искусственным интеллектом и GAN, технология компьютерного зрения в последние годы стала образцом индустрии искусственного интеллекта. Благодаря такому сплоченному глобальному сообществу специалистов по данным, достижения были достигнуты как исследовательскими группами, так и крупными технологическими стартапами и стартапами в области компьютерного зрения.
106. Количественная оценка изменчивости: дисперсия, стандартное отклонение и коэффициент вариации
 Существует множество способов количественной оценки изменчивости, однако здесь мы сосредоточимся на наиболее распространенных из них: дисперсии, стандартном отклонении и коэффициенте вариации. В области статистики мы обычно используем разные формулы при работе с данными о населении и выборочными данными.
Существует множество способов количественной оценки изменчивости, однако здесь мы сосредоточимся на наиболее распространенных из них: дисперсии, стандартном отклонении и коэффициенте вариации. В области статистики мы обычно используем разные формулы при работе с данными о населении и выборочными данными.
107. Как я создал набор данных Simpsons для сегментации экземпляров
 Этот пост посвящен созданию собственного набора данных для сегментации изображений/обнаружения объектов. Он обеспечивает комплексное представление о том, что происходит в реальном проекте обнаружения/сегментации изображений.
Этот пост посвящен созданию собственного набора данных для сегментации изображений/обнаружения объектов. Он обеспечивает комплексное представление о том, что происходит в реальном проекте обнаружения/сегментации изображений.
108. 5 лучших инструментов обработки данных для компьютерного зрения в 2021 году
 В этой статье мы углубимся в важность управления данными для компьютерного зрения, а также рассмотрим лучшие инструменты управления данными на рынке.
В этой статье мы углубимся в важность управления данными для компьютерного зрения, а также рассмотрим лучшие инструменты управления данными на рынке.
109. Генри Киссинджер против искусственного интеллекта
 Генри Киссинджер об ИИ: «Вы работаете над приложениями, я работаю над последствиями».
Генри Киссинджер об ИИ: «Вы работаете над приложениями, я работаю над последствиями».
110 . RANSAC, OLS, PCA: 3 способа провести прямую линию через набор точек

111 . Разоблачение посредственных учителей в моей школе с помощью данных – вот моя неудачная попытка
 История программиста
История программиста
112. Прогнозирование пола на основе данных мобильного приложения
 Создайте модель прогнозирования пола на основе списка установленных приложений на мобильном устройстве.
Создайте модель прогнозирования пола на основе списка установленных приложений на мобильном устройстве.
113. Galactica – это модель искусственного интеллекта, обученная на 120 миллиардах параметров
 15 ноября MetaAI и Papers with Code объявили о выпуске Galactica — революционной модели большого языка с открытым исходным кодом, основанной на научных знаниях и 120 миллиардах параметров.
15 ноября MetaAI и Papers with Code объявили о выпуске Galactica — революционной модели большого языка с открытым исходным кодом, основанной на научных знаниях и 120 миллиардах параметров.
114. Создание устойчивых решений искусственного интеллекта и машинного обучения в облаке с помощью федеративного обучения
 Как федеративное обучение может помочь нам бороться с вредным воздействием на окружающую среду по сравнению с централизованными механизмами обучения и охлаждения, принятыми в центрах обработки данных?
Как федеративное обучение может помочь нам бороться с вредным воздействием на окружающую среду по сравнению с централизованными механизмами обучения и охлаждения, принятыми в центрах обработки данных?
115. Процентильное приближение против. Средние значения
 Узнайте, как использовать процентильные аппроксимации и почему они полезны для анализа данных временных рядов.
Узнайте, как использовать процентильные аппроксимации и почему они полезны для анализа данных временных рядов.
116 . Задавайте правильные вопросы о криптоактивах
 Один из моих наставников в области искусственного интеллекта (ИИ) всегда говорит, что с помощью современных технологий машинного обучения можно найти практически любой ответ, но самое сложное — задавать правильные вопросы. Этот принцип, безусловно, применим к криптоактивам. Как новый класс финансовых активов, криптотокены чаще всего оцениваются с использованием традиционных показателей, основанных на цене и объеме, но мы можем сделать гораздо больше. В богатой данными вселенной, где блокчейны и обмен данными генерируют миллиарды точек данных, мы, безусловно, можем найти всевозможные интересные закономерности и факторы, объясняющие поведение криптоактивов. Самое сложное — знать, что искать.
Один из моих наставников в области искусственного интеллекта (ИИ) всегда говорит, что с помощью современных технологий машинного обучения можно найти практически любой ответ, но самое сложное — задавать правильные вопросы. Этот принцип, безусловно, применим к криптоактивам. Как новый класс финансовых активов, криптотокены чаще всего оцениваются с использованием традиционных показателей, основанных на цене и объеме, но мы можем сделать гораздо больше. В богатой данными вселенной, где блокчейны и обмен данными генерируют миллиарды точек данных, мы, безусловно, можем найти всевозможные интересные закономерности и факторы, объясняющие поведение криптоактивов. Самое сложное — знать, что искать.
117. 5 проблем с большими данными и способы их решения
 «Большие данные появились, но больших идей еще нет». ―Тим Харфорд, английский обозреватель и экономист
«Большие данные появились, но больших идей еще нет». ―Тим Харфорд, английский обозреватель и экономист
118. 5 основных классификаций продуктов для специалистов по данным
 Категоризация продуктов/классификация продуктов — это организация продуктов по соответствующим отделам или категориям. Кроме того, значительная часть процесса — это разработка таксономии продукта в целом.
Категоризация продуктов/классификация продуктов — это организация продуктов по соответствующим отделам или категориям. Кроме того, значительная часть процесса — это разработка таксономии продукта в целом.
119. 5 проблем, которые искусственный интеллект пока не может решить
 Человечество в последнее время начало все больше полагаться на помощь ИИ. Но можем ли мы сегодня действительно положиться на такую технологию?
Человечество в последнее время начало все больше полагаться на помощь ИИ. Но можем ли мы сегодня действительно положиться на такую технологию?
120. Представляем нашу платформу машинного обучения Low Code
 Мы очень рады выпустить бесплатную версию dunnhumby Model Lab в рамках нашего партнерства с Microsoft. dunnhumby Model Lab – это приложение, которое обеспечивает автоматизированные конвейеры для развертывания алгоритмов машинного обучения и использовалось для создания миллионов моделей по поручению наших клиентов.
Мы очень рады выпустить бесплатную версию dunnhumby Model Lab в рамках нашего партнерства с Microsoft. dunnhumby Model Lab – это приложение, которое обеспечивает автоматизированные конвейеры для развертывания алгоритмов машинного обучения и использовалось для создания миллионов моделей по поручению наших клиентов.
121. Причинность Грейнджера: объяснение принципа причины и следствия
 ... в мире, полном данных, мы можем понять последствия с помощью умных методов. Познакомьтесь с причинно-следственной связью Грейнджер.
... в мире, полном данных, мы можем понять последствия с помощью умных методов. Познакомьтесь с причинно-следственной связью Грейнджер.
122. Машинное обучение: объяснение за 5 минут
 Google использует его для предоставления миллионов результатов поиска каждый час. Это помогает Facebook угадать ваш следующий любовный интерес. Даже Tesla Илона Маска использует его для самообучения
Google использует его для предоставления миллионов результатов поиска каждый час. Это помогает Facebook угадать ваш следующий любовный интерес. Даже Tesla Илона Маска использует его для самообучения
123. Советы по использованию сервисных Mesh-сетей, чтобы оставить конкурентов позади
 Предыстория и происхождение Service Mesh Network – Istio
Предыстория и происхождение Service Mesh Network – Istio
124. Как стать выдающимся специалистом по данным: эксперт делится своими секретами
 В последнем выпуске нашего подкаста «Машинное обучение, которое работает» мне было очень приятно поговорить с Габриэлем Предой, ведущим специалистом по данным в Endava и гроссмейстером Kaggle.
В последнем выпуске нашего подкаста «Машинное обучение, которое работает» мне было очень приятно поговорить с Габриэлем Предой, ведущим специалистом по данным в Endava и гроссмейстером Kaggle.
125. Как веб-сканирование используется в науке о данных
 Инструменты без кода для сбора данных для вашего проекта Data Science
Инструменты без кода для сбора данных для вашего проекта Data Science
126. SpeechPainter: обработка речи с учетом текста
 Мы видели раскрашивание изображения, целью которого является удаление нежелательного объекта с изображения. Методы, основанные на машинном обучении, не просто удаляют объекты, но также понимают картинку и заполняют недостающие части изображения тем, как должен выглядеть фон. Последние достижения невероятны, как и результаты, и эта задача по рисованию может быть весьма полезна для многих приложений, таких как реклама или улучшение вашей будущей публикации в Instagram. Мы также рассмотрели еще более сложную задачу: рисование видео, при котором тот же процесс применяется к видео для удаления объектов или людей.
Мы видели раскрашивание изображения, целью которого является удаление нежелательного объекта с изображения. Методы, основанные на машинном обучении, не просто удаляют объекты, но также понимают картинку и заполняют недостающие части изображения тем, как должен выглядеть фон. Последние достижения невероятны, как и результаты, и эта задача по рисованию может быть весьма полезна для многих приложений, таких как реклама или улучшение вашей будущей публикации в Instagram. Мы также рассмотрели еще более сложную задачу: рисование видео, при котором тот же процесс применяется к видео для удаления объектов или людей.
127. Краткое введение в 5 прогнозных моделей в науке о данных
 Прогнозное моделирование в науке о данных больше похоже на ответ на вопрос «Что произойдет в будущем на основе известного поведения в прошлом?»
Прогнозное моделирование в науке о данных больше похоже на ответ на вопрос «Что произойдет в будущем на основе известного поведения в прошлом?»
128. Обнаружение аномалий по ЭКГ плода — пример обнаружения аномалий IOT с использованием GAN
 В этом блоге мы обсуждаем роль вариационного автоматического кодировщика в обнаружении аномалий по сигналам ЭКГ плода.
В этом блоге мы обсуждаем роль вариационного автоматического кодировщика в обнаружении аномалий по сигналам ЭКГ плода.
129. Полный набор инструментов для стартапов ML
 Настройка хорошего набора инструментов для вашей команды по машинному обучению важна для эффективной работы и возможности сосредоточиться на достижении результатов. Если вы работаете в стартапе, вы знаете, что особенно важно создать среду, которая может расти вместе с вашей командой, потребностями пользователей и быстро развивающейся средой машинного обучения.
Настройка хорошего набора инструментов для вашей команды по машинному обучению важна для эффективной работы и возможности сосредоточиться на достижении результатов. Если вы работаете в стартапе, вы знаете, что особенно важно создать среду, которая может расти вместе с вашей командой, потребностями пользователей и быстро развивающейся средой машинного обучения.
130. Прогнозирование спроса в розничной торговле: глубокий взгляд
 Я точно знаю, что поведение человека можно предсказать с помощью науки о данных и машинного обучения. Люди лгут, а данные — нет. Взглянув на поведение людей с точки зрения анализа данных о продажах, мы можем получить более ценную информацию, чем с помощью социальных опросов.
Я точно знаю, что поведение человека можно предсказать с помощью науки о данных и машинного обучения. Люди лгут, а данные — нет. Взглянув на поведение людей с точки зрения анализа данных о продажах, мы можем получить более ценную информацию, чем с помощью социальных опросов.
131. Что такое ИИ, ориентированный на данные?
 Мощь GPT-3 и Dalle делает одно и то же: данные.
Мощь GPT-3 и Dalle делает одно и то же: данные.
132. Путеводитель по PyTorch для специалистов по данным
 PyTorch стал своего рода фактическим стандартом для создания нейронных сетей, и мне нравится его интерфейс. Тем не менее, новичкам немного сложно разобраться.
PyTorch стал своего рода фактическим стандартом для создания нейронных сетей, и мне нравится его интерфейс. Тем не менее, новичкам немного сложно разобраться.
133. 17 наборов данных об открытой преступности для проектов по науке о данных и машинному обучению
 Для тех, кто хочет проанализировать уровень или тенденции преступности в определенной области или периоде времени, мы составили список из 16 лучших наборов данных о преступности, доступных для публичного использования.
Для тех, кто хочет проанализировать уровень или тенденции преступности в определенной области или периоде времени, мы составили список из 16 лучших наборов данных о преступности, доступных для публичного использования.
134. Дорожная карта для того, чтобы стать специалистом по данным
 Итак, вы хотите стать специалистом по данным? Вы так много слышали о науке о данных и хотите знать, о чем идет речь? Что ж, вы попали в идеальное место. Область науки о данных значительно изменилась за последнее десятилетие. Сегодня существует множество способов начать работу в этой области и стать специалистом по данным. Не всем из них нужно, чтобы у вас была высшая степень. Итак, начнем!
Итак, вы хотите стать специалистом по данным? Вы так много слышали о науке о данных и хотите знать, о чем идет речь? Что ж, вы попали в идеальное место. Область науки о данных значительно изменилась за последнее десятилетие. Сегодня существует множество способов начать работу в этой области и стать специалистом по данным. Не всем из них нужно, чтобы у вас была высшая степень. Итак, начнем!
135. Объясняйте сложные понятия с помощью минималистичных рисунков с помощью Okso.app
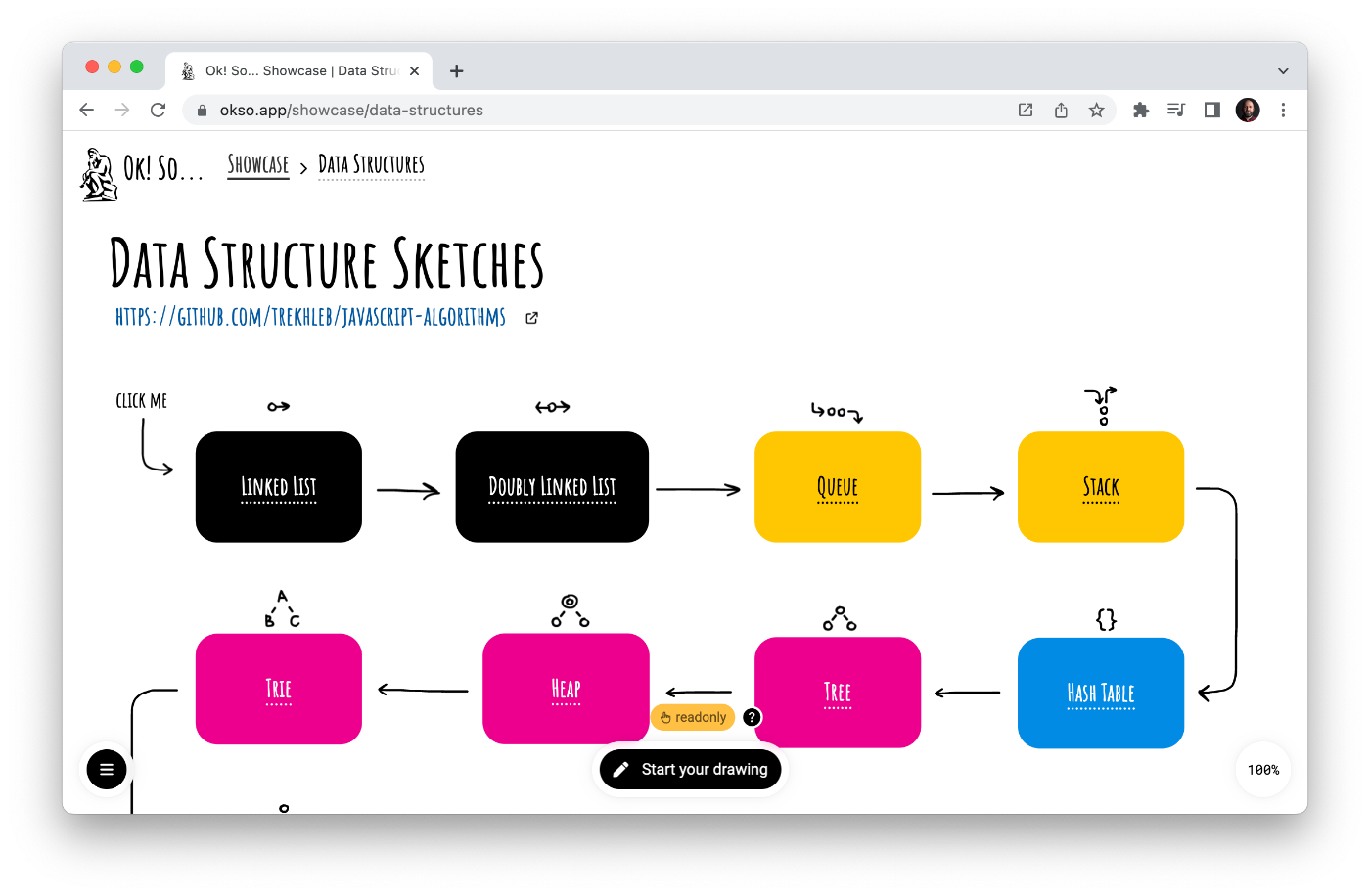 Минималистичные наброски структуры данных
Минималистичные наброски структуры данных
136. Мы собираем формулировки проблем ИИ для краудсорсинга решений для ученых, занимающихся данными.
 Поскольку технологии проникают во все аспекты жизни и продолжают расти в геометрической прогрессии, потенциал решений становится огромным. В то же время мы живем в мире, где миллиарды людей живут в бедности, а миллионы находятся на грани голода. Чтобы поддержать постоянно растущее население, нам нужно приложить все усилия в поисках решений. ИИ предлагает множество потенциальных решений величайших проблем человечества. «ИИ» — это расплывчатый и даже сбивающий с толку термин. Если вы слышите фразу «искусственный интеллект», вы можете задаться вопросом, почему вокруг не ходят разумные роботы или почему еще не все ездят на беспилотных автомобилях. Реальность такова, что «ИИ» — это всего лишь маркетинговый термин для набора вычислительных статистических инструментов или, проще говоря, алгоритмов. Однако, насколько универсальна математика, настолько же универсален и ИИ. ИИ ограничен (в первую очередь) парой вещей: данными и вычислительной мощностью. Как данные, так и вычислительная мощность, которыми мы располагаем, растут экспоненциально, поэтому ИИ становится все более и более мощным. Благодаря такому увеличению объема данных и вычислительных возможностей ИИ теперь используется в самых разных приложениях. Например, bitgrit (отказ от ответственности) : Я генеральный директор), собирает значимые формулировки проблем искусственного интеллекта для краудсорсинга решений для специалистов по данным. Некоторые из заявлений о проблемах включают спасение жизней животных, повышение урожайности сельскохозяйственных культур и ускорение обработки медицинских претензий. Майкл Саттлс, генеральный директор Save All The Pets, объясняет, как данные и искусственный интеллект можно использовать для спасения животных из приютов:
Поскольку технологии проникают во все аспекты жизни и продолжают расти в геометрической прогрессии, потенциал решений становится огромным. В то же время мы живем в мире, где миллиарды людей живут в бедности, а миллионы находятся на грани голода. Чтобы поддержать постоянно растущее население, нам нужно приложить все усилия в поисках решений. ИИ предлагает множество потенциальных решений величайших проблем человечества. «ИИ» — это расплывчатый и даже сбивающий с толку термин. Если вы слышите фразу «искусственный интеллект», вы можете задаться вопросом, почему вокруг не ходят разумные роботы или почему еще не все ездят на беспилотных автомобилях. Реальность такова, что «ИИ» — это всего лишь маркетинговый термин для набора вычислительных статистических инструментов или, проще говоря, алгоритмов. Однако, насколько универсальна математика, настолько же универсален и ИИ. ИИ ограничен (в первую очередь) парой вещей: данными и вычислительной мощностью. Как данные, так и вычислительная мощность, которыми мы располагаем, растут экспоненциально, поэтому ИИ становится все более и более мощным. Благодаря такому увеличению объема данных и вычислительных возможностей ИИ теперь используется в самых разных приложениях. Например, bitgrit (отказ от ответственности) : Я генеральный директор), собирает значимые формулировки проблем искусственного интеллекта для краудсорсинга решений для специалистов по данным. Некоторые из заявлений о проблемах включают спасение жизней животных, повышение урожайности сельскохозяйственных культур и ускорение обработки медицинских претензий. Майкл Саттлс, генеральный директор Save All The Pets, объясняет, как данные и искусственный интеллект можно использовать для спасения животных из приютов:
137. Представляем CatalyzeX: расширение браузера для машинного обучения
 Эндрю Нгу это нравится, и вам, вероятно, тоже!
Эндрю Нгу это нравится, и вам, вероятно, тоже!
138. О сложности создания этического кодекса науки о данных

139. Как создать простую веб-панель для эффективного анализа данных
 Дашборд с различными визуализациями позволяет сравнивать данные и показывать изменения и тенденции. В этом уроке я объясню, почему и как его создать.
Дашборд с различными визуализациями позволяет сравнивать данные и показывать изменения и тенденции. В этом уроке я объясню, почему и как его создать.
140. Лучшие группы Slack для специалистов по данным, к которым можно присоединиться
 Онлайн-сообщество специалистов по науке о данных оказывает поддержку и сотрудничество. Один из способов присоединиться к сообществу — найти группы в Slack по машинному обучению и искусственному интеллекту.
Онлайн-сообщество специалистов по науке о данных оказывает поддержку и сотрудничество. Один из способов присоединиться к сообществу — найти группы в Slack по машинному обучению и искусственному интеллекту.
141. 8 компаний, которые отлично используют машинное обучение
 Когда его спросили, какой совет он дал бы мировым лидерам, Илон Маск ответил: «Внедрите протокол для контроля над развитием искусственного интеллекта».
Когда его спросили, какой совет он дал бы мировым лидерам, Илон Маск ответил: «Внедрите протокол для контроля над развитием искусственного интеллекта».
142. Краткое введение в машинное обучение с помощью Dagster
 Эта статья представляет собой краткое введение в Dagster с использованием небольшого проекта машинного обучения. Он удобен для новичков, но может подойти и более продвинутым программистам, если они не знают Dagster.
Эта статья представляет собой краткое введение в Dagster с использованием небольшого проекта машинного обучения. Он удобен для новичков, но может подойти и более продвинутым программистам, если они не знают Dagster.
143. Библиотека Python или реализация с нуля: 7 вещей, на которые стоит обратить внимание
 Вопрос о реализации с нуля или библиотеке Python возникает время от времени, независимо от цели вашего проекта.
Вопрос о реализации с нуля или библиотеке Python возникает время от времени, независимо от цели вашего проекта.
144. MIDAS: современная модель обнаружения аномалий в графах
 В сфере машинного обучения такие актуальные темы, как беспилотные транспортные средства, GAN и распознавание лиц, часто занимают большую часть внимания средств массовой информации. Однако еще одна не менее важная проблема, над решением которой работают специалисты по обработке данных, — это обнаружение аномалий. От сетевой безопасности до финансового мошенничества — обнаружение аномалий помогает защитить предприятия, частных лиц и интернет-сообщества. Чтобы улучшить обнаружение аномалий, исследователи разработали новый подход под названием MIDAS.
В сфере машинного обучения такие актуальные темы, как беспилотные транспортные средства, GAN и распознавание лиц, часто занимают большую часть внимания средств массовой информации. Однако еще одна не менее важная проблема, над решением которой работают специалисты по обработке данных, — это обнаружение аномалий. От сетевой безопасности до финансового мошенничества — обнаружение аномалий помогает защитить предприятия, частных лиц и интернет-сообщества. Чтобы улучшить обнаружение аномалий, исследователи разработали новый подход под названием MIDAS.
145. MongoDB: изучение инструментов и методов визуализации данных
 Ищете инструмент визуализации данных MongoDB? Вариантов много, но сначала лучше изучить, какие решения существуют на рынке.
Ищете инструмент визуализации данных MongoDB? Вариантов много, но сначала лучше изучить, какие решения существуют на рынке.
146. COVID-19: предполагаемое распространение и истинное распространение в Китае, Италии и США
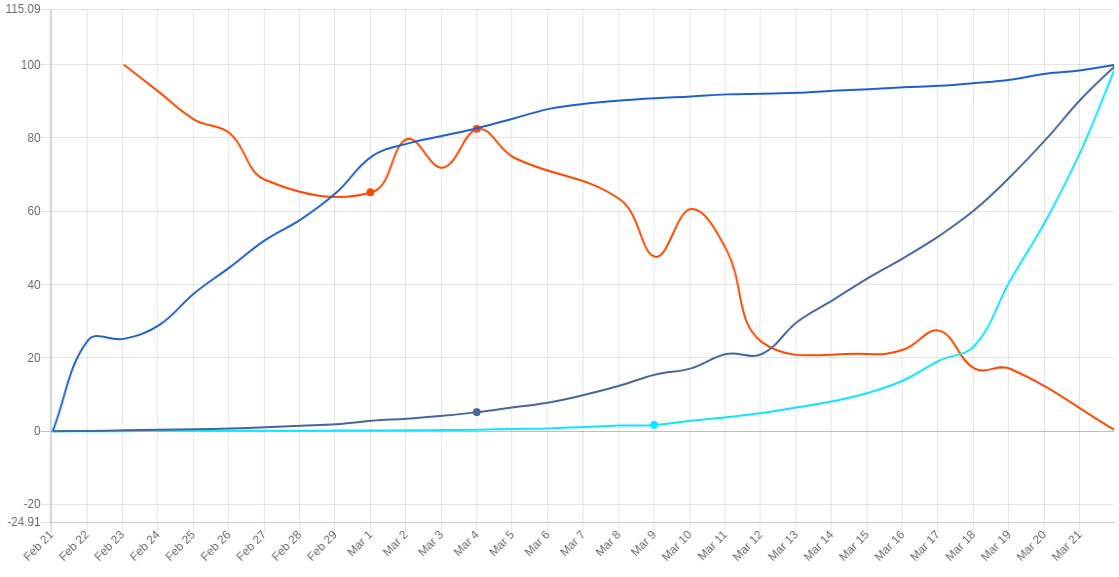 Здесь, в TimeNet, мы создаем большую базу данных временных рядов с основной целью принести пользу обществу за счет доступа к данным. В этом посте мы изучим различные временные ряды, отражающие как истинное, так и предполагаемое распространение пандемии коронавируса (COVID-19). Ежедневные данные о COVID-19 в настоящее время доступны на TimeNet.cloud для многих стран. Мы расширяем эти наборы данных дополнительными переменными, измеряющими то, как мы (люди) воспринимаем значимость пандемии. Для количественной оценки предполагаемого распространения вируса мы используем динамику фондового рынка и тенденции поиска в Интернете.
Здесь, в TimeNet, мы создаем большую базу данных временных рядов с основной целью принести пользу обществу за счет доступа к данным. В этом посте мы изучим различные временные ряды, отражающие как истинное, так и предполагаемое распространение пандемии коронавируса (COVID-19). Ежедневные данные о COVID-19 в настоящее время доступны на TimeNet.cloud для многих стран. Мы расширяем эти наборы данных дополнительными переменными, измеряющими то, как мы (люди) воспринимаем значимость пандемии. Для количественной оценки предполагаемого распространения вируса мы используем динамику фондового рынка и тенденции поиска в Интернете.
147. Как я освоил Python в режиме самоизоляции, не потратив ни копейки
 Я всегда хотел научиться программированию. Написание кодов, создание алгоритмов всегда волновало меня. Будучи инженером-механиком, меня никогда подробно не учили этим предметам.
Я всегда хотел научиться программированию. Написание кодов, создание алгоритмов всегда волновало меня. Будучи инженером-механиком, меня никогда подробно не учили этим предметам.
148. Как визуализировать смещение и дисперсию
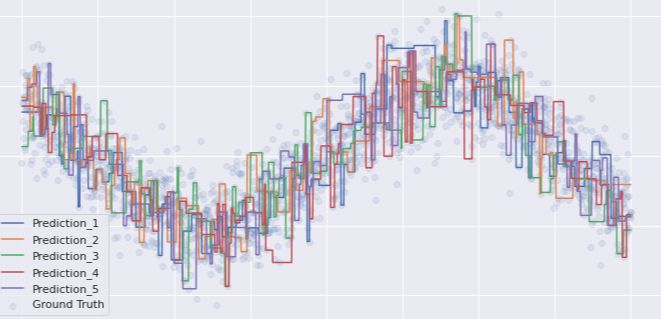 В процессе построения модели машинного обучения приходится искать компромисс между предвзятостью и дисперсией.
В процессе построения модели машинного обучения приходится искать компромисс между предвзятостью и дисперсией.
149. Внутреннее письмо Тиму Куку и состоянию бизнес-аналитики
 Мы получаем представление о внутренней работе ценной компании, и оказывается, что не все так радужно и солнечно.
Мы получаем представление о внутренней работе ценной компании, и оказывается, что не все так радужно и солнечно.
150. 9 бесплатных курсов по науке о данных и amp; Руководства для начинающих
 Мы, люди, очень сильно зависим от цифровых и интеллектуальных устройств. И все эти устройства создают данные с очень высокой скоростью. Согласно статье Forbes, более 90% мировых данных было создано за последние 2–3 года.
Мы, люди, очень сильно зависим от цифровых и интеллектуальных устройств. И все эти устройства создают данные с очень высокой скоростью. Согласно статье Forbes, более 90% мировых данных было создано за последние 2–3 года.
151. Как этот проект Web3 открывает экономику данных стоимостью в триллион долларов с помощью NFT данных
 Узнайте, почему данные могут стать самой многообещающей утилитой NFT, которая закладывает основу для ценного тренда: Data Finance (DataFi).
Узнайте, почему данные могут стать самой многообещающей утилитой NFT, которая закладывает основу для ценного тренда: Data Finance (DataFi).
152. Улучшите свои маркетинговые кампании с помощью науки о данных
 Сегодня по каждому из ваших видов деятельности получено множество данных. Простая рассылка электронной почты нескольким тысячам получателей генерирует данные, относящиеся к показателям открываемости, рейтингу кликов и конверсии. Эти данные можно дополнительно проанализировать, чтобы получить конкретную информацию о демографических характеристиках аудитории, которая находит ваше сообщение привлекательным, строках темы, которые побуждают пользователя открывать ваши электронные письма, эффективных призывах к действию и т. д.
Сегодня по каждому из ваших видов деятельности получено множество данных. Простая рассылка электронной почты нескольким тысячам получателей генерирует данные, относящиеся к показателям открываемости, рейтингу кликов и конверсии. Эти данные можно дополнительно проанализировать, чтобы получить конкретную информацию о демографических характеристиках аудитории, которая находит ваше сообщение привлекательным, строках темы, которые побуждают пользователя открывать ваши электронные письма, эффективных призывах к действию и т. д.
153. Как построить и развернуть модель НЛП с помощью FastAPI: часть 1
 Узнайте, как построить модель НЛП и развернуть ее с помощью быстрой веб-платформы для создания API под названием FastAPI.
Узнайте, как построить модель НЛП и развернуть ее с помощью быстрой веб-платформы для создания API под названием FastAPI.
154. 9 лучших стажировок в области машинного обучения, искусственного интеллекта и анализа данных в 2022 году
 Вот 9 лучших стажировок в области машинного обучения, искусственного интеллекта и науки о данных, которые стоит рассмотреть на 2022 год, если вы хотите попасть в любую из этих очень прибыльных областей информатики.
Вот 9 лучших стажировок в области машинного обучения, искусственного интеллекта и науки о данных, которые стоит рассмотреть на 2022 год, если вы хотите попасть в любую из этих очень прибыльных областей информатики.
155. Как создать проект обработки данных Python с помощью шаблона конвейера
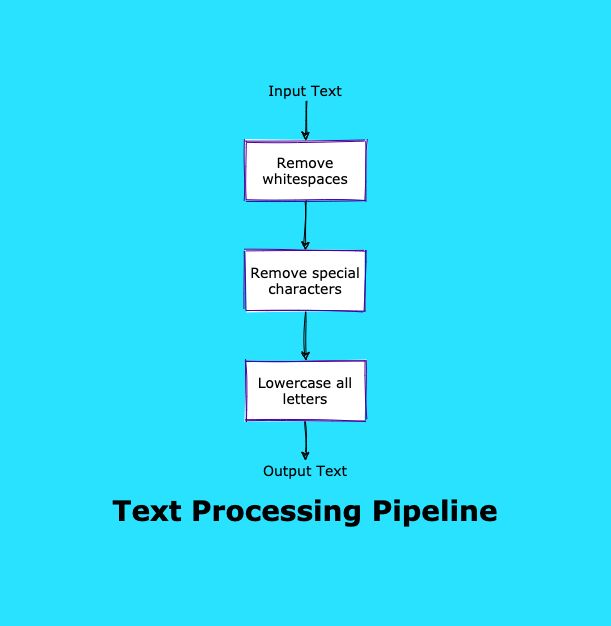 В этой статье мы расскажем, как использовать шаблоны конвейеров в проектах разработки данных Python. Создайте функциональный конвейер, установите fastcore и выполните другие действия.
В этой статье мы расскажем, как использовать шаблоны конвейеров в проектах разработки данных Python. Создайте функциональный конвейер, установите fastcore и выполните другие действия.
156. Как использовать приблизительную перекрестную проверку с исключением одного для построения лучших моделей
 Как использовать приблизительную перекрестную проверку с исключением одного для оптимизации гиперпараметров и обнаружения выбросов для логистической регрессии и гребневой регрессии
Как использовать приблизительную перекрестную проверку с исключением одного для оптимизации гиперпараметров и обнаружения выбросов для логистической регрессии и гребневой регрессии
157. 3 новых стартапа, внедряющих инновационную технологию анализа данных DeFi
 Анализ данных в целом является одной из важнейших отраслей. Теперь, когда DeFi превратилась в полноценную индустрию, потребность в ценном анализе данных растет.
Анализ данных в целом является одной из важнейших отраслей. Теперь, когда DeFi превратилась в полноценную индустрию, потребность в ценном анализе данных растет.
158. 5 лучших профессий в сфере технологий, на которые стоит обратить внимание в 2021 году
 Получите доступ к ИТ, обладая знаниями в области науки о данных, инженерии, облачных вычислений, кибербезопасности или DevOps.
Получите доступ к ИТ, обладая знаниями в области науки о данных, инженерии, облачных вычислений, кибербезопасности или DevOps.
159. Использование науки о данных в электронной коммерции: 7 проектов, которые стоит попробовать
 Как вы, интернет-продавец, можете улучшить свой бизнес? Конечно, за счет улучшения качества обслуживания клиентов. Компания электронной коммерции должна хорошо понимать следующие факторы:
Как вы, интернет-продавец, можете улучшить свой бизнес? Конечно, за счет улучшения качества обслуживания клиентов. Компания электронной коммерции должна хорошо понимать следующие факторы:
160. Разрушительные последствия незапланированной работы

161. Пошаговое руководство по провалу проекта по науке о данных
 Как утверждал Лев Толстой в своей плодотворной работе «Анна Каренина»: «Все счастливые семьи похожи друг на друга; каждая несчастливая семья несчастлива по-своему». Аналогичным образом, все успешные проекты по науке о данных проходят очень похожий процесс построения, хотя существует множество разных способов провалить проект по науке о данных. Однако я решил подготовить подробное руководство для ученых, работающих с данными, которые хотят быть уверенными, что их проект обернется 100% катастрофой.
Как утверждал Лев Толстой в своей плодотворной работе «Анна Каренина»: «Все счастливые семьи похожи друг на друга; каждая несчастливая семья несчастлива по-своему». Аналогичным образом, все успешные проекты по науке о данных проходят очень похожий процесс построения, хотя существует множество разных способов провалить проект по науке о данных. Однако я решил подготовить подробное руководство для ученых, работающих с данными, которые хотят быть уверенными, что их проект обернется 100% катастрофой.
162. Как предсказать результаты выборов с помощью Twitter
 Выборы играют решающую роль во всех демократических странах, и социальные сети являются важным аспектом в этом процессе. В настоящее время политические партии все чаще полагаются на платформы социальных сетей, такие как Twitter и Facebook, для политической коммуникации. Использование социальных сетей в политических маркетинговых кампаниях резко возросло за последние несколько лет. Ожидается, что он станет еще более важным для будущих политических кампаний, поскольку создает двустороннюю связь и взаимодействие, которые стимулируют и укрепляют отношения кандидатов со своими сторонниками.
Выборы играют решающую роль во всех демократических странах, и социальные сети являются важным аспектом в этом процессе. В настоящее время политические партии все чаще полагаются на платформы социальных сетей, такие как Twitter и Facebook, для политической коммуникации. Использование социальных сетей в политических маркетинговых кампаниях резко возросло за последние несколько лет. Ожидается, что он станет еще более важным для будущих политических кампаний, поскольку создает двустороннюю связь и взаимодействие, которые стимулируют и укрепляют отношения кандидатов со своими сторонниками.
163. Covid-19: анализ распространения среди населения

164. 5 типов алгоритмов машинного обучения, которые вам следует знать
 Машинное обучение стало разнообразным бизнес-инструментом, позволяющим улучшить различные элементы бизнес-операций. Кроме того, это оказывает существенное влияние на эффективность бизнеса. Алгоритмы машинного обучения широко используются для поддержания конкуренции с различными отраслями. Однако существует другой тип алгоритмов для целей и наборов данных. Выбор алгоритма зависит от роли пользователя и цели. Если вы используете линейную регрессию, вы можете быстро реализовать или обучить другие алгоритмы машинного обучения. Но недостатком этого алгоритма является то, что он неприменим для сложных прогнозов. Поэтому вам следует знать о различных типах алгоритмов машинного обучения, чтобы получить лучшие результаты.
Машинное обучение стало разнообразным бизнес-инструментом, позволяющим улучшить различные элементы бизнес-операций. Кроме того, это оказывает существенное влияние на эффективность бизнеса. Алгоритмы машинного обучения широко используются для поддержания конкуренции с различными отраслями. Однако существует другой тип алгоритмов для целей и наборов данных. Выбор алгоритма зависит от роли пользователя и цели. Если вы используете линейную регрессию, вы можете быстро реализовать или обучить другие алгоритмы машинного обучения. Но недостатком этого алгоритма является то, что он неприменим для сложных прогнозов. Поэтому вам следует знать о различных типах алгоритмов машинного обучения, чтобы получить лучшие результаты.
165. Как мыслить как специалист по данным или аналитик данных
166. Используйте plaidML для машинного обучения на macOS с графическим процессором AMD
 Хотите обучать модели машинного обучения на встроенном графическом процессоре AMD или внешней видеокарте вашего Mac? Не ищите ничего, кроме PlaidML.
Хотите обучать модели машинного обучения на встроенном графическом процессоре AMD или внешней видеокарте вашего Mac? Не ищите ничего, кроме PlaidML.
167. Естественный язык во всех отношениях лучше SQL
 С незапамятных времен люди общались посредством жестов, рисунков, дыма или речи. Со временем в жизнь человека проник язык структурированных запросов (SQL), благодаря которому мы смогли общаться с базами данных. Однако пришло время вернуться к нашему естественному языку и переосмыслить то, как мы общаемся с нашими данными.
С незапамятных времен люди общались посредством жестов, рисунков, дыма или речи. Со временем в жизнь человека проник язык структурированных запросов (SQL), благодаря которому мы смогли общаться с базами данных. Однако пришло время вернуться к нашему естественному языку и переосмыслить то, как мы общаемся с нашими данными.
168. Могут ли графовые нейронные сети решать реальные проблемы?
 В этой статье мы узнаем о GNN и их структуре, а также о приложениях
В этой статье мы узнаем о GNN и их структуре, а также о приложениях
169. Магия машинного обучения: как ускорить автономный вывод для больших наборов данных
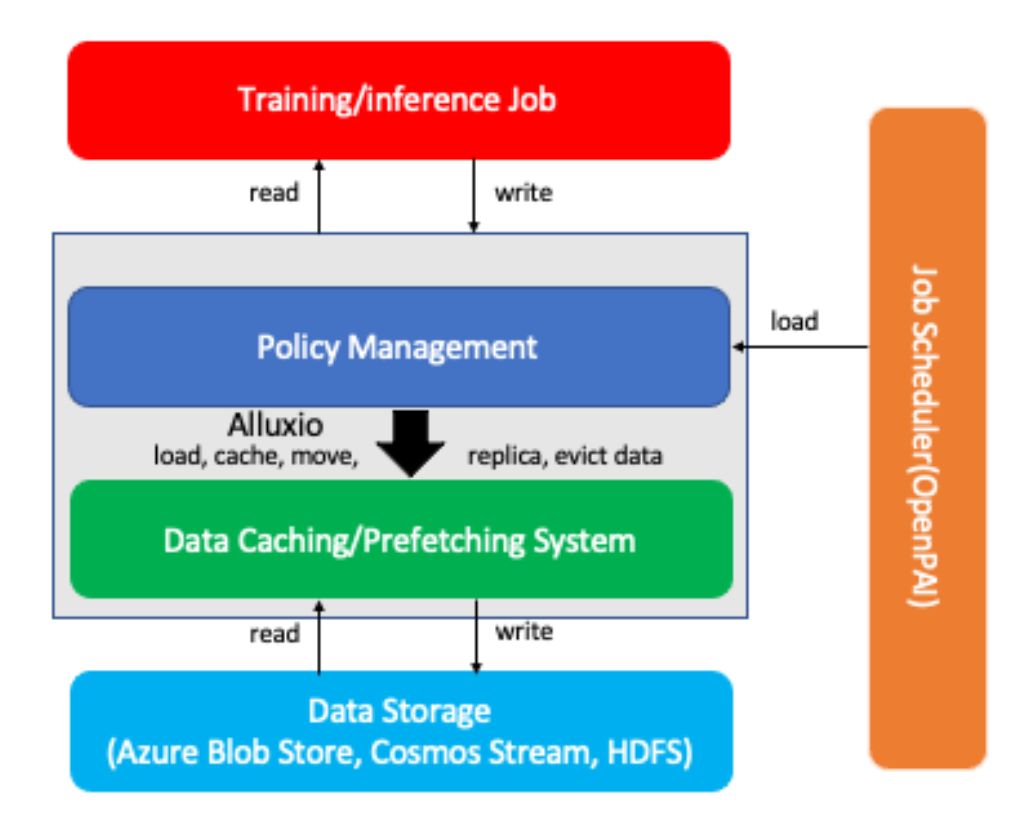 Выполнение выводов в масштабе является сложной задачей. Посмотрите, как мы повышаем производительность ввода-вывода для крупномасштабных автономных заданий ML/DL.
Выполнение выводов в масштабе является сложной задачей. Посмотрите, как мы повышаем производительность ввода-вывода для крупномасштабных автономных заданий ML/DL.
170. Более 40 лучших вопросов на собеседовании по продуктам в области обработки данных
 Найдите более 40 лучших вопросов на собеседовании по продукту, которые вам нужно подготовить к следующему собеседованию по науке о данных.
Найдите более 40 лучших вопросов на собеседовании по продукту, которые вам нужно подготовить к следующему собеседованию по науке о данных.
171. 6 самых больших различий между Airbyte и Singer
 Нас спросили, создается ли Airbyte на базе Singer. Несмотря на то, что нам понравилась их первоначальная миссия, это не так. Протокол данных Aibyte будет совместим с протоколом Singer, так что вы сможете легко интегрировать и использовать краны Singer, но наш протокол будет во многом отличаться от их протокола.
Нас спросили, создается ли Airbyte на базе Singer. Несмотря на то, что нам понравилась их первоначальная миссия, это не так. Протокол данных Aibyte будет совместим с протоколом Singer, так что вы сможете легко интегрировать и использовать краны Singer, но наш протокол будет во многом отличаться от их протокола.
172. Уважаемые начинающие специалисты по данным: пропустите сертификаты, сделайте это вместо этого
 Если вы заходили в LinkedIn в течение последних нескольких месяцев, вы, вероятно, наткнулись на печально известную «сообщение о сертификации».
Если вы заходили в LinkedIn в течение последних нескольких месяцев, вы, вероятно, наткнулись на печально известную «сообщение о сертификации».
173. Как я разработал собственную степень по машинному обучению и искусственному интеллекту
 Заметив, что мои курсы программирования в колледже устарели, я начал этот год с того, что бросил колледж, чтобы самостоятельно изучать машинное обучение и искусственный интеллект с помощью онлайн-ресурсов. Не имея ни опыта работы в сфере технологий, ни предыдущих степеней, вот степень, которую я разработал в области машинного обучения и искусственного интеллекта от начала до конца, чтобы привести меня к моей цели — стать всесторонним инженером по машинному обучению и искусственному интеллекту.
Заметив, что мои курсы программирования в колледже устарели, я начал этот год с того, что бросил колледж, чтобы самостоятельно изучать машинное обучение и искусственный интеллект с помощью онлайн-ресурсов. Не имея ни опыта работы в сфере технологий, ни предыдущих степеней, вот степень, которую я разработал в области машинного обучения и искусственного интеллекта от начала до конца, чтобы привести меня к моей цели — стать всесторонним инженером по машинному обучению и искусственному интеллекту.
174. Торговые системы с возвратом к среднему и торговля криптовалютой [глубокий обзор]

175. 9 лучших бесплатных руководств по машинному обучению (ML) для начинающих
 В этом посте представлен обзор лучших бесплатных руководств по машинному обучению для начинающих.
В этом посте представлен обзор лучших бесплатных руководств по машинному обучению для начинающих.
176. 10 лучших наборов данных классификации изображений для проектов машинного обучения
 Чтобы помочь вам создавать модели распознавания объектов, модели распознавания сцен и многое другое, мы составили список лучших наборов данных для классификации изображений. Эти наборы данных различаются по объему и величине и могут подходить для различных случаев использования. Кроме того, наборы данных были разделены на следующие категории: медицинская визуализация, сельское хозяйство и распознавание сцены и другие.
Чтобы помочь вам создавать модели распознавания объектов, модели распознавания сцен и многое другое, мы составили список лучших наборов данных для классификации изображений. Эти наборы данных различаются по объему и величине и могут подходить для различных случаев использования. Кроме того, наборы данных были разделены на следующие категории: медицинская визуализация, сельское хозяйство и распознавание сцены и другие.
177. 3 типа аномалий при обнаружении аномалий
 Введение в обнаружение аномалий и его важность в машинном обучении
Введение в обнаружение аномалий и его важность в машинном обучении
178. Отсутствие кода пожирает мир
 Недавно Amazon выпустила новый инструмент под названием Honeycode, который позволяет клиентам быстро создавать мобильные и веб-приложения — без необходимости программирования. Это произошло через несколько месяцев после приобретения Google платформы для создания мобильных приложений без кода AppSheet. Хотя эти шаги многих удивили, они соответствуют более широкой тенденции, которую я наблюдал, которая усиливается во всех секторах, даже в условиях экономических потрясений.
Недавно Amazon выпустила новый инструмент под названием Honeycode, который позволяет клиентам быстро создавать мобильные и веб-приложения — без необходимости программирования. Это произошло через несколько месяцев после приобретения Google платформы для создания мобильных приложений без кода AppSheet. Хотя эти шаги многих удивили, они соответствуют более широкой тенденции, которую я наблюдал, которая усиливается во всех секторах, даже в условиях экономических потрясений.
179. Что такое RNN (рекуррентная нейронная сеть) в глубоком обучении?
 RNN – одна из популярных нейронных сетей, которая обычно используется для решения задач обработки естественного языка.
RNN – одна из популярных нейронных сетей, которая обычно используется для решения задач обработки естественного языка.
180 . Старый статистический трюк может помочь лучше объяснить очевидную корреляцию между биткойнами и золотом
 Отношения между Биткойном и золотом — это одна из динамик, которая, кажется, постоянно занимает умы финансовых аналитиков. Недавно появилась серия новых статей, в которых утверждается растущая «корреляция» между Биткойном и золотом, и это явление, кажется, постоянно обсуждается в финансовых средствах массовой информации, таких как CNBC или Bloomberg.
Отношения между Биткойном и золотом — это одна из динамик, которая, кажется, постоянно занимает умы финансовых аналитиков. Недавно появилась серия новых статей, в которых утверждается растущая «корреляция» между Биткойном и золотом, и это явление, кажется, постоянно обсуждается в финансовых средствах массовой информации, таких как CNBC или Bloomberg.
181. Как я создал интерактивное веб-приложение информационной панели для визуализации данных бокса
 Я большой поклонник единоборств, особенно бокс. Хотя это может показаться чисто физическим видом спорта, где ваша единственная цель — либо перебоксировать, либо нокаутировать противника, он гораздо более стратегический, чем можно было бы ожидать, и включает в себя элемент психологии. Как и в шахматной игре, каждый нанесенный удар должен быть рассчитан: безрассудное перенапряжение может сделать вас более уязвимым для ответного удара, а чрезмерная пассивность и защита могут изменить ситуацию в пользу вашего противника и не принести вам достаточно очков для победы в бою. . Если вы позволите неуверенности в себе проникнуть в вас или будете напуганы противником, вы уже проиграли битву. Помимо всего этого, вам необходимо сохранять уважение к спорту и опасностям, которые он представляет. Как сказал Шугар Рэй Леонард: «В бокс не играешь».
Я большой поклонник единоборств, особенно бокс. Хотя это может показаться чисто физическим видом спорта, где ваша единственная цель — либо перебоксировать, либо нокаутировать противника, он гораздо более стратегический, чем можно было бы ожидать, и включает в себя элемент психологии. Как и в шахматной игре, каждый нанесенный удар должен быть рассчитан: безрассудное перенапряжение может сделать вас более уязвимым для ответного удара, а чрезмерная пассивность и защита могут изменить ситуацию в пользу вашего противника и не принести вам достаточно очков для победы в бою. . Если вы позволите неуверенности в себе проникнуть в вас или будете напуганы противником, вы уже проиграли битву. Помимо всего этого, вам необходимо сохранять уважение к спорту и опасностям, которые он представляет. Как сказал Шугар Рэй Леонард: «В бокс не играешь».
182. 8 лучших конференций по искусственному интеллекту, которые стоит посетить в 2022 году
 Вот полный список лучших конференций по искусственному интеллекту, которые стоит посетить в 2022 году: от самых технических до бизнес-ориентированных и академических.
Вот полный список лучших конференций по искусственному интеллекту, которые стоит посетить в 2022 году: от самых технических до бизнес-ориентированных и академических.
183 . Обучение модели трансформатора NER с помощью всего нескольких строк кода с помощью spaCy 3
 Модели-трансформеры стали, безусловно, новейшим достижением в технологии НЛП, и их применение варьируется от NER, классификации текста и ответов на вопросы.
Модели-трансформеры стали, безусловно, новейшим достижением в технологии НЛП, и их применение варьируется от NER, классификации текста и ответов на вопросы.
184. Руководство для специалистов по обработке данных по полуконтролируемому обучению
 Обучение с полуконтролем — это тип машинного обучения, о котором обычно не говорят специалисты по науке о данных и машинному обучению, но который по-прежнему играет очень важную роль.
Обучение с полуконтролем — это тип машинного обучения, о котором обычно не говорят специалисты по науке о данных и машинному обучению, но который по-прежнему играет очень важную роль.
185. Преимущества и недостатки больших данных
 Большие данные могут показаться любым другим модным словом в бизнесе, но важно понимать, какую пользу большие данные приносят компании и насколько они ограничены.
Большие данные могут показаться любым другим модным словом в бизнесе, но важно понимать, какую пользу большие данные приносят компании и насколько они ограничены.
186. Линейная регрессия и ее математическая реализация
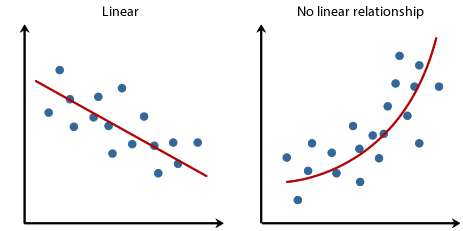 Что такое линейная регрессия?
Что такое линейная регрессия?
187. Машинное обучение без кода в Google Таблицах
 Введение
Введение
188. Pynecone: веб-приложения на чистом Python
 Pynecone — это платформа с открытым исходным кодом для создания веб-приложений на чистом Python и их развертывания с помощью одной команды.
Pynecone — это платформа с открытым исходным кодом для создания веб-приложений на чистом Python и их развертывания с помощью одной команды.
189. Технология блокчейн улучшает аутентификацию и прозрачность данных в здравоохранении
 Блокчейн – это секрет доверия к данным при их перемещении в нашу экосистему здравоохранения.
Блокчейн – это секрет доверия к данным при их перемещении в нашу экосистему здравоохранения.
190. Набор данных и увеличение данных для обнаружения и распознавания лиц
 Когда дело доходит до создания приложения искусственного интеллекта (ИИ), ваш подход должен быть в первую очередь данными, а не приложением.
Когда дело доходит до создания приложения искусственного интеллекта (ИИ), ваш подход должен быть в первую очередь данными, а не приложением.
191. Озера данных: новая модель хранения данных
 Озера данных быстро заменяют старые варианты хранения, такие как озера данных и хранилища. Прочтите об истории и преимуществах озер данных.
Озера данных быстро заменяют старые варианты хранения, такие как озера данных и хранилища. Прочтите об истории и преимуществах озер данных.
192. Попрощайтесь с SEO – ChatGPT привлекает внимание благодаря более умному поиску
 Поисковая оптимизация (SEO) уже более двух десятилетий является основой онлайн-поиска. Но поскольку технология искусственного интеллекта (ИИ) развивается быстро
Поисковая оптимизация (SEO) уже более двух десятилетий является основой онлайн-поиска. Но поскольку технология искусственного интеллекта (ИИ) развивается быстро
193. Как извлечь наборы данных НЛП с YouTube
 Лень самому парсить данные nlp? В этом посте я покажу вам быстрый способ парсинга наборов данных НЛП с помощью Youtube и Python.
Лень самому парсить данные nlp? В этом посте я покажу вам быстрый способ парсинга наборов данных НЛП с помощью Youtube и Python.
194. 5 лучших компаний по анализу настроений и инструментов для машинного обучения
 Ищете компании, занимающиеся анализом настроений, или инструменты для аннотации настроений? Если да, то вы попали по адресу. В этом руководстве кратко объясняется, что такое анализ настроений, а также представлены компании, предоставляющие инструменты и услуги для аннотации настроений.
Ищете компании, занимающиеся анализом настроений, или инструменты для аннотации настроений? Если да, то вы попали по адресу. В этом руководстве кратко объясняется, что такое анализ настроений, а также представлены компании, предоставляющие инструменты и услуги для аннотации настроений.
195. Как создать систему поиска изображений для поиска похожих изображений
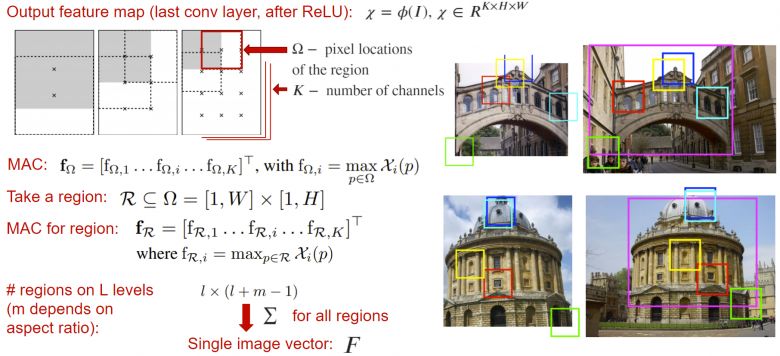 Прочитав эту статью, вы сможете с нуля создать поисковую систему по похожим изображениям для вашей цели
Прочитав эту статью, вы сможете с нуля создать поисковую систему по похожим изображениям для вашей цели
196. 16 методов SQL, которые должен знать каждый новичок
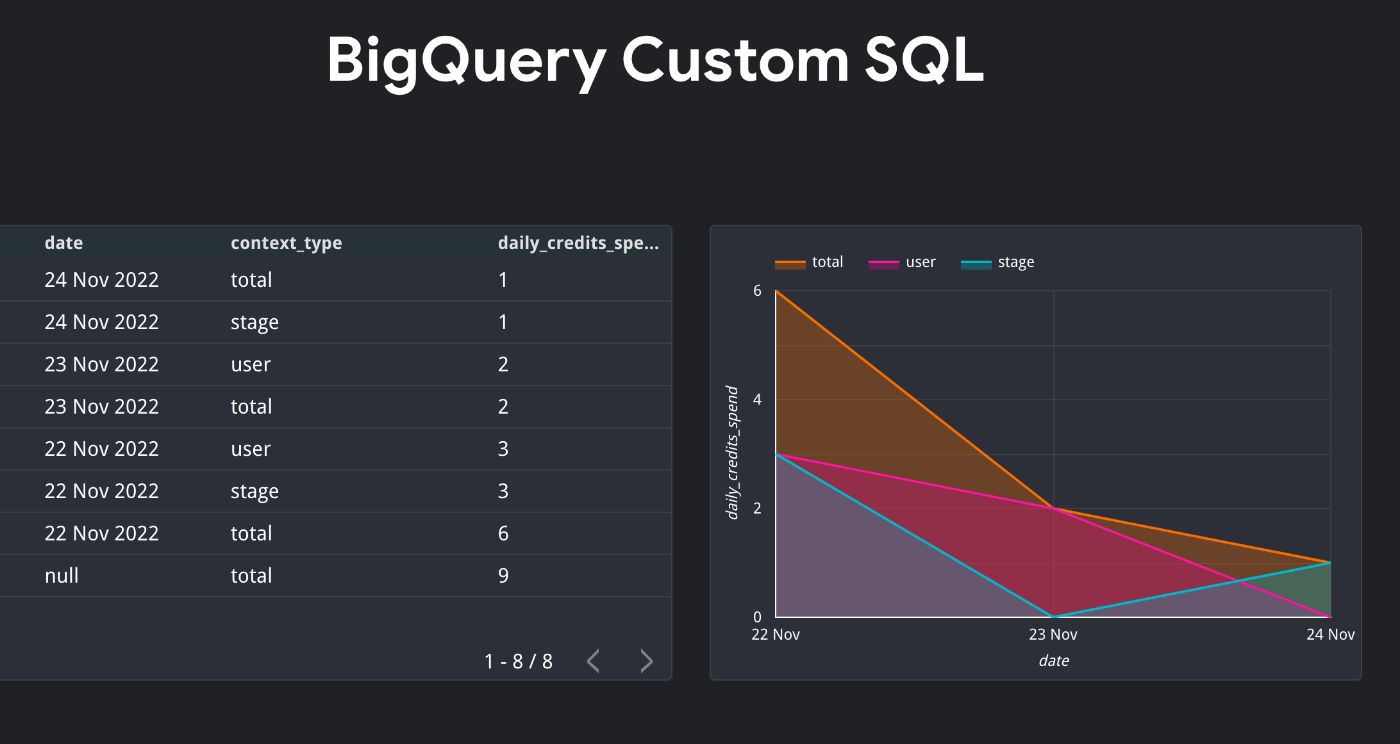 В этом сообщении блога подробно описаны самые сложные методы SQL для хранилища данных.
В этом сообщении блога подробно описаны самые сложные методы SQL для хранилища данных.
197. Представляем новости машинного обучения
 Я знаю.
Я знаю.
198. 10 лучших наборов данных об обнимающихся лицах для построения моделей НЛП
 Hugging Face предлагает решения и инструменты для разработчиков и исследователей. В этой статье рассматриваются лучшие наборы данных обнимающихся лиц для построения моделей НЛП.
Hugging Face предлагает решения и инструменты для разработчиков и исследователей. В этой статье рассматриваются лучшие наборы данных обнимающихся лиц для построения моделей НЛП.
199. Почему ноутбуки Jupyter — это будущее науки о данных
 Как Jupyter Notebooks сыграли важную роль в невероятном росте популярности науки о данных и почему за ними будущее.
Как Jupyter Notebooks сыграли важную роль в невероятном росте популярности науки о данных и почему за ними будущее.
200. Советы по разработке программного обеспечения: программирование для начинающих и не только
 На этой неделе в разделе «Истории недели» HackerNoon мы рассмотрели три статьи, которые охватывали мир разработки программного обеспечения: от трудоустройства до безопасности.
На этой неделе в разделе «Истории недели» HackerNoon мы рассмотрели три статьи, которые охватывали мир разработки программного обеспечения: от трудоустройства до безопасности.
201. Deepmind, возможно, только что создал первый в мире универсальный искусственный интеллект
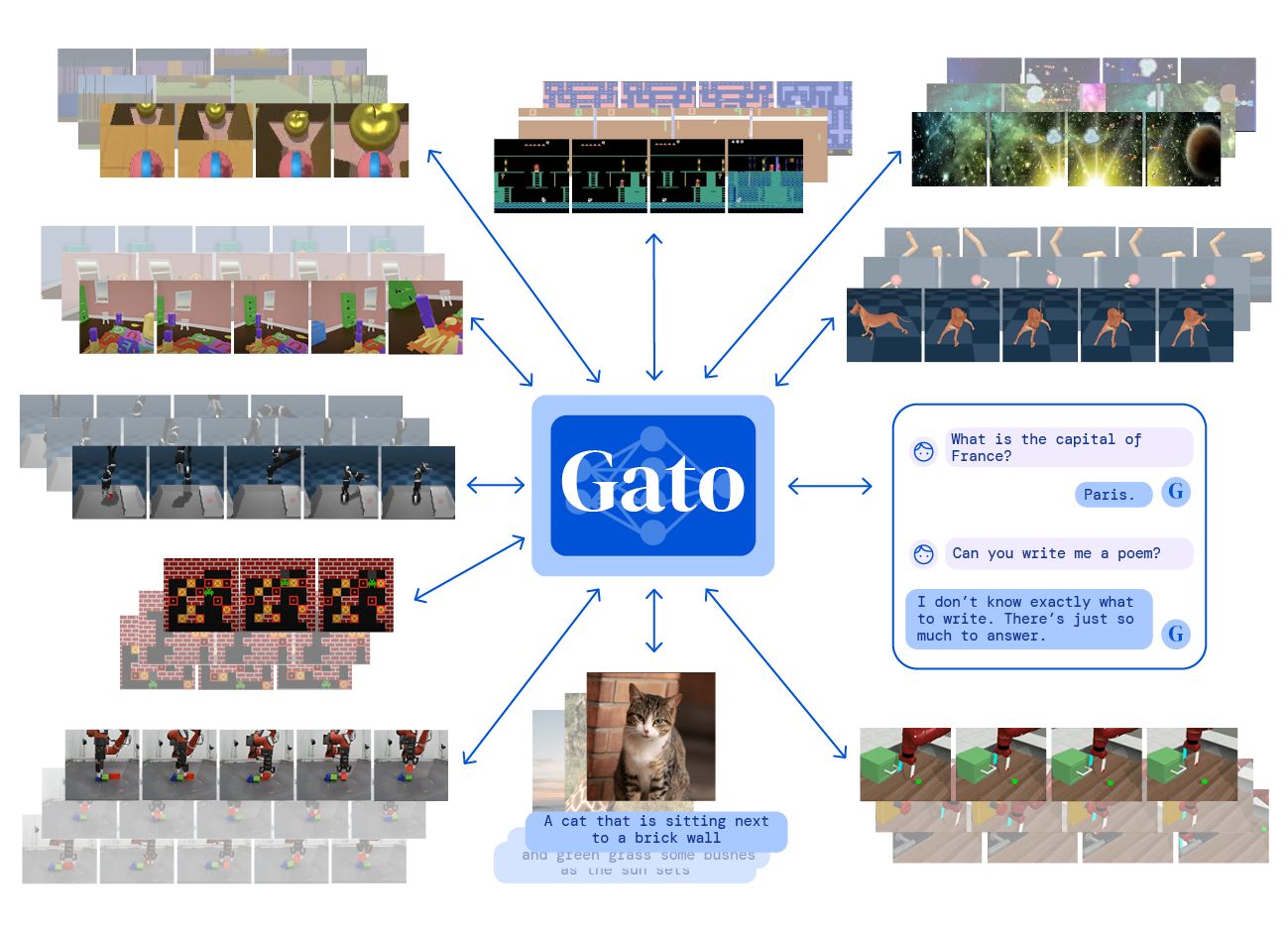 Только что был опубликован Гато из DeepMind! Это единственный трансформер, который может играть в игры Atari, подписывать изображения, общаться с людьми, управлять настоящей роботизированной рукой и многое другое! Действительно, он тренируется один раз и использует одни и те же веса для выполнения всех этих задач. А по мнению Deepmind, это не только трансформер, но и агент. Вот что происходит, когда вы смешиваете «Трансформеры» с прогрессом в области многозадачных агентов обучения с подкреплением.
Только что был опубликован Гато из DeepMind! Это единственный трансформер, который может играть в игры Atari, подписывать изображения, общаться с людьми, управлять настоящей роботизированной рукой и многое другое! Действительно, он тренируется один раз и использует одни и те же веса для выполнения всех этих задач. А по мнению Deepmind, это не только трансформер, но и агент. Вот что происходит, когда вы смешиваете «Трансформеры» с прогрессом в области многозадачных агентов обучения с подкреплением.
202. Как ученые, работающие с данными, могут стать более конкурентоспособными
 Этот заголовок может показаться вам немного странным. В конце концов, если вы являетесь специалистом по данным в 2019 году, вы уже востребованы на рынке. Поскольку наука о данных оказывает огромное влияние на современный бизнес, спрос на экспертов DS растет. На момент написания этой статьи только в LinkedIn имеется 144 527 вакансий в области обработки данных.
Этот заголовок может показаться вам немного странным. В конце концов, если вы являетесь специалистом по данным в 2019 году, вы уже востребованы на рынке. Поскольку наука о данных оказывает огромное влияние на современный бизнес, спрос на экспертов DS растет. На момент написания этой статьи только в LinkedIn имеется 144 527 вакансий в области обработки данных.
203. 5 примеров использования ИИ, показывающих, как он меняет отрасль
 Хотя Интернет во многом облегчил работу страховых компаний, оставалось еще много проблем, требующих решения.
Хотя Интернет во многом облегчил работу страховых компаний, оставалось еще много проблем, требующих решения.
204. Как выбрать базу данных, соответствующую вашим требованиям
 Представьте себе: вы находитесь на собеседовании по проектированию системы и вам нужно выбрать базу данных для хранения, скажем, данных, связанных с заказами, в системе электронной коммерции. Ваши данные структурированы и должны быть согласованными, но шаблон запроса не соответствует стандартной реляционной базе данных. Вам нужно, чтобы ваши транзакции были изолированными, атомарными и все такое ACID… Но, Боже мой, они должны масштабироваться бесконечно, как Кассандра! Как же решить, какое решение для хранения выбрать? Ну, посмотрим!
Представьте себе: вы находитесь на собеседовании по проектированию системы и вам нужно выбрать базу данных для хранения, скажем, данных, связанных с заказами, в системе электронной коммерции. Ваши данные структурированы и должны быть согласованными, но шаблон запроса не соответствует стандартной реляционной базе данных. Вам нужно, чтобы ваши транзакции были изолированными, атомарными и все такое ACID… Но, Боже мой, они должны масштабироваться бесконечно, как Кассандра! Как же решить, какое решение для хранения выбрать? Ну, посмотрим!
205. Как создать многозначный классификатор НЛП с нуля
 Атака токсичных комментариев на конкуренцию Kaggle с помощью Fast.ai
Атака токсичных комментариев на конкуренцию Kaggle с помощью Fast.ai
206. Как обнаружить плагиат в тексте с помощью Python
 Введение
Введение
207. Мультиколлинеарность и ее важность в машинном обучении
 Мультиколлинеарность означает высокую корреляцию между двумя или более объясняющими переменными, то есть предикторами. Это может быть проблемой и при машинном обучении.
Мультиколлинеарность означает высокую корреляцию между двумя или более объясняющими переменными, то есть предикторами. Это может быть проблемой и при машинном обучении.
208. Прогнозирование временных рядов с помощью TensorFlow.js
 Получайте цены на акции из онлайн-API и делайте прогнозы с помощью рекуррентной нейронной сети. Долгосрочная краткосрочная память (LSTM) с платформой TensorFlow.js
Получайте цены на акции из онлайн-API и делайте прогнозы с помощью рекуррентной нейронной сети. Долгосрочная краткосрочная память (LSTM) с платформой TensorFlow.js
209. 3 вопроса о реальном SQL, которые задают во время технических собеседований

210. Графики в 2020-е годы: базы данных, платформы и эволюция знаний
 Графы и графы знаний — ключевые концепции и технологии 2020-х годов. Как они будут выглядеть и что дадут в будущем?
Графы и графы знаний — ключевые концепции и технологии 2020-х годов. Как они будут выглядеть и что дадут в будущем?
211. Как распознавать речь в Python
 В свободное время я пытаюсь создать свои собственные устройства для умного дома. Одна из функций, которая им понадобится, — это распознавание речи. Хотя я еще не уверен, как именно я хочу реализовать эту функцию, я подумал, что было бы интересно углубиться и изучить различные варианты. Первым, что я хотел попробовать, была библиотека SpeechRecognition.
В свободное время я пытаюсь создать свои собственные устройства для умного дома. Одна из функций, которая им понадобится, — это распознавание речи. Хотя я еще не уверен, как именно я хочу реализовать эту функцию, я подумал, что было бы интересно углубиться и изучить различные варианты. Первым, что я хотел попробовать, была библиотека SpeechRecognition.
212. DecentraMind для Web 3.0 или против него? — Интервью с Михаилом Даниели
 DecentraMind от Web 3.0 или для него? — интервью с Михаилом Даниели, визионером проекта и послом о будущем платформы и компании.
DecentraMind от Web 3.0 или для него? — интервью с Михаилом Даниели, визионером проекта и послом о будущем платформы и компании.
213. Почему Python лидирует в области анализа данных

214. «Наука о данных — это не математический навык, а жизненный навык»: номинант от Noonies Кирк Борн
 От астрофизики до науки о данных — вот история жизненного пути, связанного с моделированием Вселенной и других динамических объектов, движущихся в пространстве и времени.
От астрофизики до науки о данных — вот история жизненного пути, связанного с моделированием Вселенной и других динамических объектов, движущихся в пространстве и времени.
215. Создание красной команды искусственного интеллекта для решения проблем до того, как они начнутся
 Невероятные 87 % проектов в области обработки данных так и не реализуются.
Невероятные 87 % проектов в области обработки данных так и не реализуются.
216. Лучшие библиотеки, которые помогут вам в EDA: издание 2021 г.
 Исследовательский анализ данных (EDA) — это важный шаг в жизненном цикле проекта по науке о данных. Вот 10 лучших инструментов Python для EDA.
Исследовательский анализ данных (EDA) — это важный шаг в жизненном цикле проекта по науке о данных. Вот 10 лучших инструментов Python для EDA.
217. Как построить гистограмму гонок по случаям COVID-19 за 5 минут
 Использование новой версии Tableau 2020.1 и более поздних версий.
Использование новой версии Tableau 2020.1 и более поздних версий.
218. Выбор функций с помощью пакета Xverse
 Узнайте, как применять различные методы для выбора функций пакета Xverse.
Узнайте, как применять различные методы для выбора функций пакета Xverse.
219. Каково будущее разработчиков SQL в мире машинного обучения?
 Знаете ли вы, что к 2024 году мировой рынок машинного обучения, по оценкам, достигнет 30,6 миллиарда долларов? Этот чудесный рост является результатом повсеместного присутствия искусственного интеллекта и его популярного подмножества; машинное обучение.
Знаете ли вы, что к 2024 году мировой рынок машинного обучения, по оценкам, достигнет 30,6 миллиарда долларов? Этот чудесный рост является результатом повсеместного присутствия искусственного интеллекта и его популярного подмножества; машинное обучение.
220. Самый простой способ выполнить исследовательский анализ данных (EDA) с использованием кода Python
 EDA для анализа данных или визуализации данных очень важен. В нем дается краткое изложение и основные характеристики данных. Согласно опросу, специалисты по анализу данных тратят большую часть времени на выполнение задач EDA.
EDA для анализа данных или визуализации данных очень важен. В нем дается краткое изложение и основные характеристики данных. Согласно опросу, специалисты по анализу данных тратят большую часть времени на выполнение задач EDA.
221. Обучение с подкреплением: 10 реальных наград и усиление; Заявления о наказании
 В обучении с подкреплением (RL) агенты обучаются механизму вознаграждения и наказания. Агент вознаграждается за правильные действия и наказывается за неправильные. При этом агент пытается свести к минимуму неправильные действия и максимизировать правильные.
В обучении с подкреплением (RL) агенты обучаются механизму вознаграждения и наказания. Агент вознаграждается за правильные действия и наказывается за неправильные. При этом агент пытается свести к минимуму неправильные действия и максимизировать правильные.
222. Как поддерживать актуальность моделей машинного обучения
 Эффективные модели машинного обучения требуют высококачественных данных. И обучение вашей модели машинного обучения — это не единственный конечный этап вашего процесса. Даже после того, как вы развернете ее в производственной среде, вам, скорее всего, понадобится постоянный поток новых обучающих данных, чтобы обеспечить точность прогнозирования вашей модели с течением времени.
Эффективные модели машинного обучения требуют высококачественных данных. И обучение вашей модели машинного обучения — это не единственный конечный этап вашего процесса. Даже после того, как вы развернете ее в производственной среде, вам, скорее всего, понадобится постоянный поток новых обучающих данных, чтобы обеспечить точность прогнозирования вашей модели с течением времени.
223. Как работает сжатие данных LZ77
 Как работает формат ZIP?
Как работает формат ZIP?
224. Pycaret: более быстрый способ создания моделей машинного обучения
 Pycaret – это библиотека Python с открытым исходным кодом, предназначенная для автоматизации разработки моделей машинного обучения.
Pycaret – это библиотека Python с открытым исходным кодом, предназначенная для автоматизации разработки моделей машинного обучения.
225. #Разрушаем мифы: 10 заблуждений об искусственном интеллекте
 Сегодня заблуждения об искусственном интеллекте распространяются со скоростью лесного пожара.
Сегодня заблуждения об искусственном интеллекте распространяются со скоростью лесного пожара.
226. Отвечаем на вопросы о показателях на собеседованиях с менеджерами по продукту
 Собеседования с менеджерами по продукту обычно включают раздел, посвященный метрикам. Будучи специалистом по данным в Uber, я часто давал друзьям такие интервью или помогал им подготовиться к ним. Насколько я могу судить, разница между кандидатами, которые не справляются с метрическими вопросами, и теми, кто испытывает трудности, заключается в том, есть ли у них система, которую они могут применить.
Собеседования с менеджерами по продукту обычно включают раздел, посвященный метрикам. Будучи специалистом по данным в Uber, я часто давал друзьям такие интервью или помогал им подготовиться к ним. Насколько я могу судить, разница между кандидатами, которые не справляются с метрическими вопросами, и теми, кто испытывает трудности, заключается в том, есть ли у них система, которую они могут применить.
227. Мой опыт работы с PyCharm JetBrains IDE
 Я всегда хотел научиться программировать, но из-за своего графика не мог уделять этому достаточно времени. Благодаря Covid19 я начал свое путешествие по Python, которое началось недавно во время изоляции.
Я всегда хотел научиться программировать, но из-за своего графика не мог уделять этому достаточно времени. Благодаря Covid19 я начал свое путешествие по Python, которое началось недавно во время изоляции.
228. Заменит ли искусственный интеллект копирайтеров?
 Сегодня всем известно, что повсеместное внедрение ИИ приближается и приближается. С развитием технологий и растущим спросом на автоматизированные процессы в свое время наш мир изменится на наших глазах. Особенно во время нынешней пандемии люди осознали, насколько мощным может быть Интернет, прежде всего потому, что они могут работать круглосуточно и без выходных.
Сегодня всем известно, что повсеместное внедрение ИИ приближается и приближается. С развитием технологий и растущим спросом на автоматизированные процессы в свое время наш мир изменится на наших глазах. Особенно во время нынешней пандемии люди осознали, насколько мощным может быть Интернет, прежде всего потому, что они могут работать круглосуточно и без выходных.
229. 13 лучших наборов данных для практики Power BI
 В 2022 году Gartner назвал Microsoft Power BI лидером платформ бизнес-аналитики и аналитики. Это 13 лучших наборов данных для практики Power BI.
В 2022 году Gartner назвал Microsoft Power BI лидером платформ бизнес-аналитики и аналитики. Это 13 лучших наборов данных для практики Power BI.
230. Интервью с моими героями машинного обучения
 Мета-статья со ссылками на все интервью с моими героями машинного обучения: практиками, исследователями и кагглерами.
Мета-статья со ссылками на все интервью с моими героями машинного обучения: практиками, исследователями и кагглерами.
231. Почему аномалии данных важнее, чем вы думаете
 Странные аномалии легко раздражать, когда они обнаруживаются в чистых (или, возможно, не совсем чистых) наборах данных. За этим раздражением немедленно следует стремление отфильтровать их и двигаться дальше. Несмотря на то, что наличие чистых, хорошо подобранных наборов данных является важным шагом в процессе создания надежных моделей, следует сопротивляться желанию немедленно устранить все аномалии — при этом существует реальный риск выбросить ценную информацию, которая может привести к значительные улучшения в ваших моделях, продуктах или даже бизнес-процессах.
Странные аномалии легко раздражать, когда они обнаруживаются в чистых (или, возможно, не совсем чистых) наборах данных. За этим раздражением немедленно следует стремление отфильтровать их и двигаться дальше. Несмотря на то, что наличие чистых, хорошо подобранных наборов данных является важным шагом в процессе создания надежных моделей, следует сопротивляться желанию немедленно устранить все аномалии — при этом существует реальный риск выбросить ценную информацию, которая может привести к значительные улучшения в ваших моделях, продуктах или даже бизнес-процессах.
232. Тестирование данных для конвейеров машинного обучения с использованием Deepchecks, DagsHub и действий GitHub
 Полная настройка проекта машинного обучения с использованием контроля версий (также для данных с DVC), отслеживания экспериментов, глубокой проверки данных и действий GitHub
Полная настройка проекта машинного обучения с использованием контроля версий (также для данных с DVC), отслеживания экспериментов, глубокой проверки данных и действий GitHub
233. Обработка больших наборов данных стала быстрой и простой: библиотека Polars
 Обработка больших данных, например. Очистка, агрегирование или фильтрация выполняются невероятно быстро с помощью библиотеки фреймов данных Polars на Python благодаря ее дизайну.
Обработка больших данных, например. Очистка, агрегирование или фильтрация выполняются невероятно быстро с помощью библиотеки фреймов данных Polars на Python благодаря ее дизайну.
234. Насколько велики на самом деле БОЛЬШИЕ ДАННЫЕ?
 Если у вас есть ответ, мы будем рады услышать ваше мнение.
Если у вас есть ответ, мы будем рады услышать ваше мнение.
235. Введение в «Большие надежды», инструмент для анализа данных с открытым исходным кодом
 Это первый завершенный вебинар из серии «Большие надежды 101». Цель этого вебинара – показать вам, что нужно для успешного развертывания и запуска Great Expectations.
Это первый завершенный вебинар из серии «Большие надежды 101». Цель этого вебинара – показать вам, что нужно для успешного развертывания и запуска Great Expectations.
236. Использование реляционной базы данных для запроса неструктурированных данных
 Использование реляционной базы данных для поиска внутри неструктурированных данных
Использование реляционной базы данных для поиска внутри неструктурированных данных
237. 10 лучших наборов данных Reddit для НЛП и других проектов машинного обучения
 В этом посте я хотел поделиться списком наборов данных Reddit, который получил большую популярность в социальных сетях, когда был впервые опубликован.
В этом посте я хотел поделиться списком наборов данных Reddit, который получил большую популярность в социальных сетях, когда был впервые опубликован.
238. Где бесплатно изучить машинное и глубокое обучение

[239. Дифференциальная конфиденциальность с Tensorflow 2.0 : Многоклассовая классификация текста
Конфиденциальность](https://hackernoon.com/ Differential-privacy-with-tensorflow-20-multi-class-text-classification-privacy-yk7a37uh)
 Введение
Введение
240. DreamFusion: искусственный интеллект, генерирующий 3D-модели из текста
 DreamFusion – новая исследовательская модель Google, которая способна понять предложение настолько, чтобы создать его 3D-модель.
DreamFusion – новая исследовательская модель Google, которая способна понять предложение настолько, чтобы создать его 3D-модель.
241. Сводка новостей о машинном обучении: 6 основных статей об искусственном интеллекте за 2019 год

242 . Как использовать науку о данных, чтобы найти лучшее место в кинотеатре (часть I)

243. Полигональные данные: что это такое и как их можно использовать?
 В этом блоге рассказывается о полигональных данных, их преимуществах и о том, как они широко используются в геомаркетинге, картографии помещений и анализе мобильности в организациях.
В этом блоге рассказывается о полигональных данных, их преимуществах и о том, как они широко используются в геомаркетинге, картографии помещений и анализе мобильности в организациях.
244. Победите жару с помощью шпаргалки по машинному обучению
 Если вы новичок и только начали заниматься машинным обучением или даже программист среднего уровня, возможно, вы застряли в том, как решить эту проблему. С чего начать? и куда ты пойдешь дальше?
Если вы новичок и только начали заниматься машинным обучением или даже программист среднего уровня, возможно, вы застряли в том, как решить эту проблему. С чего начать? и куда ты пойдешь дальше?
245. 11 потрясающих (и тревожных) применений ИИ
 В течение многих лет ИИ рекламировался как следующая большая технология. Ожидалось, что он произведет революцию в сфере занятости и фактически уничтожит миллионы рабочих мест, но стал образцом сокращения рабочих мест. Несмотря на это, его принятие было все более хорошо встречено. Для технических экспертов это не было сюрпризом, учитывая широкий спектр вариантов использования.
В течение многих лет ИИ рекламировался как следующая большая технология. Ожидалось, что он произведет революцию в сфере занятости и фактически уничтожит миллионы рабочих мест, но стал образцом сокращения рабочих мест. Несмотря на это, его принятие было все более хорошо встречено. Для технических экспертов это не было сюрпризом, учитывая широкий спектр вариантов использования.
246. Основы машинного обучения: 10 списков, которые должен знать каждый специалист по данным
 Наука о данных, без сомнения, является «самой привлекательной» карьерой 21-го века, в которой работают люди с сильным интеллектуальным любопытством и техническими знаниями, способные извлекать ценную информацию из огромных объемов данных. Это помогает компаниям повысить ценность за счет повышения своей производительности, получения информации для более эффективного принятия решений и увеличения прибыли, и это лишь некоторые из них. Знания в области науки о данных желательны и полезны в различных отраслях.
Наука о данных, без сомнения, является «самой привлекательной» карьерой 21-го века, в которой работают люди с сильным интеллектуальным любопытством и техническими знаниями, способные извлекать ценную информацию из огромных объемов данных. Это помогает компаниям повысить ценность за счет повышения своей производительности, получения информации для более эффективного принятия решений и увеличения прибыли, и это лишь некоторые из них. Знания в области науки о данных желательны и полезны в различных отраслях.
247. Машинное обучение 101: как и с чего начать для начинающих
 В этом посте описано все, что вам понадобится для вашего путешествия в качестве новичка. Все ресурсы снабжены ссылками. Вам просто нужно Время и Ваша преданность делу.
В этом посте описано все, что вам понадобится для вашего путешествия в качестве новичка. Все ресурсы снабжены ссылками. Вам просто нужно Время и Ваша преданность делу.
248. Вопросы и ответы на собеседовании с BI-аналитиком: издание 2020 г.
 Почему вам следует подготовиться к вопросам на собеседовании с аналитиком BI?
Почему вам следует подготовиться к вопросам на собеседовании с аналитиком BI?
249. Лучшие шутки разработчиков 2019 года
 Программистам и разработчикам необходимо получать удовольствие от разработки. Независимо от того, насколько серьезна или сложна ситуация, всегда следует относиться к разработке программного обеспечения легкомысленно.
Программистам и разработчикам необходимо получать удовольствие от разработки. Независимо от того, насколько серьезна или сложна ситуация, всегда следует относиться к разработке программного обеспечения легкомысленно.
250. Предварительная обработка данных
 В основе машинного обучения лежит обработка данных. Ваши инструменты машинного обучения так же хороши, как и качество ваших данных. В этом блоге рассматриваются различные этапы очистки данных. Ваши данные должны пройти несколько этапов, прежде чем их можно будет использовать для прогнозирования.
В основе машинного обучения лежит обработка данных. Ваши инструменты машинного обучения так же хороши, как и качество ваших данных. В этом блоге рассматриваются различные этапы очистки данных. Ваши данные должны пройти несколько этапов, прежде чем их можно будет использовать для прогнозирования.
251. Как составить идеальное резюме для должности специалиста по анализу данных
 Хотите сделать резюме специалиста по данным более привлекательным для работодателей?
Хотите сделать резюме специалиста по данным более привлекательным для работодателей?
252. Выводы и цитаты крупнейшей в мире дискуссии Kaggle GrandMaster

253. Как структурировать проект PyTorch ML с помощью Google Colab и TensorBoard
 Давайте построим модный MNIST CNN в стиле PyTorch. Это подробное руководство о том, как структурировать проект PyTorch ML с нуля с помощью Google Colab и TensorBoard.
Давайте построим модный MNIST CNN в стиле PyTorch. Это подробное руководство о том, как структурировать проект PyTorch ML с нуля с помощью Google Colab и TensorBoard.
254. Энергия будущего: децентрализованные оракулы и ДНК Метавселенной
 За десятилетнюю историю технологии блокчейна и распределенного реестра (DLT) быстрое развитие привело к последовательному развитию возможностей децентрализованных финансовых платформ. По сегодняшним стандартам Биткойн имеет свои ограничения: он поддерживает передачу ценностей и хранение метаданных в рамках этих передач, но не более того. Со временем блока 10 минут и максимальным размером блока примерно четыре мегабайта он также чрезвычайно медленный по сравнению с новыми блокчейнами последних нескольких лет.
За десятилетнюю историю технологии блокчейна и распределенного реестра (DLT) быстрое развитие привело к последовательному развитию возможностей децентрализованных финансовых платформ. По сегодняшним стандартам Биткойн имеет свои ограничения: он поддерживает передачу ценностей и хранение метаданных в рамках этих передач, но не более того. Со временем блока 10 минут и максимальным размером блока примерно четыре мегабайта он также чрезвычайно медленный по сравнению с новыми блокчейнами последних нескольких лет.
255. Новая модель OPT от Meta — это GPT-3 с открытым исходным кодом
 Мы все слышали о GPT-3 и имеем четкое представление о его возможностях. Вы наверняка видели некоторые приложения, созданные специально для этой модели, о некоторых из которых я рассказывал в предыдущем видео об этой модели. GPT-3 — это модель, разработанная OpenAI, к которой вы можете получить доступ через платный API, но не имеете доступа к самой модели.
Мы все слышали о GPT-3 и имеем четкое представление о его возможностях. Вы наверняка видели некоторые приложения, созданные специально для этой модели, о некоторых из которых я рассказывал в предыдущем видео об этой модели. GPT-3 — это модель, разработанная OpenAI, к которой вы можете получить доступ через платный API, но не имеете доступа к самой модели.
256. Десять технологий будущего, которые (пока) не известны общественности
 CRISPR, Quantum, Графен, Smart Dust, Цифровые двойники, Метавселенная… Вы обо всем этом слышали. Видел это все. Прочитайте все это. Или у вас?
CRISPR, Quantum, Графен, Smart Dust, Цифровые двойники, Метавселенная… Вы обо всем этом слышали. Видел это все. Прочитайте все это. Или у вас?
257. Как ученые, работающие с данными, начинают автоматизировать свои задачи с помощью Python
 Введение в автоматизацию с помощью Python и три моих наиболее часто используемых фрагмента кода.
Введение в автоматизацию с помощью Python и три моих наиболее часто используемых фрагмента кода.
258. Факты об искусственном интеллекте, которые должен знать каждый разработчик: искусственный интеллект, вероятно, старше вас
 Шумиха вокруг ИИ быстро растет, поскольку большинство исследовательских компаний прогнозируют, что в будущем ИИ будет играть все более важную роль.
Шумиха вокруг ИИ быстро растет, поскольку большинство исследовательских компаний прогнозируют, что в будущем ИИ будет играть все более важную роль.
259. Как машинное обучение используется в астрономии
 Является ли астрономия наукой о данных?
Является ли астрономия наукой о данных?
260. 13 самых высокооплачиваемых технических вакансий Инженеры-программисты могут стремиться повысить свою зарплату

261. Как парсить веб-страницы с помощью Python, Snscrape & HarperDB
 Узнайте, как выполнять очистку веб-страниц в Твиттере с помощью библиотеки Python snsscrape и автоматически сохранять собранные данные в базе данных с помощью HarperDB.
Узнайте, как выполнять очистку веб-страниц в Твиттере с помощью библиотеки Python snsscrape и автоматически сохранять собранные данные в базе данных с помощью HarperDB.
262. Вспоминая о своих первых пяти месяцах работы в качестве автора ПО с открытым исходным кодом
 Это история о том, как я начал вносить свой вклад в открытый исходный код, а также три веские причины, почему вам тоже следует начать вносить свой вклад в открытый исходный код.
Это история о том, как я начал вносить свой вклад в открытый исходный код, а также три веские причины, почему вам тоже следует начать вносить свой вклад в открытый исходный код.
263. Переподготовка подходов к модели машинного обучения
 Переобучение модели машинного обучения, дрейф модели, различные способы выявления дрейфа модели, снижение производительности
Переобучение модели машинного обучения, дрейф модели, различные способы выявления дрейфа модели, снижение производительности
264. 10 лучших идей проектов по науке о данных на 2020 год

265. Приятный способ начать обучение науке о данных — это CS50
 Итак, вы хотите заняться наукой о данных
Итак, вы хотите заняться наукой о данных
266. Регрессионный анализ ожидаемой продолжительности жизни

267. Полное руководство по инструментам машинного обучения на AWS
 В этой статье мы рассмотрим каждый из инструментов машинного обучения, предлагаемых AWS, и поймем, какие проблемы они пытаются решить для своих клиентов.
В этой статье мы рассмотрим каждый из инструментов машинного обучения, предлагаемых AWS, и поймем, какие проблемы они пытаются решить для своих клиентов.
268. ИИ и МО: в чем разница?
 Узнайте разницу между искусственным интеллектом и машинным обучением на ярких примерах.
Узнайте разницу между искусственным интеллектом и машинным обучением на ярких примерах.
269. Почему 87 % проектов машинного обучения терпят неудачу
 Эта статья послужит уроком о шокирующих причинах катастрофы с внедрением ИИ. Мы видим новости о машинном обучении повсюду. Действительно, у машинного обучения есть большой потенциал. Согласно прогнозам Gartner, «до 2020 года 80% проектов ИИ останутся алхимией, управляемой волшебниками, чьи таланты не будут масштабироваться в организации», а в исследовании Transform 2019 компании VentureBeat предсказали, что 87% проектов ИИ никогда не дойдут до производства.< /п>
Эта статья послужит уроком о шокирующих причинах катастрофы с внедрением ИИ. Мы видим новости о машинном обучении повсюду. Действительно, у машинного обучения есть большой потенциал. Согласно прогнозам Gartner, «до 2020 года 80% проектов ИИ останутся алхимией, управляемой волшебниками, чьи таланты не будут масштабироваться в организации», а в исследовании Transform 2019 компании VentureBeat предсказали, что 87% проектов ИИ никогда не дойдут до производства.< /п>
270. Как создать интересный README для вашего проекта по науке о данных на Github
 Файл README — это самый первый элемент, который проверяют разработчики при доступе к вашему проекту Data Science, размещенному на GitHub. Каждый разработчик должен начать изучение своего проекта Data Science с чтения файла README. Там вы узнаете все, что им нужно знать, в том числе о том, как установить и использовать ваш проект, как внести свой вклад (если у них есть предложения по улучшению) и все остальное.
Файл README — это самый первый элемент, который проверяют разработчики при доступе к вашему проекту Data Science, размещенному на GitHub. Каждый разработчик должен начать изучение своего проекта Data Science с чтения файла README. Там вы узнаете все, что им нужно знать, в том числе о том, как установить и использовать ваш проект, как внести свой вклад (если у них есть предложения по улучшению) и все остальное.
271. Реализация алгоритма взвешенных случайных чисел с помощью JavaScript
 Алгоритм Weighted Random используется для отправки HTTP-запросов на серверы Nginx. В этой статье вы узнаете, как работает алгоритм взвешенного случайного выбора.
Алгоритм Weighted Random используется для отправки HTTP-запросов на серверы Nginx. В этой статье вы узнаете, как работает алгоритм взвешенного случайного выбора.
272. Как построить и развернуть модель НЛП с помощью FastAPI: часть 2
 Узнайте, как построить модель НЛП и развернуть ее с помощью быстрой веб-платформы для создания API под названием FastAPI.
Узнайте, как построить модель НЛП и развернуть ее с помощью быстрой веб-платформы для создания API под названием FastAPI.
273. Использование машинного обучения для рекомендации инвестиций в P2P-кредитование
 Представляем PeerVest: бесплатное приложение машинного обучения, которое поможет вам выбрать лучший пул кредитов с соотношением риска и вознаграждения.
Представляем PeerVest: бесплатное приложение машинного обучения, которое поможет вам выбрать лучший пул кредитов с соотношением риска и вознаграждения.
274. Как отказ от программирования может возродить ваши отношения с наукой о данных

275. О стремительном взлете специалистов по обработке данных с низким кодом
 Если вы еще не используете платформы low-code, то очень скоро это произойдет. Low-code помогает значительно ускорить сроки и снизить затраты
Если вы еще не используете платформы low-code, то очень скоро это произойдет. Low-code помогает значительно ускорить сроки и снизить затраты
276 . Мы создали карту коронавируса с данными о COVID-19 и ограничениями на поездки по всем странам
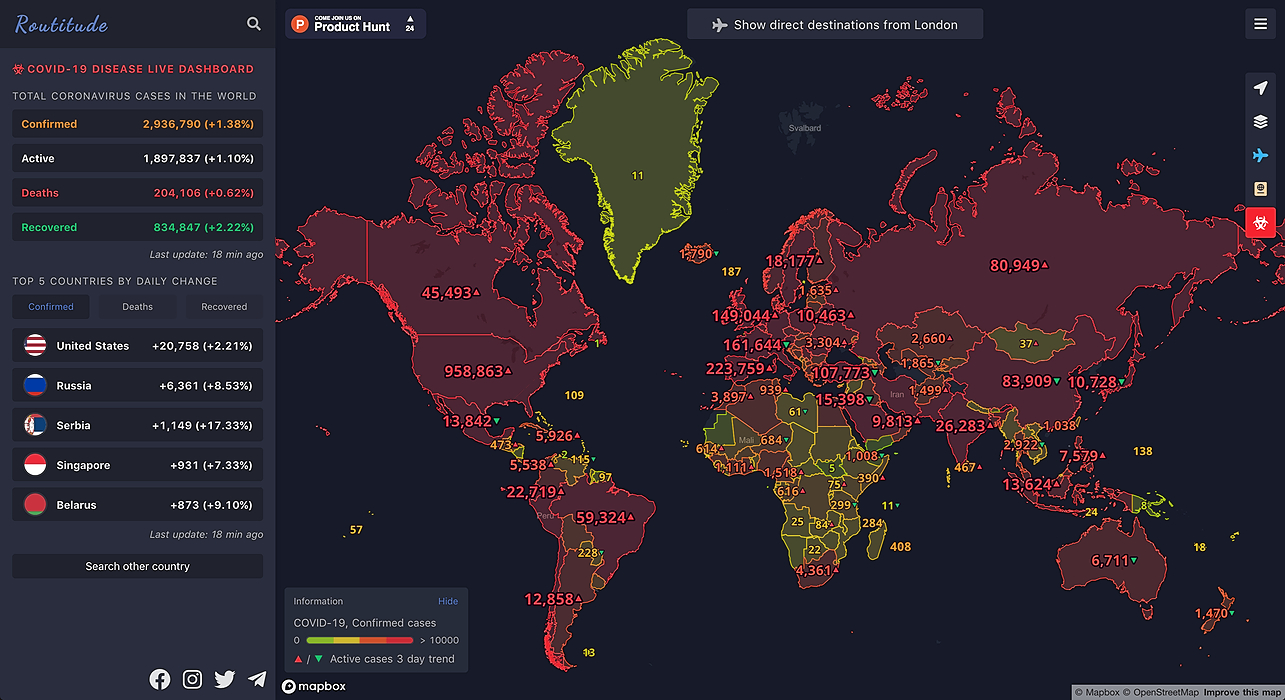 Еще в марте мы с товарищами по команде переключились с наших обычных задач по работе над туристической платформой на создание службы мониторинга COVID-19. Вот что нам удалось сделать на данный момент:
Еще в марте мы с товарищами по команде переключились с наших обычных задач по работе над туристической платформой на создание службы мониторинга COVID-19. Вот что нам удалось сделать на данный момент:
277. Внедрение предварительной обработки данных в наборе данных Титаника

278. Подход GAN к синтетическим данным временных рядов
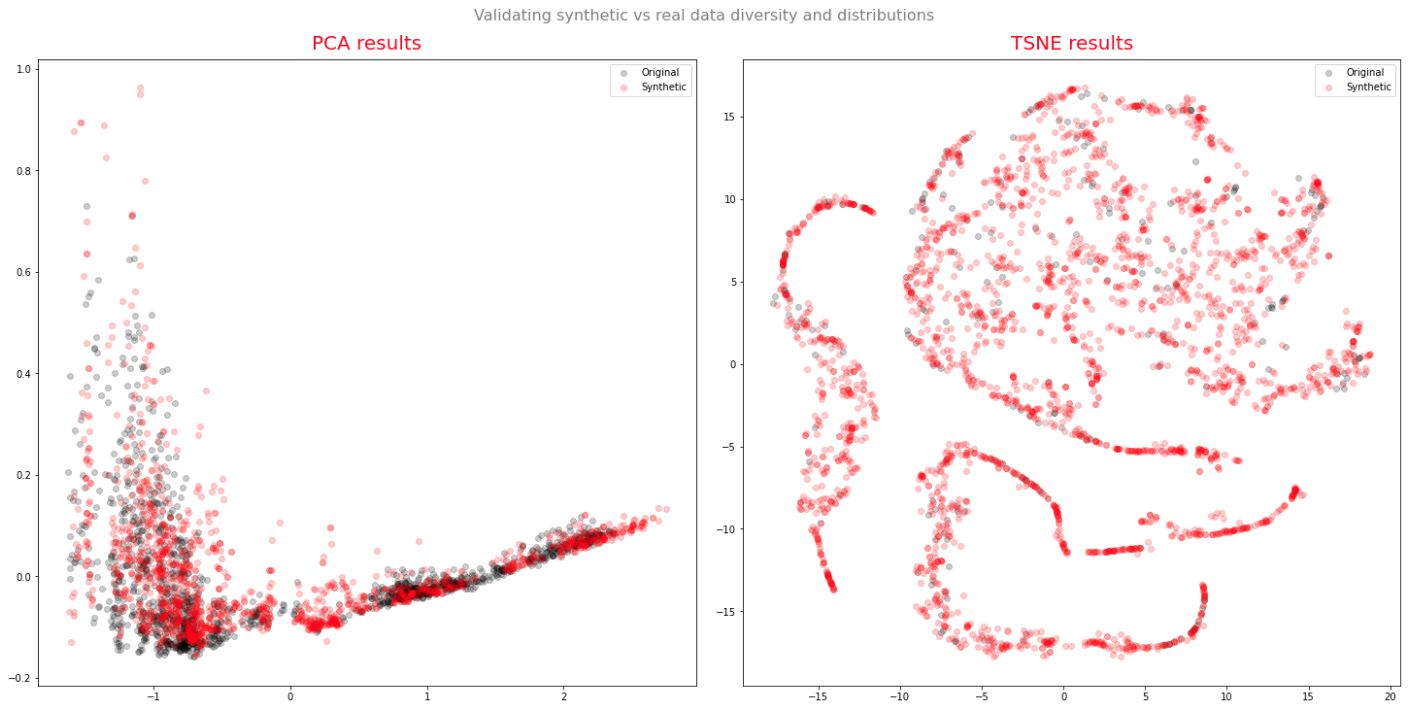 Хотя последовательные данные встречаются довольно часто и очень полезны, существует множество причин, по которым их не используют
Хотя последовательные данные встречаются довольно часто и очень полезны, существует множество причин, по которым их не используют
279. Как искусственный интеллект и роботы формируют здравоохранение
 Искусственный интеллект (ИИ), машинное обучение и наука о данных действительно начинают влиять на предоставление медицинских услуг. Мы видим это почти во всех важных видах деятельности: от планирования пациентов до оказания физической помощи в хирургических операциях.
Искусственный интеллект (ИИ), машинное обучение и наука о данных действительно начинают влиять на предоставление медицинских услуг. Мы видим это почти во всех важных видах деятельности: от планирования пациентов до оказания физической помощи в хирургических операциях.
280. Как развернуть метабазу на Google Cloud Platform (GCP)?
 Метабаза — это инструмент бизнес-аналитики для вашей организации, который подключает различные источники данных, чтобы вы могли исследовать данные и создавать информационные панели. Я постараюсь написать серию статей о том, как обеспечить и внедрить это для вашей организации. Эта статья о том, как быстро приступить к работе.
Метабаза — это инструмент бизнес-аналитики для вашей организации, который подключает различные источники данных, чтобы вы могли исследовать данные и создавать информационные панели. Я постараюсь написать серию статей о том, как обеспечить и внедрить это для вашей организации. Эта статья о том, как быстро приступить к работе.
281. Краудсорсинговая маркировка данных для проектов машинного обучения [Практическое руководство]

282. Увеличьте размер наборов данных за счет увеличения данных
 Доступ к обучающим данным является одним из крупнейших препятствий для многих проектов машинного обучения. К счастью, для различных проектов мы можем использовать увеличение данных, чтобы во много раз увеличить размер наших обучающих данных.
Доступ к обучающим данным является одним из крупнейших препятствий для многих проектов машинного обучения. К счастью, для различных проектов мы можем использовать увеличение данных, чтобы во много раз увеличить размер наших обучающих данных.
283. Квартет Анскомба и важность визуализации данных
 Квартет Анскомба состоит из четырех наборов данных, которые имеют почти идентичную простую описательную статистику, но имеют очень разные распределения и выглядят очень разными при построении графиков.
— Википедия
Квартет Анскомба состоит из четырех наборов данных, которые имеют почти идентичную простую описательную статистику, но имеют очень разные распределения и выглядят очень разными при построении графиков.
— Википедия
284. Почему проекты искусственного интеллекта терпят неудачу
 За последние несколько месяцев я заметил, что число проектов ИИ значительно возросло, и большинство людей, работающих над проектами ИИ в своих фирмах, планируют еще больше расширить свои инициативы в области ИИ в течение следующих 12 месяцев. Многие из этих инициатив связаны с большими ожиданиями, но проекты ИИ далеко не надежны. Фактически, есть прогнозы, что более половины всех проектов ИИ не оправдают ожиданий.
За последние несколько месяцев я заметил, что число проектов ИИ значительно возросло, и большинство людей, работающих над проектами ИИ в своих фирмах, планируют еще больше расширить свои инициативы в области ИИ в течение следующих 12 месяцев. Многие из этих инициатив связаны с большими ожиданиями, но проекты ИИ далеко не надежны. Фактически, есть прогнозы, что более половины всех проектов ИИ не оправдают ожиданий.
285. Байесовский мозг: ваш мозг — специалист по данным?
 Ваш мозг — специалист по данным? Да, согласно байесовской гипотезе мозга, ваш мозг — байесовский статистик. Позвольте мне объяснить.
Ваш мозг — специалист по данным? Да, согласно байесовской гипотезе мозга, ваш мозг — байесовский статистик. Позвольте мне объяснить.
286. Краткое изложение наиболее популярных методов синтеза текста в изображение с помощью Python
 Сравнительное исследование различных методов преобразования текста в изображение
Сравнительное исследование различных методов преобразования текста в изображение
287. Создание распознавателя рукописных цифр с использованием машины опорных векторов
 Распознавание рукописного ввода:
Распознавание рукописного ввода:
288. 5 лучших статей месяца об искусственном интеллекте

Вот пять лучших статей об искусственном интеллекте, опубликованных на Hackernoon за май.
289. Обнаружение мошенничества с кредитными картами с помощью машинного обучения: практический пример
 Руководство по машинному обучению, которое поможет выявить мошеннические транзакции по кредитным картам с помощью инструментария PyOD.
Руководство по машинному обучению, которое поможет выявить мошеннические транзакции по кредитным картам с помощью инструментария PyOD.
290. Запуск собственного алгоритма распознавания лиц на основе JavaScript [Практическое руководство]
 Распознавание лиц на основе JavaScript с помощью Face API и Docker.he
Распознавание лиц на основе JavaScript с помощью Face API и Docker.he
291. Краткое введение в Python Numpy для начинающих
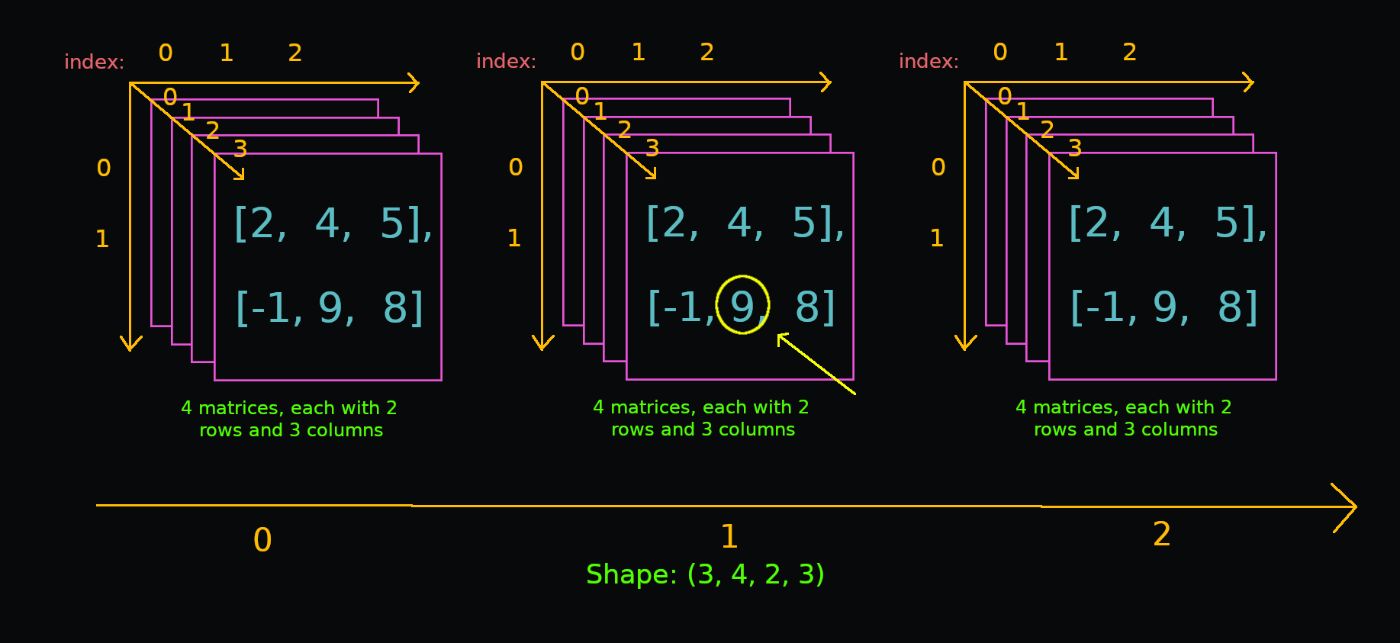 Это руководство поможет вам начать работу с NumPy, научив вас визуализировать многомерные массивы.
Это руководство поможет вам начать работу с NumPy, научив вас визуализировать многомерные массивы.
292. Важность проверки гипотез
 Проверка гипотез важна для оценки ответов на вопросы, касающиеся выборок данных.
Проверка гипотез важна для оценки ответов на вопросы, касающиеся выборок данных.
293. Я создал веб-приложение для прогнозирования бокса на Shiny, вот как
 В рамках моего учебного курса по изучению данных мне пришлось пройти несколько личных этапов. Для этого конкретного краеугольного камня я решил сосредоточиться на создании того, что лично меня волнует — какой лучший способ научиться и, возможно, создать что-то ценное, чем работа над любимым проектом.
В рамках моего учебного курса по изучению данных мне пришлось пройти несколько личных этапов. Для этого конкретного краеугольного камня я решил сосредоточиться на создании того, что лично меня волнует — какой лучший способ научиться и, возможно, создать что-то ценное, чем работа над любимым проектом.
294. Получите самые современные результаты работы с табличными данными с помощью глубокого обучения и amp; Встраивание слоев [Инструкция]
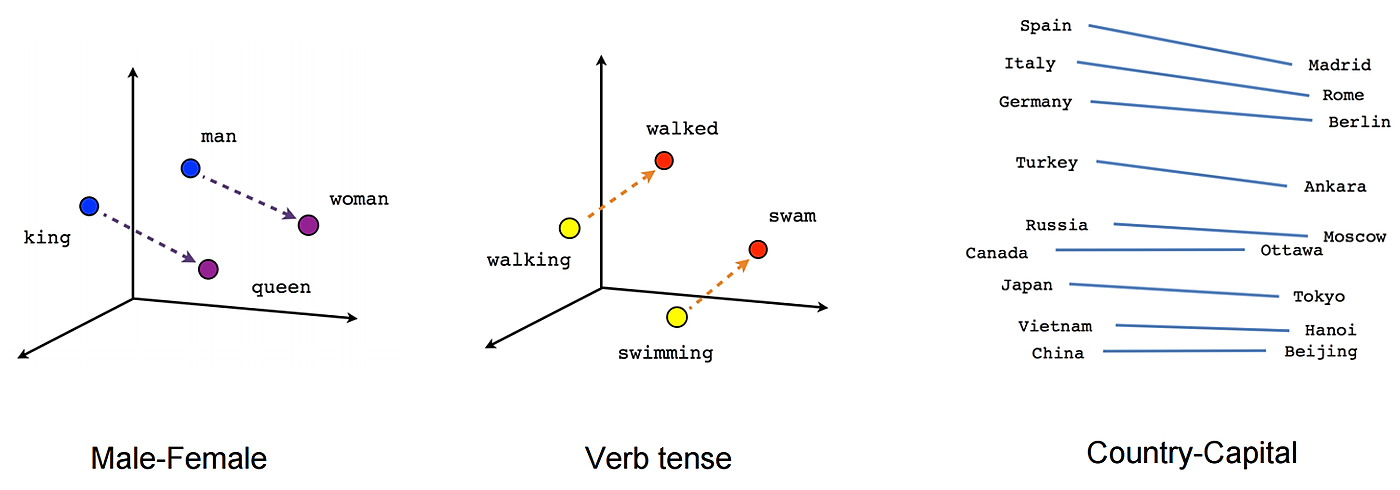 Древовидные модели, такие как Random Forest и XGBoost, стали очень популярными при решении задач с табличными (структурированными) данными и в последнее время получили широкое распространение на соревнованиях Kaggle. На это есть вполне достойные причины. Однако в этой статье я хочу представить подход, отличный от использования модуля Tabular в fast.ai.
Древовидные модели, такие как Random Forest и XGBoost, стали очень популярными при решении задач с табличными (структурированными) данными и в последнее время получили широкое распространение на соревнованиях Kaggle. На это есть вполне достойные причины. Однако в этой статье я хочу представить подход, отличный от использования модуля Tabular в fast.ai.
295. Использование Flask для создания чат-бота на основе правил на Python
 Научитесь создавать чат-ботов на базе искусственного интеллекта с помощью простого руководства, которое можно разместить в вашем портфолио.
Научитесь создавать чат-ботов на базе искусственного интеллекта с помощью простого руководства, которое можно разместить в вашем портфолио.
296. 7 шагов анализа данных, которые вам следует знать
 Для адекватного анализа данных необходимы практические знания различных форм анализа данных.
Для адекватного анализа данных необходимы практические знания различных форм анализа данных.
297. Реструктуризация или переработка: принятие правильных решений на основе данных
 Понимание разницы между данными о реструктуризации и переработке данных позволяет аналитикам принимать более обоснованные решения.
Понимание разницы между данными о реструктуризации и переработке данных позволяет аналитикам принимать более обоснованные решения.
298. 5 лучших книг по машинному обучению для начинающих
 Вот список лучших книг по изучению машинного обучения для начинающих, которые помогут построить карьеру в индустрии машинного обучения.
Вот список лучших книг по изучению машинного обучения для начинающих, которые помогут построить карьеру в индустрии машинного обучения.
299. Понимание применения SQL в науке о данных [глубокий обзор]
 Чтобы узнать о SQL, нам нужно понять, как работает СУБД. СУБД или система управления базами данных — это, по сути, программное обеспечение для создания баз данных и управления ими.
Чтобы узнать о SQL, нам нужно понять, как работает СУБД. СУБД или система управления базами данных — это, по сути, программное обеспечение для создания баз данных и управления ими.
300 . Разрушение мифов о науке о данных: «Вам нужна докторская степень, обширные навыки работы с Python и огромный опыт»
 DJ Патил и Джефф Хаммербахер придумали термин «ученый по данным», работая в LinkedIn и Facebook соответственно, и подразумевая человека, который «использует данные для взаимодействия с миром, изучает его и пытается придумать что-то новое».
DJ Патил и Джефф Хаммербахер придумали термин «ученый по данным», работая в LinkedIn и Facebook соответственно, и подразумевая человека, который «использует данные для взаимодействия с миром, изучает его и пытается придумать что-то новое».
301. Как использовать Streamlit и Python для создания приложения для обработки данных
 Веб-приложения по-прежнему являются полезными инструментами для специалистов по обработке и анализу данных, с помощью которых они могут представить пользователям свои проекты по обработке и анализу данных. Поскольку у нас может не быть навыков веб-разработки, мы можем использовать библиотеки Python с открытым исходным кодом, такие как Streamlit, чтобы легко разрабатывать веб-приложения за короткое время.
Веб-приложения по-прежнему являются полезными инструментами для специалистов по обработке и анализу данных, с помощью которых они могут представить пользователям свои проекты по обработке и анализу данных. Поскольку у нас может не быть навыков веб-разработки, мы можем использовать библиотеки Python с открытым исходным кодом, такие как Streamlit, чтобы легко разрабатывать веб-приложения за короткое время.
302. Переход от неспособности программировать к герою глубокого обучения

303. 👨🔬️ 10 лучших навыков специалиста по данным, которые нужно развивать, чтобы себя нанять
 Список 10 лучших навыков Data Scientist, гарантирующих трудоустройство. А также подборка полезных ресурсов для овладения этими навыками
Список 10 лучших навыков Data Scientist, гарантирующих трудоустройство. А также подборка полезных ресурсов для овладения этими навыками
304. Вакцины против гриппа: за ними стоит наука о данных
305. Введение в автоматизацию в Vision AI
 Уровни автоматизации аннотаций
Уровни автоматизации аннотаций
306. Почему вам следует прекратить занятия по чтению
 Изображение: Goodreads.com
Изображение: Goodreads.com
307. Обучение ваших моделей на облачных TPU за 4 простых шага в Google Colab
 У вас есть старая добрая модель TensorFlow, которая слишком затратна в вычислительном отношении, чтобы ее можно было обучать на обычном рабочем ноутбуке. Я понимаю. Я тоже был там, и, если честно, смотреть, как мой ноутбук ломается дважды подряд после попытки обучения на нем модели, больно смотреть.
У вас есть старая добрая модель TensorFlow, которая слишком затратна в вычислительном отношении, чтобы ее можно было обучать на обычном рабочем ноутбуке. Я понимаю. Я тоже был там, и, если честно, смотреть, как мой ноутбук ломается дважды подряд после попытки обучения на нем модели, больно смотреть.
308. Повышение производительности модели машинного обучения за счет объединения категориальных функций
 Узнайте, как объединить категориальные функции в наборе данных, чтобы повысить производительность модели машинного обучения.
Узнайте, как объединить категориальные функции в наборе данных, чтобы повысить производительность модели машинного обучения.
309. Что такое сверточные нейронные сети? [ELI5]
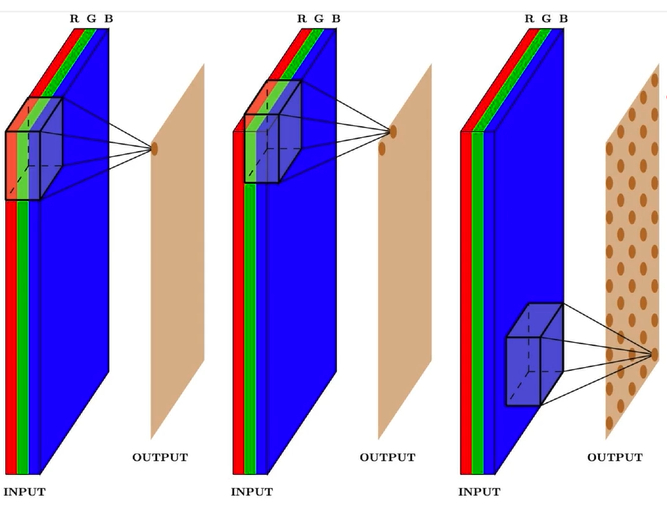 Теорема универсального приближения гласит, что нейронная сеть прямого распространения (также известная как многослойная сеть нейронов) может действовать как мощное приближение для изучения нелинейных отношений между входными и выходными данными. Но проблема нейронной сети с прямой связью заключается в том, что сеть склонна к переобучению из-за наличия в сети множества параметров, которые необходимо изучить.
Теорема универсального приближения гласит, что нейронная сеть прямого распространения (также известная как многослойная сеть нейронов) может действовать как мощное приближение для изучения нелинейных отношений между входными и выходными данными. Но проблема нейронной сети с прямой связью заключается в том, что сеть склонна к переобучению из-за наличия в сети множества параметров, которые необходимо изучить.
310. 5 компаний, разрабатывающих технологии компьютерного зрения в 2020 году
 Технология компьютерного зрения — это образец искусственного интеллекта. Именно этот сектор промышленности привлекает наибольшее внимание средств массовой информации из-за инструментов и преимуществ, которые могут предоставить технологии. От автономных транспортных средств и дронов до обнаружения рака и дополненной реальности — технологии, которые когда-то существовали только в научной фантастике, теперь находятся у нашего порога.
Технология компьютерного зрения — это образец искусственного интеллекта. Именно этот сектор промышленности привлекает наибольшее внимание средств массовой информации из-за инструментов и преимуществ, которые могут предоставить технологии. От автономных транспортных средств и дронов до обнаружения рака и дополненной реальности — технологии, которые когда-то существовали только в научной фантастике, теперь находятся у нашего порога.
311. Как я пришел в науку о данных
 Путь инженера-программиста в науку о данных в Yelp и Uber
Путь инженера-программиста в науку о данных в Yelp и Uber
312. Программирование от 8 до 80
 Существует ли язык программирования, который подойдет каждому пользователю от 8 до 80 лет? Держу пари! Это называется Smalltalk.
Существует ли язык программирования, который подойдет каждому пользователю от 8 до 80 лет? Держу пари! Это называется Smalltalk.
313. Стратегии обнаружения аномалий для датчиков Интернета вещей

314. Система обнаружения сонливости водителей: проект Python с исходным кодом
 Обнаружение сонливости – это технология безопасности, которая может предотвратить несчастные случаи по вине водителей, которые заснули за рулем.
Обнаружение сонливости – это технология безопасности, которая может предотвратить несчастные случаи по вине водителей, которые заснули за рулем.
315. 10 моделей централизованных криптобирж, объясненных с помощью машинного обучения и визуализации данных
 Централизованные криптобиржи — важнейший черный ящик криптоэкосистемы. Мы все ими пользуемся, у нас с ними отношения любви-ненависти, и мы очень мало понимаем их внутреннее поведение. В IntoTheBlock мы усердно работаем над серией моделей машинного обучения, которые помогают нам лучше понять внутреннюю структуру криптобирж. Недавно мы представили некоторые из наших первоначальных выводов на вебинаре, число подписчиков которого значительно превысило количество подписчиков, и я подумал, что некоторые идеи, обсуждавшиеся там, получат дальнейшее развитие.
Централизованные криптобиржи — важнейший черный ящик криптоэкосистемы. Мы все ими пользуемся, у нас с ними отношения любви-ненависти, и мы очень мало понимаем их внутреннее поведение. В IntoTheBlock мы усердно работаем над серией моделей машинного обучения, которые помогают нам лучше понять внутреннюю структуру криптобирж. Недавно мы представили некоторые из наших первоначальных выводов на вебинаре, число подписчиков которого значительно превысило количество подписчиков, и я подумал, что некоторые идеи, обсуждавшиеся там, получат дальнейшее развитие.
316. Как быстро и легко развернуть модели машинного обучения в облаке
 Модели машинного обучения обычно разрабатываются в среде обучения (онлайн или оффлайн). Затем вы можете развернуть их и использовать с живыми данными.
Модели машинного обучения обычно разрабатываются в среде обучения (онлайн или оффлайн). Затем вы можете развернуть их и использовать с живыми данными.
317. 20 лучших наборов данных Twitter для проектов машинного обучения
 Исследователям ИИ зачастую очень сложно собрать данные из социальных сетей для машинного обучения. К счастью, одним из бесплатных и доступных источников данных социальных сетей является Twitter.
Исследователям ИИ зачастую очень сложно собрать данные из социальных сетей для машинного обучения. К счастью, одним из бесплатных и доступных источников данных социальных сетей является Twitter.
318. Сравнение распознавания лиц с Java и C++ с использованием HOG
 HOG — гистограмма ориентированных градиентов (гистограмма ориентированных градиентов) — это формат дескриптора изображения, способный суммировать основные характеристики изображения, такие как лица, например, что позволяет сравнивать его с похожими изображениями.
HOG — гистограмма ориентированных градиентов (гистограмма ориентированных градиентов) — это формат дескриптора изображения, способный суммировать основные характеристики изображения, такие как лица, например, что позволяет сравнивать его с похожими изображениями.
319. Машинное обучение в кибербезопасности: 5 примеров из реальной жизни
 От картирования киберпреступлений в реальном времени до тестирования на проникновение — машинное обучение стало важной частью кибербезопасности. Вот как.
От картирования киберпреступлений в реальном времени до тестирования на проникновение — машинное обучение стало важной частью кибербезопасности. Вот как.
320. Знакомство с ноутбуками Jupiter
 «Ноутбуки» — это веб-приложения, которые запускаются в браузере и по сути предоставляют вам, пользователю, интерфейс к виртуальной машине, работающей в готовой среде. Они основаны на проекте Jupyter Notebook — проекте с открытым исходным кодом, который переносит возможности машинного обучения в ваш браузер! Больше никаких проблем с настройкой виртуальной среды. Это хорошая новость, поскольку многие разработчики хотят заниматься только проектами по науке о данных и не отвлекаться от этого из-за необходимости настраивать свои компьютеры.
«Ноутбуки» — это веб-приложения, которые запускаются в браузере и по сути предоставляют вам, пользователю, интерфейс к виртуальной машине, работающей в готовой среде. Они основаны на проекте Jupyter Notebook — проекте с открытым исходным кодом, который переносит возможности машинного обучения в ваш браузер! Больше никаких проблем с настройкой виртуальной среды. Это хорошая новость, поскольку многие разработчики хотят заниматься только проектами по науке о данных и не отвлекаться от этого из-за необходимости настраивать свои компьютеры.
321. 6 важных библиотек Python для машинного обучения и анализа данных
 В этом руководстве мы покажем самые необходимые библиотеки Python для машинного обучения и анализа данных.
В этом руководстве мы покажем самые необходимые библиотеки Python для машинного обучения и анализа данных.
322. Ансамбль Мстителей: как моделирование ансамбля помогает избежать переобучения
 Ансамблевое моделирование помогает избежать переобучения за счет уменьшения дисперсии в прогнозе и минимизации систематической ошибки метода моделирования.
Ансамблевое моделирование помогает избежать переобучения за счет уменьшения дисперсии в прогнозе и минимизации систематической ошибки метода моделирования.
323. Универсальный инструмент для работы с данными: новые аннотации скелета/позы/ориентира, голландский язык и параметры преобразования
 Для тех, кто не слышал об Universal Data Tool, это веб- или настольная программа с открытым исходным кодом для совместной работы, создания и редактирования наборов текстовых, изображений, видео и аудио данных с метками и аннотациями.
Для тех, кто не слышал об Universal Data Tool, это веб- или настольная программа с открытым исходным кодом для совместной работы, создания и редактирования наборов текстовых, изображений, видео и аудио данных с метками и аннотациями.
324. 5 вещей, на которые следует обратить внимание при внедрении Tableau BI

325. Введение в нейронные сети: CNN против RNN
 В машинном обучении каждый тип искусственной нейронной сети предназначен для определенных задач. В этой статье будут представлены два типа нейронных сетей: сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN). Используя популярные видеоролики и наглядные пособия на YouTube, мы объясним разницу между CNN и RNN и то, как они используются в компьютерном зрении и обработке естественного языка.
В машинном обучении каждый тип искусственной нейронной сети предназначен для определенных задач. В этой статье будут представлены два типа нейронных сетей: сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN). Используя популярные видеоролики и наглядные пособия на YouTube, мы объясним разницу между CNN и RNN и то, как они используются в компьютерном зрении и обработке естественного языка.
326. Идея проекта по науке о данных, которая впечатлит интервьюеров
 Давайте поговорим об одном-единственном проекте, который вам нужно создать, который поможет вам получить полный опыт в области науки о данных и произвести впечатление на интервьюеров на собеседованиях, если ваша цель — начать карьеру в области науки о данных.
Давайте поговорим об одном-единственном проекте, который вам нужно создать, который поможет вам получить полный опыт в области науки о данных и произвести впечатление на интервьюеров на собеседованиях, если ваша цель — начать карьеру в области науки о данных.
327. Как управлять продуктами машинного обучения [ Часть II]
 Лучшие практики и вещи, которые я узнал за время работы.
Лучшие практики и вещи, которые я узнал за время работы.
328. 6 важных советов по реализации проектов по науке о данных
 Проекты по науке о данных сосредоточены на решении социальных или бизнес-проблем с использованием данных. Решение проектов по науке о данных может оказаться очень сложной задачей для новичков в этой области. Вам потребуется различный набор навыков в зависимости от типа проблемы с данными, которую вы хотите решить.
Проекты по науке о данных сосредоточены на решении социальных или бизнес-проблем с использованием данных. Решение проектов по науке о данных может оказаться очень сложной задачей для новичков в этой области. Вам потребуется различный набор навыков в зависимости от типа проблемы с данными, которую вы хотите решить.
329. Не только искусственный интеллект: предоставление аналитики вашим клиентам
330. Наука о данных в финансах: 5 способов, которые изменили отрасль
 Какова роль науки о данных в финансах?
Какова роль науки о данных в финансах?
331. COVID-19: «Мы верим в Бога, все остальные должны предоставлять [ЧИСТЫЕ] данные»
 В эти трудные для всех нас дни я слышал всякое. От фейковых новостей, отправленных через Whatsapp, о том, что витамин С может спасти вашу жизнь, до задержки дыхания по утрам, чтобы проверить, не заразились ли вы COVID-19. Мантра, которую все повторяют: «Оставайся дома!», хорошо, хорошо, но что именно означает «оставайся дома»? Вопрос кажется смешным, если подумать об относительно коротком периоде, 15 днях? Месяц? Но если критически посмотреть на ситуацию, то мы наверняка понимаем, что это будет не 15 дней и не месяц. Это будет очень-очень долго. Почему я говорю это? Потому что «оставаться дома» не защищает нас от вируса. Оставаться дома – значит защитить наши медицинские учреждения от коллапса. И я не говорю, что это неправильно. Я просто говорю, что если мы хотим защитить систему здравоохранения от коллапса, то мы будем сидеть дома еще очень-очень долго. Но поступая так, мы нанесем непоправимый ущерб экономической системе, глубоко изменив нашу социальную и политическую модель. Это неизбежно. Давайте посмотрим правде в глаза и не будем питать слишком много иллюзий.
В эти трудные для всех нас дни я слышал всякое. От фейковых новостей, отправленных через Whatsapp, о том, что витамин С может спасти вашу жизнь, до задержки дыхания по утрам, чтобы проверить, не заразились ли вы COVID-19. Мантра, которую все повторяют: «Оставайся дома!», хорошо, хорошо, но что именно означает «оставайся дома»? Вопрос кажется смешным, если подумать об относительно коротком периоде, 15 днях? Месяц? Но если критически посмотреть на ситуацию, то мы наверняка понимаем, что это будет не 15 дней и не месяц. Это будет очень-очень долго. Почему я говорю это? Потому что «оставаться дома» не защищает нас от вируса. Оставаться дома – значит защитить наши медицинские учреждения от коллапса. И я не говорю, что это неправильно. Я просто говорю, что если мы хотим защитить систему здравоохранения от коллапса, то мы будем сидеть дома еще очень-очень долго. Но поступая так, мы нанесем непоправимый ущерб экономической системе, глубоко изменив нашу социальную и политическую модель. Это неизбежно. Давайте посмотрим правде в глаза и не будем питать слишком много иллюзий.
332. Уменьшение размерности с помощью PCA: комплексное практическое пособие
 Мы, люди, пользуемся услугами, специально разработанными специально для нас, лично нас это не беспокоит, но мы каждый день делаем одну вещь, которая как бы помогает этой интеллектуальной машине работать день и ночь, просто чтобы убедиться, что все эти услуги тщательно курируются и предоставляются нам так, как нам нравится их использовать.
Мы, люди, пользуемся услугами, специально разработанными специально для нас, лично нас это не беспокоит, но мы каждый день делаем одну вещь, которая как бы помогает этой интеллектуальной машине работать день и ночь, просто чтобы убедиться, что все эти услуги тщательно курируются и предоставляются нам так, как нам нравится их использовать.
333. Как создать действительно работающие алгоритмы машинного обучения
 Масштабное применение моделей машинного обучения в производстве может оказаться затруднительным. Вот четыре самые большие проблемы, с которыми сталкиваются команды по работе с данными, и способы их решения.
Масштабное применение моделей машинного обучения в производстве может оказаться затруднительным. Вот четыре самые большие проблемы, с которыми сталкиваются команды по работе с данными, и способы их решения.
334. Основные архитектуры для каждого специалиста по анализу данных и инженера по большим данным
 Полный список архитектур хранилищ функций для специалистов по обработке данных и специалистов по большим данным
Полный список архитектур хранилищ функций для специалистов по обработке данных и специалистов по большим данным
335. База данных, хранилище данных и озеро данных: простое объяснение
 Озеро данных полностью отличается от хранилища данных с точки зрения структуры и функций. Вот действительно краткое объяснение «Озера данных и Хранилища данных».
Озеро данных полностью отличается от хранилища данных с точки зрения структуры и функций. Вот действительно краткое объяснение «Озера данных и Хранилища данных».
336. Лучшие книги по машинному обучению, которые стоит прочитать: издание 2020 г.
 Эти книги охватывают знания и концепции машинного обучения от начального до экспертного уровня. В этих книгах изложены некоторые основные факторы, касающиеся ML. Дайте им попробовать. Начнем.
Эти книги охватывают знания и концепции машинного обучения от начального до экспертного уровня. В этих книгах изложены некоторые основные факторы, касающиеся ML. Дайте им попробовать. Начнем.
337. Деревья поведений в ИИ: почему вам следует отказаться от инфраструктуры событий
 В этой статье я рассматриваю некоторые недостатки событийно-ориентированной системы.
программирование и предлагать деревья поведения в качестве эффективной альтернативы,
подходит для внутренней и внешней разработки приложений.
В этой статье я рассматриваю некоторые недостатки событийно-ориентированной системы.
программирование и предлагать деревья поведения в качестве эффективной альтернативы,
подходит для внутренней и внешней разработки приложений.
338. Как создать пузырьковую карту с помощью JavaScript для визуализации результатов выборов
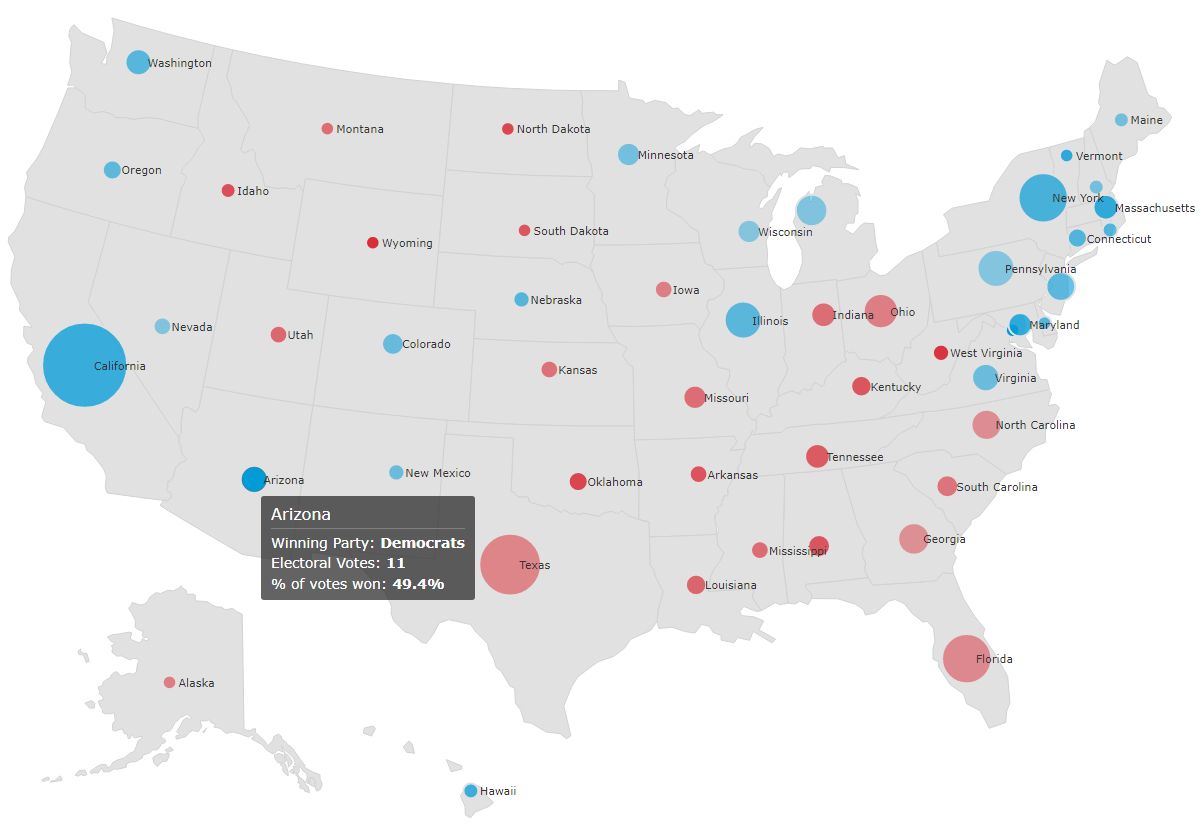 Учебное пособие для начинающих, позволяющее начать работу с визуализацией данных путем создания интересной и интуитивно понятной пузырьковой карты JavaScript
Учебное пособие для начинающих, позволяющее начать работу с визуализацией данных путем создания интересной и интуитивно понятной пузырьковой карты JavaScript
339. Лучшие каналы YouTube по искусственному интеллекту и машинному обучению, на которые стоит подписаться специалистам по данным
 Подпишитесь на эти каналы YouTube по машинному обучению сегодня и смотрите обучающие видеоролики по искусственному интеллекту, машинному обучению и информатике.
Подпишитесь на эти каналы YouTube по машинному обучению сегодня и смотрите обучающие видеоролики по искусственному интеллекту, машинному обучению и информатике.
340. Вводное руководство по обнаружению объектов в реальном времени с помощью Python

341. 23 распространенных вопроса на собеседовании по науке о данных для начинающих
 В 2012 году Harvard Business Review назвал специалистов по обработке данных самой сексуальной профессией XXI века. Однако правильно ответить на вопросы собеседования по науке о данных, чтобы получить работу специалиста по данным, очень сложно.
В 2012 году Harvard Business Review назвал специалистов по обработке данных самой сексуальной профессией XXI века. Однако правильно ответить на вопросы собеседования по науке о данных, чтобы получить работу специалиста по данным, очень сложно.
342. Как создать базового чат-бота без программирования и развернуть его на веб-сайтах
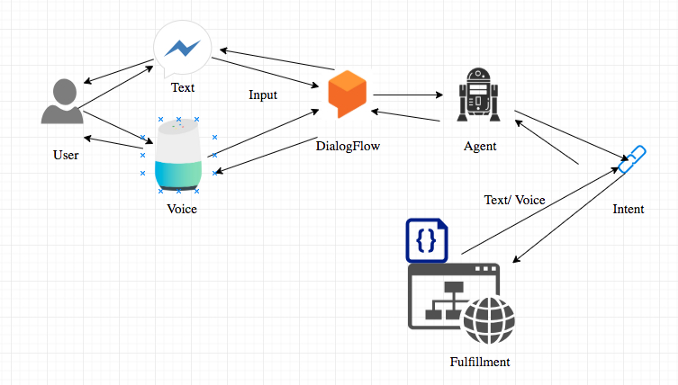 Создайте лучшего автоматизированного чат-бота с искусственным интеллектом, используя Google Dialog.
Создайте лучшего автоматизированного чат-бота с искусственным интеллектом, используя Google Dialog.
343. Что такое автоматическое распознавание речи?

344. Коллекция 10 лучших + бесплатных курсов по машинному обучению
 Вот подборка некоторых из лучших + бесплатных курсов по машинному обучению, доступных в Интернете.
Вот подборка некоторых из лучших + бесплатных курсов по машинному обучению, доступных в Интернете.
345. Как POST-запросы с помощью Python упрощают парсинг веб-страниц
 Чтобы очистить веб-сайт, обычно отправляют запросы GET, но полезно знать, как отправлять данные. В этой статье мы увидим, как начать работу с POST-запросами.
Чтобы очистить веб-сайт, обычно отправляют запросы GET, но полезно знать, как отправлять данные. В этой статье мы увидим, как начать работу с POST-запросами.
346. Моделирование длительного медвежьего рынка криптовалют с помощью метода Монте-Карло
 В середине 2018 года стало ясно, что мы далеко отошли от ликующего изобилия, которое характеризовало пиковые месяцы декабрь и январь.
В середине 2018 года стало ясно, что мы далеко отошли от ликующего изобилия, которое характеризовало пиковые месяцы декабрь и январь.
347. ЛУЧШАЯ фотография для 3D-модели AI!
 Как будто фотографирование не было достаточно сложной технологической задачей, сейчас мы делаем противоположное: моделируем мир из изображений. Я рассказал об удивительных моделях на основе искусственного интеллекта, которые могут снимать изображения и превращать их в высококачественные сцены. Сложная задача, заключающаяся в том, чтобы сделать несколько изображений в двухмерном мире, чтобы представить, как объект или человек будут выглядеть в реальном мире.
Как будто фотографирование не было достаточно сложной технологической задачей, сейчас мы делаем противоположное: моделируем мир из изображений. Я рассказал об удивительных моделях на основе искусственного интеллекта, которые могут снимать изображения и превращать их в высококачественные сцены. Сложная задача, заключающаяся в том, чтобы сделать несколько изображений в двухмерном мире, чтобы представить, как объект или человек будут выглядеть в реальном мире.
348. Почему каждый инженер-программист должен изучать Python?
349. Python для начинающих: изучение острот на практике
 Как и списки, и лямбда-функции, однострочные коды Python могут
сэкономите много времени и места, так как же их освоить?
Как и списки, и лямбда-функции, однострочные коды Python могут
сэкономите много времени и места, так как же их освоить?
350. Основное руководство по моделям трансформаторов в машинном обучении
 Модели-трансформеры стали де-факто стандартом для задач НЛП. Например, я уверен, что вы уже видели потрясающие демонстрации GPT3 Transformer и статьи, в которых подробно описывается, сколько времени и денег потребовалось для обучения.
Модели-трансформеры стали де-факто стандартом для задач НЛП. Например, я уверен, что вы уже видели потрясающие демонстрации GPT3 Transformer и статьи, в которых подробно описывается, сколько времени и денег потребовалось для обучения.
351. Машинное обучение с самоконтролем: история и тенденции на 2021 год
 Поговорим о самоконтролируемом машинном обучении — способе многому научить модель без ручной разметки, а также о возможности избежать глубокого обучения при настройке модели для решения задачи. Этот материал требует среднего уровня подготовки; имеется много ссылок на оригинальные публикации.
Поговорим о самоконтролируемом машинном обучении — способе многому научить модель без ручной разметки, а также о возможности избежать глубокого обучения при настройке модели для решения задачи. Этот материал требует среднего уровня подготовки; имеется много ссылок на оригинальные публикации.
352. Тенденции машинного обучения, которые следует знать компаниям в 2020 году
 Вы когда-нибудь задумывались, сколько данных существует в нашем мире? Рост объема данных был огромным с момента создания Интернета и только ускорился за последние два десятилетия. Сегодня в Интернете размещено около 2 миллиардов веб-сайтов для 4,2 миллиардов активных пользователей.
Вы когда-нибудь задумывались, сколько данных существует в нашем мире? Рост объема данных был огромным с момента создания Интернета и только ускорился за последние два десятилетия. Сегодня в Интернете размещено около 2 миллиардов веб-сайтов для 4,2 миллиардов активных пользователей.
353. Руководство по парсингу HTML-таблиц с помощью Pandas и BeautifulSoup
 Как не застрять при сборе табличных данных из Интернета.
Как не застрять при сборе табличных данных из Интернета.
354. Рефссылки, символические ссылки и жесткие ссылки: как они могут помочь проектам машинного обучения
 Жесткие ссылки и символические ссылки доступны с незапамятных времен, и мы используем их постоянно, даже не задумываясь об этом. В проектах машинного обучения они могут помочь нам при постановке новых экспериментов быстро и эффективно переупорядочивать файлы данных в проектах машинного обучения. Однако при использовании традиционных ссылок мы рискуем испортить файлы данных ошибочными изменениями. В этом сообщении блога мы рассмотрим детали использования ссылок, некоторые интересные новые возможности в современных файловых системах (рефссылки) и пример того, как DVC (контроль версий данных, https://dvc.org/) использует это.
Жесткие ссылки и символические ссылки доступны с незапамятных времен, и мы используем их постоянно, даже не задумываясь об этом. В проектах машинного обучения они могут помочь нам при постановке новых экспериментов быстро и эффективно переупорядочивать файлы данных в проектах машинного обучения. Однако при использовании традиционных ссылок мы рискуем испортить файлы данных ошибочными изменениями. В этом сообщении блога мы рассмотрим детали использования ссылок, некоторые интересные новые возможности в современных файловых системах (рефссылки) и пример того, как DVC (контроль версий данных, https://dvc.org/) использует это.
355. Чему меня научила наука о данных
 Я всегда говорю людям, что данные — это не новая нефть, а новая машина времени.
Я всегда говорю людям, что данные — это не новая нефть, а новая машина времени.
356. Как создать собственный уровень нейронной сети PyTorch с нуля
 На самом деле это задание из курса fast.ai Джереми Ховарда, урок 5. Я продемонстрировал, как легко построить сверточные нейронные сети с нуля, используя PyTorch. Сегодня давайте попробуем углубиться еще глубже и посмотреть, сможем ли мы написать собственный модуль nn.Linear. Зачем тратить время на написание собственного модуля PyTorch, если он уже написан разработчиками Facebook?
На самом деле это задание из курса fast.ai Джереми Ховарда, урок 5. Я продемонстрировал, как легко построить сверточные нейронные сети с нуля, используя PyTorch. Сегодня давайте попробуем углубиться еще глубже и посмотреть, сможем ли мы написать собственный модуль nn.Linear. Зачем тратить время на написание собственного модуля PyTorch, если он уже написан разработчиками Facebook?
357. Что происходит, когда вы заболеваете прямо сейчас?
 Мы живем в странное время. День за днём мы видим всё больше и больше. больше людей кашляют и болеют, наши соседи, коллеги по звонкам в Zoom, политики и т. д. Но вот тогда становится по-настоящему страшно — когда вы становитесь одним из «тех» и понятия не имеете, что делать. Ваш мозг рептилии активируется, вы входите в состояние паники и переходите в режим полного безумия. Именно это произошло со мной в этот понедельник, и я не уверен, что уже прошел эту стадию.
Мы живем в странное время. День за днём мы видим всё больше и больше. больше людей кашляют и болеют, наши соседи, коллеги по звонкам в Zoom, политики и т. д. Но вот тогда становится по-настоящему страшно — когда вы становитесь одним из «тех» и понятия не имеете, что делать. Ваш мозг рептилии активируется, вы входите в состояние паники и переходите в режим полного безумия. Именно это произошло со мной в этот понедельник, и я не уверен, что уже прошел эту стадию.
358. Создание алгоритмов машинного обучения, которым можно доверять
 Как объяснить любую модель машинного обучения за считанные минуты — с уверенностью и доверием? Вот как:
Как объяснить любую модель машинного обучения за считанные минуты — с уверенностью и доверием? Вот как:
359. Что ученые, работающие с данными, должны знать об обучении с несколькими выходами и несколькими метками
 Машинное обучение с несколькими выходами — MixedRandomForest
Машинное обучение с несколькими выходами — MixedRandomForest
360. Непредсказуемость искусственного интеллекта
 Молодая область безопасности ИИ все еще находится в процессе выявления своих проблем и ограничений. В этой статье мы формально описываем один из таких результатов о невозможности, а именно: непредсказуемость ИИ. Мы доказываем, что невозможно точно и последовательно предсказать, какие конкретные действия предпримет интеллектуальная система, умнее человека, для достижения своих целей, даже если мы знаем конечные цели системы. В заключение обсуждается влияние непредсказуемости на безопасность ИИ.
Молодая область безопасности ИИ все еще находится в процессе выявления своих проблем и ограничений. В этой статье мы формально описываем один из таких результатов о невозможности, а именно: непредсказуемость ИИ. Мы доказываем, что невозможно точно и последовательно предсказать, какие конкретные действия предпримет интеллектуальная система, умнее человека, для достижения своих целей, даже если мы знаем конечные цели системы. В заключение обсуждается влияние непредсказуемости на безопасность ИИ.
361. Как эффективно обучать модели компьютерного зрения
 Отправной точкой создания успешного приложения компьютерного зрения является модель. Обучение модели компьютерного зрения может занять много времени и проблем, если у вас нет опыта в области науки о данных. Тем не менее, это требование для индивидуальных приложений.
Отправной точкой создания успешного приложения компьютерного зрения является модель. Обучение модели компьютерного зрения может занять много времени и проблем, если у вас нет опыта в области науки о данных. Тем не менее, это требование для индивидуальных приложений.
362. Алгоритмы и общество: непростая дискуссия в трех частях
 Источник изображения: Unified Infotech
Источник изображения: Unified Infotech
363. Современное хранилище данных мертво?
 Нужен ли нам радикально новый подход к технологии хранилищ данных? Неизменяемое хранилище данных начинается с соглашений об уровне обслуживания потребителей данных и передачи данных в предварительно смоделированном виде.
Нужен ли нам радикально новый подход к технологии хранилищ данных? Неизменяемое хранилище данных начинается с соглашений об уровне обслуживания потребителей данных и передачи данных в предварительно смоделированном виде.
364. Какие стартапы самые популярные в Океании?
 В HackerNoon мы гордимся тем, что поддерживаем стартапы, потому что знаем, насколько сложно создать компанию и управлять ею.
В HackerNoon мы гордимся тем, что поддерживаем стартапы, потому что знаем, насколько сложно создать компанию и управлять ею.
365. Планирование вашего стартапа: руководство команды данных до 2021 года
 Планирование в стартапе может показаться бесполезным занятием — особенно, когда дело касается данных — особенно когда ваша команда данных маленькая и разрозненная.
Планирование в стартапе может показаться бесполезным занятием — особенно, когда дело касается данных — особенно когда ваша команда данных маленькая и разрозненная.
366. Популярные реализации Python [обзор]
 Вы правильно прочитали. Все дело в реализации. Сегодня мы поговорим о различных реализациях Python. Обратите внимание на различные виды, будь то Cpython, Brython, что угодно.
Вы правильно прочитали. Все дело в реализации. Сегодня мы поговорим о различных реализациях Python. Обратите внимание на различные виды, будь то Cpython, Brython, что угодно.
367. Представляем набор данных новостей на суахили для классификации тем
 Суахили (также известный как кисуахили) — один из самых распространенных языков в Африке. На нем говорят 100–150 миллионов человек по всей Восточной Африке. Суахили широко используется в качестве второго языка населением всего африканского континента и преподается в школах и университетах. В Танзании это один из двух национальных языков (второй — английский).
Суахили (также известный как кисуахили) — один из самых распространенных языков в Африке. На нем говорят 100–150 миллионов человек по всей Восточной Африке. Суахили широко используется в качестве второго языка населением всего африканского континента и преподается в школах и университетах. В Танзании это один из двух национальных языков (второй — английский).
368. Извлечение ярких цветов из изображения с помощью машинного обучения
 В этой статье объясняется, как я нашел красивый и простой алгоритм для извлечения ярких цветов из изображения.
В этой статье объясняется, как я нашел красивый и простой алгоритм для извлечения ярких цветов из изображения.
369. Расцвет планеты искусственного интеллекта
 Люди никогда не простужались и никогда не простудятся. Постоянно стремясь быстрее достичь будущего, мы создали искусственный интеллект.
Люди никогда не простужались и никогда не простудятся. Постоянно стремясь быстрее достичь будущего, мы создали искусственный интеллект.
370. Наука о данных с содержанием: лучшие массовые открытые онлайн-курсы
 Бенджамин Оби Тайо в своем недавнем посте «МООК по науке о данных слишком поверхностны» написал следующее:
Бенджамин Оби Тайо в своем недавнем посте «МООК по науке о данных слишком поверхностны» написал следующее:
371. Линейная регрессия и логистическая регрессия для задач классификации
 В этой статье объясняется, почему логистическая регрессия работает лучше, чем линейная регрессия, для задач классификации, а также две причины, по которым линейная регрессия не подходит:
В этой статье объясняется, почему логистическая регрессия работает лучше, чем линейная регрессия, для задач классификации, а также две причины, по которым линейная регрессия не подходит:
372. Построение классификации спама с использованием наивного алгоритма Байеса
 В этой статье мы рассмотрим классификацию спама в электронной почте, используя один из простейших методов, называемый классификацией Наивного Байеса.
В этой статье мы рассмотрим классификацию спама в электронной почте, используя один из простейших методов, называемый классификацией Наивного Байеса.
373. 10 вопросов, которые следует учитывать при создании корпоративного проекта искусственного интеллекта
 К настоящему времени все уважающие себя руководители слышали об искусственном интеллекте и думали: «Ммм, да, я бы хотел получить часть этого действия». И поскольку они являются руководителями, они приказали своим подчиненным начать работу и вернулись на поле для гольфа. Лично я не вижу проблем в таком способе ведения дел, поскольку подчиненные затем идут к консультантам, таким как я, чтобы понять, что их босс мог иметь в виду, когда говорил: «Мне нужна, например, Alexa, но, например, для офисных стульев» (да , у меня для этого есть презентация в PowerPoint).
К настоящему времени все уважающие себя руководители слышали об искусственном интеллекте и думали: «Ммм, да, я бы хотел получить часть этого действия». И поскольку они являются руководителями, они приказали своим подчиненным начать работу и вернулись на поле для гольфа. Лично я не вижу проблем в таком способе ведения дел, поскольку подчиненные затем идут к консультантам, таким как я, чтобы понять, что их босс мог иметь в виду, когда говорил: «Мне нужна, например, Alexa, но, например, для офисных стульев» (да , у меня для этого есть презентация в PowerPoint).
374. Интервью Amazon Data Science: оконные функции и псевдонимы
 Сегодня у меня вопрос от Amazon для собеседования по продвинутым наукам о данных. Этот вопрос проверит ваши навыки манипулирования датами и форматирования, а также наши знания оконных функций.
Сегодня у меня вопрос от Amazon для собеседования по продвинутым наукам о данных. Этот вопрос проверит ваши навыки манипулирования датами и форматирования, а также наши знания оконных функций.
375. Наука о данных выглядит как фальшивый предприниматель в рекламе на YouTube
 Выбросьте всю эту чушь AI/ML, если вы не можете понять мир с помощью чистых данных.
Выбросьте всю эту чушь AI/ML, если вы не можете понять мир с помощью чистых данных.
376. Как агрегация PostgreSQL повлияла на разработку гиперфункций шкалы времени
 Узнайте больше об агрегации PostgreSQL, о том, как реализация PostgreSQL вдохновила нас при создании гиперфункций TimescaleDB и что это значит для разработчиков.
Узнайте больше об агрегации PostgreSQL, о том, как реализация PostgreSQL вдохновила нас при создании гиперфункций TimescaleDB и что это значит для разработчиков.
377. Minecraft может предложить лучшую модель управления Интернетом
 Глядя на сегодняшний Интернет, легко задаться вопросом: что же случилось с мечтой о том, что это пойдет на пользу демократии? Что ж, если оставить в стороне скандалы в крупных социальных сетях и страшные игры хакеров автократии, я думаю, что еще есть место для надежды. В сети по-прежнему полно небольших экспериментов по самоуправлению. Это все еще происходит, может быть, незаметно, но в таких огромных масштабах, что у нас есть шанс не только возродить основополагающую мечту о сети, но и применить современные научные методы к основным тысячелетним вопросам о самоуправлении и о том, как оно работает.
Глядя на сегодняшний Интернет, легко задаться вопросом: что же случилось с мечтой о том, что это пойдет на пользу демократии? Что ж, если оставить в стороне скандалы в крупных социальных сетях и страшные игры хакеров автократии, я думаю, что еще есть место для надежды. В сети по-прежнему полно небольших экспериментов по самоуправлению. Это все еще происходит, может быть, незаметно, но в таких огромных масштабах, что у нас есть шанс не только возродить основополагающую мечту о сети, но и применить современные научные методы к основным тысячелетним вопросам о самоуправлении и о том, как оно работает.
378. Нейронная пространственно-временная обработка сигналов машинного обучения с помощью PyTorch Geometric Temporal
 PyTorch Geometric Temporal — это библиотека глубокого обучения для нейронной обработки пространственно-временных сигналов.
PyTorch Geometric Temporal — это библиотека глубокого обучения для нейронной обработки пространственно-временных сигналов.
379. Как бы я изучал науку о данных, если бы мне пришлось начинать все сначала
 Пару дней назад я задумался, если бы мне пришлось заново начинать изучать машинное обучение и науку о данных, с чего бы мне начать?
Пару дней назад я задумался, если бы мне пришлось заново начинать изучать машинное обучение и науку о данных, с чего бы мне начать?
380. Модуль ColorDetection: алгоритмы определения цвета Python
 Изображений. Вот и все. Изображений. С практической точки зрения возьмем модельера (как мне в свое время ярко описал один форумчанин). Вам дано изображение или вы имеете в своем распоряжении изображение, которое просто возбуждает ваше любопытство и вы хотите включить его в одну из ваших новых линий. Давайте немного отклонимся в раздел генетики. Например, вам дано изображение чашки Петри с пигментированными бактериями или подобными организмами, и вы хотели бы найти обилие этого организма или организмов на этом конкретном изображении. Уловили суть?
Изображений. Вот и все. Изображений. С практической точки зрения возьмем модельера (как мне в свое время ярко описал один форумчанин). Вам дано изображение или вы имеете в своем распоряжении изображение, которое просто возбуждает ваше любопытство и вы хотите включить его в одну из ваших новых линий. Давайте немного отклонимся в раздел генетики. Например, вам дано изображение чашки Петри с пигментированными бактериями или подобными организмами, и вы хотели бы найти обилие этого организма или организмов на этом конкретном изображении. Уловили суть?
381. 7 реальных применений ИИ в здравоохранении

382. Необходимый контрольный список для очистки данных
 Проработав некоторое время специалистом по данным в своем стартапе, я пришел к выводу, что мне нужно было обратиться за внешней помощью в вашем проекте.
Проработав некоторое время специалистом по данным в своем стартапе, я пришел к выводу, что мне нужно было обратиться за внешней помощью в вашем проекте.
383. Получение данных для обучения машинному обучению с помощью метода Лайонбриджа [Практическое руководство]
 В области машинного обучения подготовка обучающих данных является одной из наиболее важных и трудоемких задач. Фактически, многие ученые, работающие с данными, утверждают, что большая часть науки о данных представляет собой предварительную обработку, а некоторые исследования показали, что качество ваших обучающих данных более важно, чем тип используемого вами алгоритма.
В области машинного обучения подготовка обучающих данных является одной из наиболее важных и трудоемких задач. Фактически, многие ученые, работающие с данными, утверждают, что большая часть науки о данных представляет собой предварительную обработку, а некоторые исследования показали, что качество ваших обучающих данных более важно, чем тип используемого вами алгоритма.
384. Можем ли мы быть честными в вопросах этики?
 «Манифест практики обработки данных» (datapractices.org) был подготовлен организацией Data for Good Exchange, спонсируемой Data for Democracy и Bloomberg, и продвигаемой бывшим главным специалистом по данным США DJ Патилом. Создатели документа не рисковали, создавая и продвигая его, поэтому неудивительно, что продукт не соответствует собственным этическим стандартам. Мы не исправим этику, исправив эти инструменты. Создатели этих инструментов систематически встраивали в свои продукты предвзятость перед их внедрением.
«Манифест практики обработки данных» (datapractices.org) был подготовлен организацией Data for Good Exchange, спонсируемой Data for Democracy и Bloomberg, и продвигаемой бывшим главным специалистом по данным США DJ Патилом. Создатели документа не рисковали, создавая и продвигая его, поэтому неудивительно, что продукт не соответствует собственным этическим стандартам. Мы не исправим этику, исправив эти инструменты. Создатели этих инструментов систематически встраивали в свои продукты предвзятость перед их внедрением.
385. Обучение с подкреплением - Функция ценности
 Коды и демо доступны. В этой статье рассматривается, что такое состояния, действия и вознаграждения при обучении с подкреплением, а также то, как агент может научиться с помощью моделирования определять наилучшие действия, которые следует предпринять в том или ином состоянии.
Коды и демо доступны. В этой статье рассматривается, что такое состояния, действия и вознаграждения при обучении с подкреплением, а также то, как агент может научиться с помощью моделирования определять наилучшие действия, которые следует предпринять в том или ином состоянии.
386. Из-за Covid19 я начал использовать большие данные
 Covid19 покорил мир. Люди паниковали и покупали туалетную бумагу, как никогда раньше. Знаменитости стараются держать нас в курсе последних видео, где они едят хлопья. Тревожные подростки и двадцатилетние люди очень капризны.
Covid19 покорил мир. Люди паниковали и покупали туалетную бумагу, как никогда раньше. Знаменитости стараются держать нас в курсе последних видео, где они едят хлопья. Тревожные подростки и двадцатилетние люди очень капризны.
387. Встраивание в машинное обучение: все, что вам нужно знать
 Здесь мы углубимся в историю внедрения машинного обучения, его общего использования и текущих инфраструктурных решений, включая векторную базу данных.
Здесь мы углубимся в историю внедрения машинного обучения, его общего использования и текущих инфраструктурных решений, включая векторную базу данных.
388. Почему мы используем шестиугольники, а не квадраты для агрегирования данных о местоположении
 Если вы представляете собой торговую площадку с двумя уровнями, такую как Uber, вы обслуживаете миллионы пользователей, заказывающих поездку, через ваших партнеров-водителей, которые принимают и выполняют эти запросы. Для торговой площадки с тремя уровнями, такой как Swiggy, добавляется еще один статический компонент (например, рестораны или магазины), где партнеры по доставке забирают заказы.
Если вы представляете собой торговую площадку с двумя уровнями, такую как Uber, вы обслуживаете миллионы пользователей, заказывающих поездку, через ваших партнеров-водителей, которые принимают и выполняют эти запросы. Для торговой площадки с тремя уровнями, такой как Swiggy, добавляется еще один статический компонент (например, рестораны или магазины), где партнеры по доставке забирают заказы.
389. Безопасность данных 101 для начинающих аутсорсеров по маркировке данных
 Команды проектов ИИ, использующие большие объемы данных с подробными требованиями к маркировке, могут работать в режиме реального времени. Инструменты, человеческие ресурсы и контроль качества для обеспечения точности могут стать проблемой. Легко понять, почему большинство проектных команд предпочитают аутсорсинг. Аутсорсинг позволяет вам сосредоточиться на основных задачах.
Команды проектов ИИ, использующие большие объемы данных с подробными требованиями к маркировке, могут работать в режиме реального времени. Инструменты, человеческие ресурсы и контроль качества для обеспечения точности могут стать проблемой. Легко понять, почему большинство проектных команд предпочитают аутсорсинг. Аутсорсинг позволяет вам сосредоточиться на основных задачах.
390. Распространение многоразовых инструментов моделирования данных на основе SQL и сервисов DataOps
 Возрождение СУБД на основе SQL
Возрождение СУБД на основе SQL
391. 6 мест, где можно начать карьеру в области науки о данных в 2022 году
 Как стать специалистом по данным?
Хотите стать специалистом по данным? Вот ресурсы.
Ресурсы, которые помогут стать специалистом по данным
Как стать специалистом по данным?
Хотите стать специалистом по данным? Вот ресурсы.
Ресурсы, которые помогут стать специалистом по данным
392. fast.ai Джереми Ховарда против deeplearning.ai Эндрю Нга – сильно ли они отличаются друг от друга?
 Как не «перегрузить» обучение ИИ, пройдя курсы fast.ai и deeplearning.ai
Как не «перегрузить» обучение ИИ, пройдя курсы fast.ai и deeplearning.ai
393. Визуализация недавней распродажи криптовалют
 Анализ недавнего краха криптовалюты с точки зрения альткойнов. Распродажа криптовалют на сильном импульсе после выхода из эйфории на последнем ралли.
Анализ недавнего краха криптовалюты с точки зрения альткойнов. Распродажа криптовалют на сильном импульсе после выхода из эйфории на последнем ралли.
394. Введение в соединители данных: ваш первый шаг к аналитике данных
 В этом посте объясняется, что такое соединитель данных, и представлена основа для создания соединителей, которые реплицируют данные из разных источников в ваше хранилище данных.
В этом посте объясняется, что такое соединитель данных, и представлена основа для создания соединителей, которые реплицируют данные из разных источников в ваше хранилище данных.
395. Как распознавание лиц работает с масками для лица? [Объяснение]
 С распространением COVID-19 ношение масок стало обязательным. По крайней мере, для большей части населения. Это создало проблему для нынешних систем идентификации. Например, FaceID от Apple с трудом распознавал лица в масках.
С распространением COVID-19 ношение масок стало обязательным. По крайней мере, для большей части населения. Это создало проблему для нынешних систем идентификации. Например, FaceID от Apple с трудом распознавал лица в масках.
396. Сервисы Amazon ML: глубокое знакомство с AWS SageMaker
 SageMaker – это полностью управляемый сервис, который позволяет разработчикам создавать, обучать, тестировать и развертывать модели машинного обучения в любом масштабе.
SageMaker – это полностью управляемый сервис, который позволяет разработчикам создавать, обучать, тестировать и развертывать модели машинного обучения в любом масштабе.
397. Ученые, работающие с данными, инженеры-программисты и будущее медицины
 Мир меняется, особенно то, как мы лечим себя. Появление компьютеров следующего поколения, технологий облачных вычислений, искусственного интеллекта, децентрализации и т. д. кардинально изменило, казалось бы, каждую отрасль. Вычислительная медицина в настоящее время является новой новой дисциплиной.
Мир меняется, особенно то, как мы лечим себя. Появление компьютеров следующего поколения, технологий облачных вычислений, искусственного интеллекта, децентрализации и т. д. кардинально изменило, казалось бы, каждую отрасль. Вычислительная медицина в настоящее время является новой новой дисциплиной.
398. Автоматизированное машинное обучение для аналитиков данных и amp; Бизнес-пользователи
 Автоматизированное машинное обучение (AutoML) представляет собой фундаментальный сдвиг в подходе организаций любого размера к машинному обучению и обучению. наука о данных.
Автоматизированное машинное обучение (AutoML) представляет собой фундаментальный сдвиг в подходе организаций любого размера к машинному обучению и обучению. наука о данных.
399. Визуализация данных
 Что такое визуализация данных?
Что такое визуализация данных?
400. Используйте повышающую выборку и веса для решения проблемы дисбаланса данных
 Работали ли вы над проблемой классификации машинного обучения в реальном мире? Если да, то у вас, вероятно, есть некоторый опыт решения проблемы дисбаланса данных. Данные о дисбалансе означают, что классы, которые мы хотим предсказать, непропорциональны. Классы, составляющие большую часть данных, называются классами большинства. Те, которые составляют меньшую часть, представляют собой классы меньшинств. Например, мы хотим использовать модели машинного обучения для выявления мошенничества с кредитными картами, а мошеннические действия происходят примерно в 0,1% из миллионов транзакций. Большинство регулярных транзакций не позволят алгоритму машинного обучения выявить закономерности мошеннических действий.
Работали ли вы над проблемой классификации машинного обучения в реальном мире? Если да, то у вас, вероятно, есть некоторый опыт решения проблемы дисбаланса данных. Данные о дисбалансе означают, что классы, которые мы хотим предсказать, непропорциональны. Классы, составляющие большую часть данных, называются классами большинства. Те, которые составляют меньшую часть, представляют собой классы меньшинств. Например, мы хотим использовать модели машинного обучения для выявления мошенничества с кредитными картами, а мошеннические действия происходят примерно в 0,1% из миллионов транзакций. Большинство регулярных транзакций не позволят алгоритму машинного обучения выявить закономерности мошеннических действий.
401. Как выполнить увеличение данных с помощью библиотеки Augly
 Увеличение данных – это метод, используемый практиками для увеличения объема данных путем создания модифицированных данных из существующих данных.
Увеличение данных – это метод, используемый практиками для увеличения объема данных путем создания модифицированных данных из существующих данных.
402. Рабочий процесс разработки Docker для Apache Spark
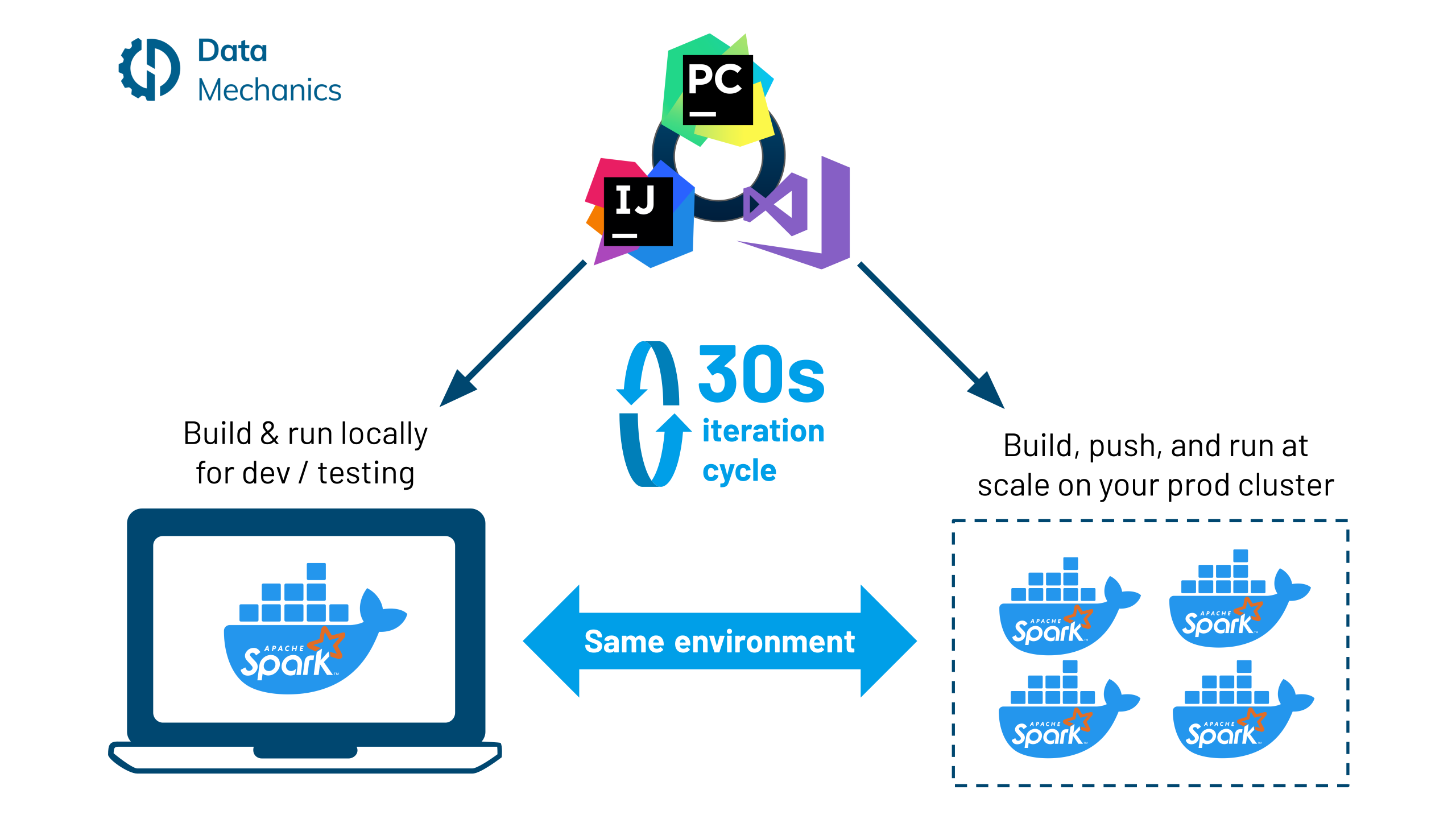 Преимущества использования контейнеров Docker хорошо известны: они предоставляют согласованные и изолированные среды, поэтому приложения можно развертывать где угодно — локально, в средах разработки/тестирования/производства, среди всех облачных провайдеров и локально — повторяемым способом. .
Преимущества использования контейнеров Docker хорошо известны: они предоставляют согласованные и изолированные среды, поэтому приложения можно развертывать где угодно — локально, в средах разработки/тестирования/производства, среди всех облачных провайдеров и локально — повторяемым способом. .
403. Обслуживание моделей данных с помощью MLFlow в рабочей среде
 Для организаций, которые ищут способ «демократизировать» науку о данных, необходимо, чтобы модели данных были доступны предприятию очень простым способом. В нашем контексте это часть «операционализации модели». Существуют и другие решения для обслуживания моделей данных, что является очень распространенной проблемой для специалистов по данным.
Для организаций, которые ищут способ «демократизировать» науку о данных, необходимо, чтобы модели данных были доступны предприятию очень простым способом. В нашем контексте это часть «операционализации модели». Существуют и другие решения для обслуживания моделей данных, что является очень распространенной проблемой для специалистов по данным.
404 . Обучение собственной модели классификации текста с нуля с помощью Tensorflow проще простого

405. Премия CVPR 2021 за лучшую статью: управляемое создание изображений GIRAFFE
 Используя модифицированную архитектуру GAN, они могут перемещать объекты на изображении, не затрагивая фон или другие объекты!
Используя модифицированную архитектуру GAN, они могут перемещать объекты на изображении, не затрагивая фон или другие объекты!
406. Эта нейронная сеть рисует депрессивные российские городские пейзажи
 Русская нейросеть doomer создает картины и музыкальные клипы. Руководство. Stylegan2 обучался на тысячах изображений советской архитектуры.
Русская нейросеть doomer создает картины и музыкальные клипы. Руководство. Stylegan2 обучался на тысячах изображений советской архитектуры.
407. Освобождение ума специалиста по данным от проклятия векторизации – обращение к Джулии за помощью
 В настоящее время большинство специалистов по данным используют Python или R в качестве основного языка программирования. Так было и со мной, пока в начале этого года я не встретил Джулию. Джулия обещает производительность, сравнимую со статически типизированными компилируемыми языками (такими как C), сохраняя при этом возможности быстрой разработки интерпретируемых языков (таких как Python, R или Matlab). Такая производительность достигается за счет JIT-компиляции.
В настоящее время большинство специалистов по данным используют Python или R в качестве основного языка программирования. Так было и со мной, пока в начале этого года я не встретил Джулию. Джулия обещает производительность, сравнимую со статически типизированными компилируемыми языками (такими как C), сохраняя при этом возможности быстрой разработки интерпретируемых языков (таких как Python, R или Matlab). Такая производительность достигается за счет JIT-компиляции.
408. Scikit Learn 1.0: новые возможности библиотеки машинного обучения Python
 Scikit-learn — это самая популярная и бесплатная библиотека машинного обучения Python с открытым исходным кодом для специалистов по данным и специалистов по машинному обучению. Библиотека scikit-learn содержит множество эффективных инструментов для машинного обучения и статистического моделирования, включая классификацию, регрессию, кластеризацию и уменьшение размерности.
Scikit-learn — это самая популярная и бесплатная библиотека машинного обучения Python с открытым исходным кодом для специалистов по данным и специалистов по машинному обучению. Библиотека scikit-learn содержит множество эффективных инструментов для машинного обучения и статистического моделирования, включая классификацию, регрессию, кластеризацию и уменьшение размерности.
409. 5 вопросов для собеседования по науке о данных через Facebook, Twitch и Postmate
 Есть вопросы для собеседований по науке о данных, которые я собрал за первые несколько месяцев 2021 года на Facebook, Twitch, Postmate и других сайтах.
Есть вопросы для собеседований по науке о данных, которые я собрал за первые несколько месяцев 2021 года на Facebook, Twitch, Postmate и других сайтах.
410. Полное руководство по парсингу веб-страниц
 Освоение веб-скрапинга как босс. Советы по извлечению данных и Аналитика, примеры использования, проблемы... Все, что вам нужно знать🔥
Освоение веб-скрапинга как босс. Советы по извлечению данных и Аналитика, примеры использования, проблемы... Все, что вам нужно знать🔥
411. Что такое модель шепота OpenAI?
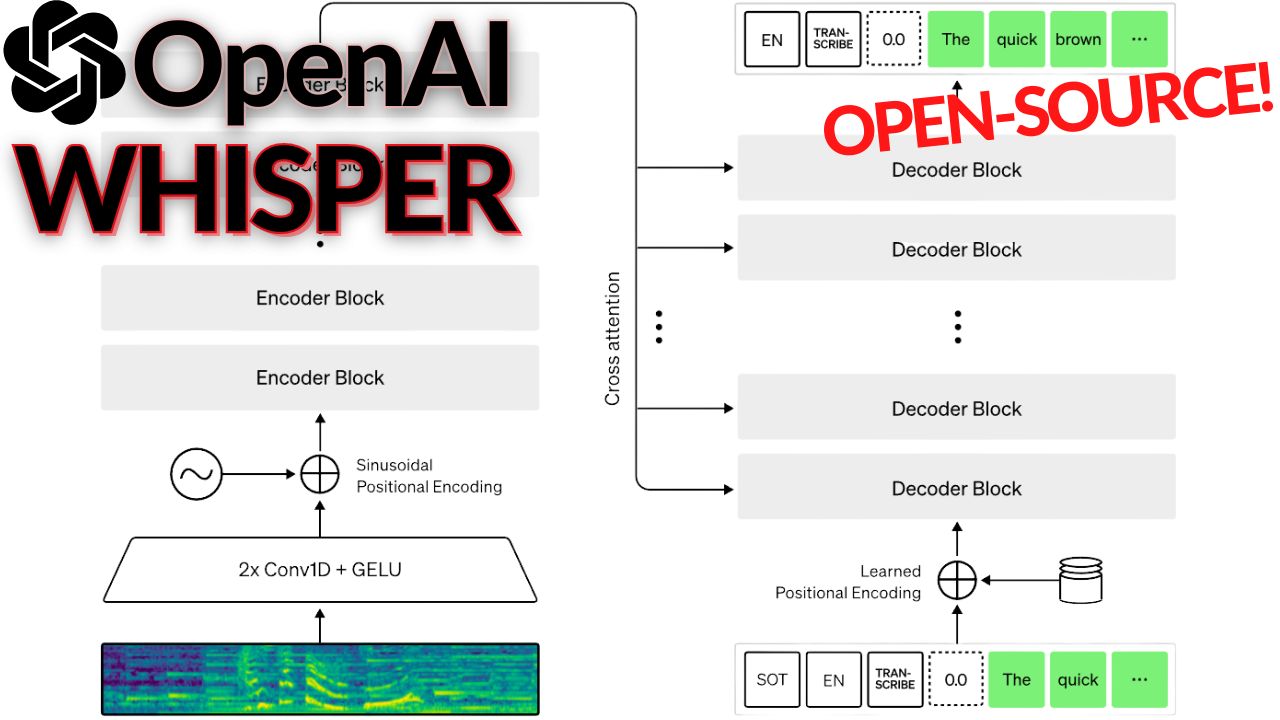 Вы когда-нибудь мечтали о хорошем инструменте транскрипции, который бы точно понимал, что вы говорите, и записывал это? Не то, что инструменты автоматического перевода YouTube… То есть они хороши, но далеки от совершенства. Просто попробуйте и включите эту функцию для видео, и вы поймете, о чем я говорю.
Вы когда-нибудь мечтали о хорошем инструменте транскрипции, который бы точно понимал, что вы говорите, и записывал это? Не то, что инструменты автоматического перевода YouTube… То есть они хороши, но далеки от совершенства. Просто попробуйте и включите эту функцию для видео, и вы поймете, о чем я говорю.
412. Данные с женской точки зрения
 Почему вам нужно больше женщин в области науки о данных прямо сейчасСделано с ❤ от Formulate.by
Почему вам нужно больше женщин в области науки о данных прямо сейчасСделано с ❤ от Formulate.by
413. Глубокое обучение уже мертво: на пути к искусственной жизни с Олафом Витковским
 Олаф Витковски — главный научный сотрудник Cross Labs, целью которой является преодоление разрыва между разведывательной наукой и технологиями искусственного интеллекта. Исследователь искусственной жизни, Витковский начал заниматься искусственным интеллектом с изучения репликации человеческой речи с помощью машин. Он основал Commentag в 2007 году, а в 2009 году переехал в Японию для продолжения исследований, где впервые заинтересовался искусственной жизнью.
Олаф Витковски — главный научный сотрудник Cross Labs, целью которой является преодоление разрыва между разведывательной наукой и технологиями искусственного интеллекта. Исследователь искусственной жизни, Витковский начал заниматься искусственным интеллектом с изучения репликации человеческой речи с помощью машин. Он основал Commentag в 2007 году, а в 2009 году переехал в Японию для продолжения исследований, где впервые заинтересовался искусственной жизнью.
414. Построение стратегии управления данными: важность, принципы, дорожная карта
 Данные, которые уже привычно называют валютой, источником жизненной силы и новой нефтью современного делового мира, обещают организациям непревзойденные конкурентные преимущества.
Данные, которые уже привычно называют валютой, источником жизненной силы и новой нефтью современного делового мира, обещают организациям непревзойденные конкурентные преимущества.
415. Путешествие стороннего наблюдателя через Kaggle

416. Что такое инженер по надежности данных?
 С каждым днем предприятия все больше полагаются на данные для принятия решений.
С каждым днем предприятия все больше полагаются на данные для принятия решений.
417. Как объединить аналитику в реальном времени из нескольких баз данных

418. Графики частичной зависимости: как обнаружить переменные, влияющие на модель
 Быстрые приемы о том, как определить, какие переменные влияют на результаты модели и в какой степени, и как их визуализировать с помощью графиков частичной зависимости.
Быстрые приемы о том, как определить, какие переменные влияют на результаты модели и в какой степени, и как их визуализировать с помощью графиков частичной зависимости.
419. О графах знаний и Grakn, с Дэниелом из Grakn Labs
 На этой АМА присутствовал Дэниел Кроу из Grakn Labs — изобретателей Grakn, технологии базы данных (графа знаний), которая служит основой интеллектуальной системы.
На этой АМА присутствовал Дэниел Кроу из Grakn Labs — изобретателей Grakn, технологии базы данных (графа знаний), которая служит основой интеллектуальной системы.
420. Как реализовать машинное обучение путем разработки конвейеров с самого начала
 Написание кода машинного обучения в виде конвейеров с самого начала сокращает технический долг и увеличивает скорость внедрения машинного обучения в производство.
Написание кода машинного обучения в виде конвейеров с самого начала сокращает технический долг и увеличивает скорость внедрения машинного обучения в производство.
421. Наборы данных машинного обучения с открытым исходным кодом по COVID-19; Модели; Инструменты для специалистов по данным
 Взгляд на подходы к глобальному управлению пандемией COVID-19, основанные на машинном обучении, включая инициативы проектов с открытым исходным кодом, поддерживаемые Google, и многое другое.
Взгляд на подходы к глобальному управлению пандемией COVID-19, основанные на машинном обучении, включая инициативы проектов с открытым исходным кодом, поддерживаемые Google, и многое другое.
422. 10 ключевых навыков, которые нужны каждому инженеру данных
 В результате разрыва между разработчиками приложений и специалистами по данным спрос на инженеров по данным вырос до 50 % в 2020 году, особенно благодаря увеличению инвестиций в SaaS-продукты на основе искусственного интеллекта.
В результате разрыва между разработчиками приложений и специалистами по данным спрос на инженеров по данным вырос до 50 % в 2020 году, особенно благодаря увеличению инвестиций в SaaS-продукты на основе искусственного интеллекта.
423. Логистическая регрессия: обучение модели на Python и использование ее во внешнем интерфейсе Angular
 Демо-версию этой статьи можно найти здесь.
Демо-версию этой статьи можно найти здесь.
424. Как синтетические данные ускоряют развитие компьютерного зрения
 Весной 1993 года профессор статистики из Гарварда Дональд Рубин сел писать статью. В дальнейшем работа Рубина изменила способ исследования и применения искусственного интеллекта, но заявленная цель была более скромной: проанализировать данные переписи населения США 1990 года, сохранив при этом анонимность респондентов.
Весной 1993 года профессор статистики из Гарварда Дональд Рубин сел писать статью. В дальнейшем работа Рубина изменила способ исследования и применения искусственного интеллекта, но заявленная цель была более скромной: проанализировать данные переписи населения США 1990 года, сохранив при этом анонимность респондентов.
425. Развенчание главных мифов об искусственном интеллекте
 Мифы об искусственном интеллекте варьируются от пугающих сообщений о роботах до невероятных ожиданий от этой технологии. Сегодня потребители постоянно сталкиваются с искусственным интеллектом через смартфоны, центры обслуживания клиентов, веб-сайты и бытовые приборы. Опросы показывают, что почти девять из 10 американцев используют ту или иную форму устройств искусственного интеллекта, а 79% людей сообщают, что ИИ оказывает положительное влияние на их жизнь. Несмотря на исключительно позитивное восприятие этой технологии, фильмы, искусство и литература уже давно предупреждают о потенциальной опасности использования ИИ в научно-фантастических повествованиях. Итак, насколько это основано на реальности?
Мифы об искусственном интеллекте варьируются от пугающих сообщений о роботах до невероятных ожиданий от этой технологии. Сегодня потребители постоянно сталкиваются с искусственным интеллектом через смартфоны, центры обслуживания клиентов, веб-сайты и бытовые приборы. Опросы показывают, что почти девять из 10 американцев используют ту или иную форму устройств искусственного интеллекта, а 79% людей сообщают, что ИИ оказывает положительное влияние на их жизнь. Несмотря на исключительно позитивное восприятие этой технологии, фильмы, искусство и литература уже давно предупреждают о потенциальной опасности использования ИИ в научно-фантастических повествованиях. Итак, насколько это основано на реальности?
426. Использование Python для финансов: как проанализировать рентабельность
 Узнайте, как провести анализ рентабельности аналогичных компаний с помощью Python
Узнайте, как провести анализ рентабельности аналогичных компаний с помощью Python
427. Маринование и распаковка в Python
 В этом блоге вы узнаете о процессе маринования и расмаринования, хотя он довольно прост, но очень важен и полезен.
В этом блоге вы узнаете о процессе маринования и расмаринования, хотя он довольно прост, но очень важен и полезен.
428. Почему соревнования по науке о данных важны и С чего начать
 Чтобы стать специалистом по данным, вам нужно учиться, приобретать необходимые навыки и много практиковаться, чтобы получить больше опыта. Участие в конкурсах по науке о данных было одним из лучших способов помочь новичкам в области науки о данных получить больше опыта и, наконец, подать заявку на работу.
Чтобы стать специалистом по данным, вам нужно учиться, приобретать необходимые навыки и много практиковаться, чтобы получить больше опыта. Участие в конкурсах по науке о данных было одним из лучших способов помочь новичкам в области науки о данных получить больше опыта и, наконец, подать заявку на работу.
429. Серия Foundation: Наука о данных, психоистория и будущее человечества
 Мир, в котором будущее человечества можно предсказать с помощью междисциплинарной науки под названием психоистория! Обзор Foundation Series от специалиста по обработке данных.
Мир, в котором будущее человечества можно предсказать с помощью междисциплинарной науки под названием психоистория! Обзор Foundation Series от специалиста по обработке данных.
430. Глобальное экономическое влияние ИИ: факты и цифры
 Обобщение результатов исследований Emerj, Harvard Business Review, MIT Sloan и Mckinsey
Обобщение результатов исследований Emerj, Harvard Business Review, MIT Sloan и Mckinsey
431. Как Uber использует искусственный интеллект для улучшения доставки
 Как Uber может доставлять еду и всегда прибывать вовремя или на несколько минут раньше? Как они сопоставляют пассажиров с водителями, чтобы вы могли всегда найти Uber? И все это при управлении всеми драйверами?!
Как Uber может доставлять еду и всегда прибывать вовремя или на несколько минут раньше? Как они сопоставляют пассажиров с водителями, чтобы вы могли всегда найти Uber? И все это при управлении всеми драйверами?!
432. Еще одна авария из-за беспилотного автомобиля: новый урок по разработке искусственного интеллекта
 (Источник: https://blogs.nvidia.com)
(Источник: https://blogs.nvidia.com)
433. От аномалий к криптостратегиям: факторное инвестирование в криптоактивы
 Давайте проведем небольшой тест: попробуйте подумать, сколько раз вы слышали подобные выражения:
Давайте проведем небольшой тест: попробуйте подумать, сколько раз вы слышали подобные выражения:
434. Мой странный переход от MBA к Data Science
 Да, вы правильно прочитали! Я называю свой переход от степени MBA к должности менеджера по аналитике в известном розничном бренде «СТРАННЫМ». И почему я это говорю? Потому что за время моего пятилетнего пути в области науки о данных у меня была возможность работать со многими заинтересованными сторонами в бизнесе, такими как руководители по маркетингу, бренд-менеджеры, руководители по продажам и т. д., и они много раз спрашивали меня о моем образовании. Мне хотелось бы думать, что они спросили об этом из-за моей способности представлять решения, учитывая бизнес-контекст и осуществимость реализации. Что ж, причина этого вопроса может быть разной для каждого человека: когда я говорю им, что я MBA, их ответ всегда был одним и тем же: «Что заставило вас выбрать техническую карьеру после получения MBA?» Поэтому я решил написать этот пост, чтобы поделиться своими мыслями по поводу двух вещей:
Да, вы правильно прочитали! Я называю свой переход от степени MBA к должности менеджера по аналитике в известном розничном бренде «СТРАННЫМ». И почему я это говорю? Потому что за время моего пятилетнего пути в области науки о данных у меня была возможность работать со многими заинтересованными сторонами в бизнесе, такими как руководители по маркетингу, бренд-менеджеры, руководители по продажам и т. д., и они много раз спрашивали меня о моем образовании. Мне хотелось бы думать, что они спросили об этом из-за моей способности представлять решения, учитывая бизнес-контекст и осуществимость реализации. Что ж, причина этого вопроса может быть разной для каждого человека: когда я говорю им, что я MBA, их ответ всегда был одним и тем же: «Что заставило вас выбрать техническую карьеру после получения MBA?» Поэтому я решил написать этот пост, чтобы поделиться своими мыслями по поводу двух вещей:
435. Интернет-знакомства с точки зрения анализа данных: глубокий взгляд
 Любовь во времена COVID — это… вызов, мягко говоря.
Любовь во времена COVID — это… вызов, мягко говоря.
436. 8 навыков, необходимых, чтобы стать специалистом по данным
 Еще в 2016 году компания Glassdoor заявила, что быть специалистом по данным — лучшая работа в Америке.
Еще в 2016 году компания Glassdoor заявила, что быть специалистом по данным — лучшая работа в Америке.
437. Как сортировать элементы массива: основное руководство
 Я хочу описать распространенный метод, используемый для сортировки элементов массива в алфавитном и числовом порядке.
Я хочу описать распространенный метод, используемый для сортировки элементов массива в алфавитном и числовом порядке.
438. Как нейронные сети создают иллюзии недостающих пикселей при рисовании изображений
 Когда человек видит объект, определенные нейроны зрительной коры нашего мозга активизируются, но когда мы принимаем галлюциногенные препараты, эти наркотики подавляют наши серотониновые рецепторы и приводят к искажению зрительного восприятия цветов и форм. Точно так же глубокие нейронные сети, смоделированные на основе структур нашего мозга, хранят данные в огромных таблицах числовых коэффициентов, которые не поддаются прямому человеческому пониманию. Но когда активация этих нейронных сетей чрезмерно стимулируется (виртуальные наркотики), мы получаем такие явления, как нейронные сны и нейронные галлюцинации. Сны — это мысленные предположения, которые вырабатываются нашим мозгом, когда аппарат восприятия отключается, тогда как галлюцинации возникают, когда этот аппарат восприятия становится гиперактивным. В этом блоге мы обсудим, как этот феномен галлюцинаций в нейронных сетях можно использовать для выполнения задачи рисования изображений.
Когда человек видит объект, определенные нейроны зрительной коры нашего мозга активизируются, но когда мы принимаем галлюциногенные препараты, эти наркотики подавляют наши серотониновые рецепторы и приводят к искажению зрительного восприятия цветов и форм. Точно так же глубокие нейронные сети, смоделированные на основе структур нашего мозга, хранят данные в огромных таблицах числовых коэффициентов, которые не поддаются прямому человеческому пониманию. Но когда активация этих нейронных сетей чрезмерно стимулируется (виртуальные наркотики), мы получаем такие явления, как нейронные сны и нейронные галлюцинации. Сны — это мысленные предположения, которые вырабатываются нашим мозгом, когда аппарат восприятия отключается, тогда как галлюцинации возникают, когда этот аппарат восприятия становится гиперактивным. В этом блоге мы обсудим, как этот феномен галлюцинаций в нейронных сетях можно использовать для выполнения задачи рисования изображений.
439. Обнаружение изменений в случаях COVID-19 с помощью байесовских моделей
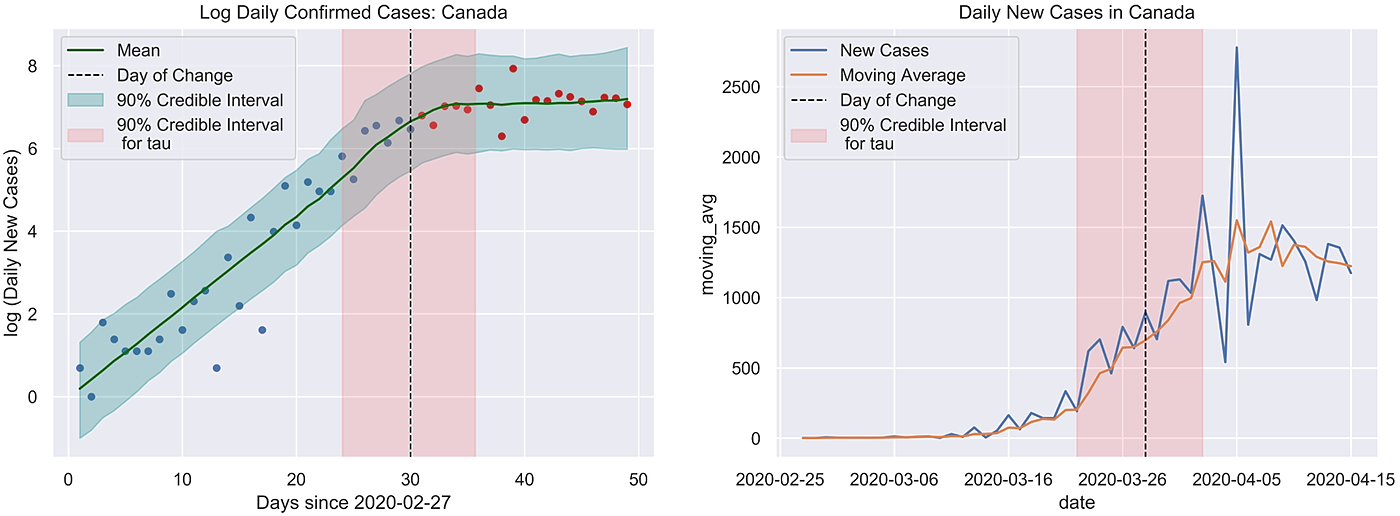 Байесовская модель точки изменения для оценки даты, когда число новых случаев COVID-19 начнет выравниваться в разных странах.
Байесовская модель точки изменения для оценки даты, когда число новых случаев COVID-19 начнет выравниваться в разных странах.
440. Эффективность искусственного интеллекта и машинного обучения в цепочках поставок в условиях глобальной пандемии
 Влияние Covid-19 на отрасль цепочек поставок было очень значительным. Как смягчить ситуацию, максимально используя различные оптимизации.
Влияние Covid-19 на отрасль цепочек поставок было очень значительным. Как смягчить ситуацию, максимально используя различные оптимизации.
441. Как создать полезный образовательный продукт для взрослых с помощью мотивационного дизайна
 Основным показателем образовательного продукта является уровень его завершения. Для его улучшения можно использовать принципы мотивационного проектирования.
Основным показателем образовательного продукта является уровень его завершения. Для его улучшения можно использовать принципы мотивационного проектирования.
442. Проблема машинной этики и прав роботов
 Машинная этика и права роботов быстро становятся горячими темами в сообществах искусственного интеллекта и робототехники. Мы будем утверждать, что попытки позволить машинам принимать этические решения или иметь права ошибочны. Вместо этого мы предлагаем новую науку о технике безопасности для интеллектуальных искусственных агентов. В частности, мы бросаем вызов научному сообществу по разработке интеллектуальных систем, способных доказать свою безопасность даже при рекурсивном самосовершенствовании.
Машинная этика и права роботов быстро становятся горячими темами в сообществах искусственного интеллекта и робототехники. Мы будем утверждать, что попытки позволить машинам принимать этические решения или иметь права ошибочны. Вместо этого мы предлагаем новую науку о технике безопасности для интеллектуальных искусственных агентов. В частности, мы бросаем вызов научному сообществу по разработке интеллектуальных систем, способных доказать свою безопасность даже при рекурсивном самосовершенствовании.
443. Применение языка программирования Python
 Python стал вторым по популярности языком программирования в мире и занял свое место, вытеснив Java.
Python стал вторым по популярности языком программирования в мире и занял свое место, вытеснив Java.
444. Мои любимые бесплатные курсы Excel для программистов, аналитиков данных и ИТ-специалистов
 Если вы хотите изучить Microsoft Excel, инструмент повышения производительности для ИТ-специалистов, и ищете бесплатные онлайн-курсы, то вы попали по адресу.
Если вы хотите изучить Microsoft Excel, инструмент повышения производительности для ИТ-специалистов, и ищете бесплатные онлайн-курсы, то вы попали по адресу.
445. Упрощение внедрения машинного обучения для всех [подробный обзор]
 Учитывая качество разрабатываемых сегодня пакетов машинного обучения, тестирование и создание моделей становится проще. Ученые, работающие с данными, могут просто импортировать свою любимую библиотеку и получить немедленный доступ к десяткам передовых алгоритмов.
Учитывая качество разрабатываемых сегодня пакетов машинного обучения, тестирование и создание моделей становится проще. Ученые, работающие с данными, могут просто импортировать свою любимую библиотеку и получить немедленный доступ к десяткам передовых алгоритмов.
446. Консультации по машинному обучению: действительно ли это нужно вашему бизнесу?
 Автор: Алексей Цымбал, директор по инновациям MobiDev.
Автор: Алексей Цымбал, директор по инновациям MobiDev.
447. Модели классификации текста: все советы и подсказки из пяти соревнований Kaggle
 В этой статье (первоначально опубликованной Шахулом Э.С. в блоге Neptune) я расскажу о некоторых полезных советах и приемах, которые помогут повысить производительность вашей модели классификации текста. Эти трюки основаны на решениях некоторых из лучших соревнований по НЛП от Kaggle.
В этой статье (первоначально опубликованной Шахулом Э.С. в блоге Neptune) я расскажу о некоторых полезных советах и приемах, которые помогут повысить производительность вашей модели классификации текста. Эти трюки основаны на решениях некоторых из лучших соревнований по НЛП от Kaggle.
448. Интегрируйте искусственный интеллект в картографирование данных для принятия бизнес-решений
 Прежде чем анализировать большие объемы данных, предприятия должны гомогенизировать их таким образом, чтобы сделать их доступными для лиц, принимающих решения. В настоящее время данные поступают из многих источников, и каждый конкретный источник может определять схожие точки данных по-разному. Скажем, например, в поле состояния в исходной системе может отображаться «Иллинойс», но в пункте назначения сохраняется значение «IL».
Прежде чем анализировать большие объемы данных, предприятия должны гомогенизировать их таким образом, чтобы сделать их доступными для лиц, принимающих решения. В настоящее время данные поступают из многих источников, и каждый конкретный источник может определять схожие точки данных по-разному. Скажем, например, в поле состояния в исходной системе может отображаться «Иллинойс», но в пункте назначения сохраняется значение «IL».
449. Наука о данных с нуля

450. Некоторые шокирующие данные анализа стейблкоинов
 Стейблкоины — одно из наиболее актуальных событий в криптоэкосистеме, которое набирает все большую популярность. Недавно я представил сессию, в которой осветил некоторые интересные анализы, возникающие в результате применения методов науки о данных к данным блокчейна стейблкоина. Слайды и видео с сессии скоро будут доступны, но я решил поделиться некоторыми наиболее интригующими фактами.
Стейблкоины — одно из наиболее актуальных событий в криптоэкосистеме, которое набирает все большую популярность. Недавно я представил сессию, в которой осветил некоторые интересные анализы, возникающие в результате применения методов науки о данных к данным блокчейна стейблкоина. Слайды и видео с сессии скоро будут доступны, но я решил поделиться некоторыми наиболее интригующими фактами.
451. Что случилось с Hadoop? Что вам следует делать сейчас?
 автор: Монте Цвебен & Сайед Махмуд из Splice Machine
автор: Монте Цвебен & Сайед Махмуд из Splice Machine
452. Как начать парсинг веб-страниц и почему вам не нужно программировать
 Сбор данных из Интернета может стать основой науки о данных. В этой статье мы увидим, как начать парсинг с написанием кода или без него.
Сбор данных из Интернета может стать основой науки о данных. В этой статье мы увидим, как начать парсинг с написанием кода или без него.
453. Учебное пособие по пакету Python Panda
 Ключевые методы понимания и использования панд
Ключевые методы понимания и использования панд
454. Как управлять продуктами машинного обучения. Часть I. Почему управлять продуктами машинного обучения так сложно?
 В моей предыдущей статье я говорил о самом большом отличии, которое дает машинное обучение (ML): ML позволяет отказаться от необходимости программировать машину и перейти к истинной автономии (самообучению). Машины делают прогнозы и улучшают понимание на основе закономерностей, которые они выявляют в данных, без того, чтобы люди явно указывали им, что делать. Вот почему машинное обучение особенно полезно для решения сложных задач, которые людям сложно объяснить машинам. Это также означает, что машинное обучение может сделать ваши продукты более персонализированными, автоматизированными и точными. Передовые алгоритмы, большие объемы данных и дешевое оборудование позволяют машинному обучению стать основным драйвером роста ВВП.
В моей предыдущей статье я говорил о самом большом отличии, которое дает машинное обучение (ML): ML позволяет отказаться от необходимости программировать машину и перейти к истинной автономии (самообучению). Машины делают прогнозы и улучшают понимание на основе закономерностей, которые они выявляют в данных, без того, чтобы люди явно указывали им, что делать. Вот почему машинное обучение особенно полезно для решения сложных задач, которые людям сложно объяснить машинам. Это также означает, что машинное обучение может сделать ваши продукты более персонализированными, автоматизированными и точными. Передовые алгоритмы, большие объемы данных и дешевое оборудование позволяют машинному обучению стать основным драйвером роста ВВП.
455. AutoScraper и Flask: создайте API для любого веб-сайта менее чем за 5 минут
 В этом уроке мы собираемся создать собственный API поиска электронной коммерции с поддержкой eBay и Etsy без использования каких-либо внешних API.
В этом уроке мы собираемся создать собственный API поиска электронной коммерции с поддержкой eBay и Etsy без использования каких-либо внешних API.
456. Рекомендатор на основе контента с использованием обработки естественного языка (NLP)
 Руководство по построению модели рекомендации фильмов на основе НЛП на основе контента: когда мы предоставляем рейтинги продуктов и услуг в Интернете, все выражаемые нами предпочтения и данные, которыми мы делимся (явно или нет), используются для генерации рекомендаций рекомендательными системами. . Наиболее распространенными примерами являются Amazon, Google и Netflix.
Руководство по построению модели рекомендации фильмов на основе НЛП на основе контента: когда мы предоставляем рейтинги продуктов и услуг в Интернете, все выражаемые нами предпочтения и данные, которыми мы делимся (явно или нет), используются для генерации рекомендаций рекомендательными системами. . Наиболее распространенными примерами являются Amazon, Google и Netflix.
457. Понимание концепции кластеризации в обучении без учителя

458. Креативность в аналитике данных — это нечто большее, чем просто визуализация данных
 Недавно я посетил сетевое мероприятие, где поговорил с рядом выпускников, которые рассматривали перспективную карьеру в области науки о данных и смежных областях.
Недавно я посетил сетевое мероприятие, где поговорил с рядом выпускников, которые рассматривали перспективную карьеру в области науки о данных и смежных областях.
459. Почему Python — лучший язык программирования для науки о данных и amp; Машинное обучение?
 Если вы хотите стать специалистом по данным и вам интересно, какой язык программирования вам следует изучить, то вы попали по адресу.
Если вы хотите стать специалистом по данным и вам интересно, какой язык программирования вам следует изучить, то вы попали по адресу.
460. Ваше руководство по обработке естественного языка (NLP)
 Все, что мы выражаем (устно или письменно), несет в себе огромные объемы информации. Тема, которую мы выбираем, наш тон, выбор слов — все это добавляет некую информацию, которую можно интерпретировать и извлечь из нее ценность. Теоретически мы можем понять и даже предсказать поведение человека, используя эту информацию.
Все, что мы выражаем (устно или письменно), несет в себе огромные объемы информации. Тема, которую мы выбираем, наш тон, выбор слов — все это добавляет некую информацию, которую можно интерпретировать и извлечь из нее ценность. Теоретически мы можем понять и даже предсказать поведение человека, используя эту информацию.
461. Как специалист по данным видит колоду карт

462. Как генерировать синтетические данные?
 Специальный репозиторий для генерации синтетических данных. Это предложение становится слишком распространённым, но оно по-прежнему верно и отражает рыночную тенденцию: данные — это новая нефть. Некоторые из крупнейших игроков рынка уже имеют сильнейшее влияние на эту валюту.
Специальный репозиторий для генерации синтетических данных. Это предложение становится слишком распространённым, но оно по-прежнему верно и отражает рыночную тенденцию: данные — это новая нефть. Некоторые из крупнейших игроков рынка уже имеют сильнейшее влияние на эту валюту.
463. LegalTech – обзор и перспективное будущее
 Введение в понимание того, как технологии могут нарушить закон
Введение в понимание того, как технологии могут нарушить закон
464. Решение проблемы холодного запуска в рекомендательных системах
 Проблема холодного запуска заключается в том, что система не может сделать какие-либо выводы для пользователей или элементов, о которых она еще не собрала достаточно информации. Проще говоря, если у вас нет или меньше исходных данных, какую рекомендацию система должна дать пользователю?
Проблема холодного запуска заключается в том, что система не может сделать какие-либо выводы для пользователей или элементов, о которых она еще не собрала достаточно информации. Проще говоря, если у вас нет или меньше исходных данных, какую рекомендацию система должна дать пользователю?
Хотя системы рекомендаций полезны для пользователей, у которых есть некоторая предыдущая история взаимодействия, это может быть не так для нового пользователя или недавно добавленного элемента. Проблема в том, что в обоих случаях у нас нет истории, на которой можно было бы основывать рекомендации.
465. 3 простых способа повысить производительность вашего кода Python
 I. Тест, тест, тест
I. Тест, тест, тест
466. 12 лучших библиотек Javascript для машинного обучения
 Быстро развивающиеся технологии, такие как машинное обучение, искусственный интеллект и наука о данных, несомненно, были одними из самых быстро развивающихся технологий этого десятилетия. Особое внимание уделяется машинному обучению, которое в целом помогло повысить производительность в нескольких секторах промышленности более чем на 40%. Не секрет, что вакансии в области машинного обучения являются одними из самых востребованных вакансий в отрасли.
Быстро развивающиеся технологии, такие как машинное обучение, искусственный интеллект и наука о данных, несомненно, были одними из самых быстро развивающихся технологий этого десятилетия. Особое внимание уделяется машинному обучению, которое в целом помогло повысить производительность в нескольких секторах промышленности более чем на 40%. Не секрет, что вакансии в области машинного обучения являются одними из самых востребованных вакансий в отрасли.
467. Федеральная биометрия: как правительство использует биометрические данные?
468. Мы как бы обошли платный доступ Firebase: вот как
 Некоторое время назад мы с несколькими друзьями решили создать приложение. Мы собрали наш код, запустили первую версию, а затем привлекли несколько пользователей с небольшим маркетинговым бюджетом.
Некоторое время назад мы с несколькими друзьями решили создать приложение. Мы собрали наш код, запустили первую версию, а затем привлекли несколько пользователей с небольшим маркетинговым бюджетом.
469. Искусство рассказывания историй о данных: как сделать ваши данные эффективными
470. Новый искусственный интеллект Google создает сводные данные ваших документов в Документах Google
 Недавно Google анонсировала новую модель автоматического создания сводок с использованием машинного обучения, опубликованную в Документах Google, которую вы уже можете использовать.
Недавно Google анонсировала новую модель автоматического создания сводок с использованием машинного обучения, опубликованную в Документах Google, которую вы уже можете использовать.
471. Деконструкция бессерверной облачной ОС
 Ответ на бессерверную революцию
Ответ на бессерверную революцию
472. 5 предстоящих онлайн-конференций по машинному обучению в 2020 году
 Конференции по машинному обучению всегда играли важную роль в мире науки о данных. Это место, где можно анонсировать новые исследования, обсудить текущие проблемы и пообщаться с сообществом. Они также помогают продвигать новые области исследований и разработок посредством сессий вопросов и ответов, семинаров и учебных пособий.
Конференции по машинному обучению всегда играли важную роль в мире науки о данных. Это место, где можно анонсировать новые исследования, обсудить текущие проблемы и пообщаться с сообществом. Они также помогают продвигать новые области исследований и разработок посредством сессий вопросов и ответов, семинаров и учебных пособий.
473. Руководство по деревьям решений от А до Я
 Поначалу изучение машинного обучения (МО) может показаться пугающим. Такие термины, как «Градиентный спуск», «Скрытое распределение Дирихле» или «Сверточный слой», могут напугать многих людей. Но есть дружественные способы освоить эту дисциплину, и я думаю, что начать с деревьев решений — мудрое решение.
Поначалу изучение машинного обучения (МО) может показаться пугающим. Такие термины, как «Градиентный спуск», «Скрытое распределение Дирихле» или «Сверточный слой», могут напугать многих людей. Но есть дружественные способы освоить эту дисциплину, и я думаю, что начать с деревьев решений — мудрое решение.
474. TikTok: бомба замедленного действия?
 TikTok, одно из самых популярных приложений 2019 года, возглавило рейтинги загрузок как на рынках Android, так и на Apple. Имея более 1,5 миллиардов загрузок и около полумиллиарда активных пользователей в месяц, TikTok определенно имеет доступ к огромному количеству пользователей. С такой большой базой пользователей скрывается скрытая золотая жила: их данные.
TikTok, одно из самых популярных приложений 2019 года, возглавило рейтинги загрузок как на рынках Android, так и на Apple. Имея более 1,5 миллиардов загрузок и около полумиллиарда активных пользователей в месяц, TikTok определенно имеет доступ к огромному количеству пользователей. С такой большой базой пользователей скрывается скрытая золотая жила: их данные.
475. Обучение науке о данных и наука о данных – машинное обучение с помощью Python
 Потребность в ее накоплении также возросла, поскольку мир вступил в период огромного объема информации. Основное внимание уделялось структурной структуре и ответам на информацию о магазине. Когда такие платформы, как Hadoop, решили проблему емкости, подготовка этой информации превратилась в проблему. Наука о данных начала брать на себя важную работу по решению этой проблемы. Информатика — это судьба искусственного интеллекта, поскольку он может повысить ценность вашего бизнеса.
Потребность в ее накоплении также возросла, поскольку мир вступил в период огромного объема информации. Основное внимание уделялось структурной структуре и ответам на информацию о магазине. Когда такие платформы, как Hadoop, решили проблему емкости, подготовка этой информации превратилась в проблему. Наука о данных начала брать на себя важную работу по решению этой проблемы. Информатика — это судьба искусственного интеллекта, поскольку он может повысить ценность вашего бизнеса.
476. Тайный гигант пейджеров Америки
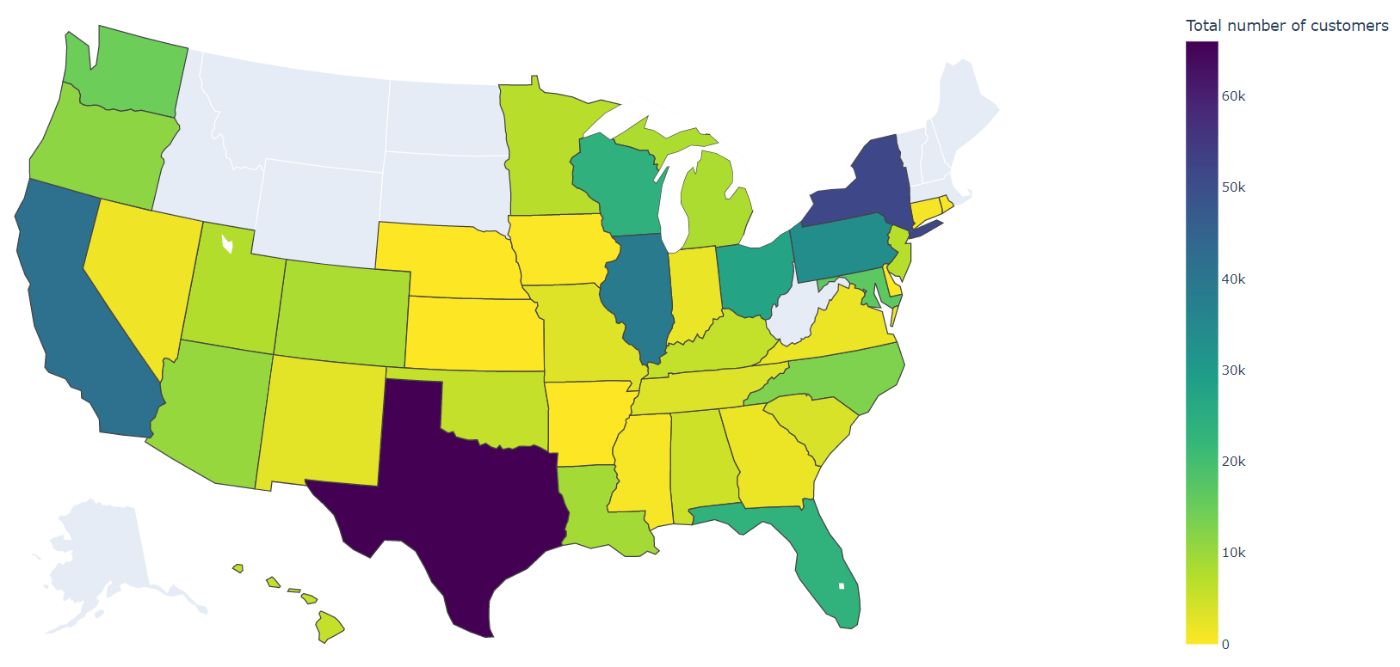 В начале января 2022 года я спонтанно купил пейджер. Я заглянул на рынок пейджеров в США и, к своему удивлению...
В начале января 2022 года я спонтанно купил пейджер. Я заглянул на рынок пейджеров в США и, к своему удивлению...
477. «ИИ продает, данные доставляют!»
 Контекст
Контекст
478. Начните с машинного обучения
 Нам всем приходится иметь дело с данными, и мы пытаемся изучить машинное обучение и внедрить его в наши проекты. Но все, кажется, забывают одно... он далеко не идеален, и столько всего предстоит пережить! Не волнуйтесь, мы обсудим каждый шаг, от начала до конца 👀.
Нам всем приходится иметь дело с данными, и мы пытаемся изучить машинное обучение и внедрить его в наши проекты. Но все, кажется, забывают одно... он далеко не идеален, и столько всего предстоит пережить! Не волнуйтесь, мы обсудим каждый шаг, от начала до конца 👀.
479. Как использовать Python Seaborn для исследовательского анализа данных

480. Scikit-Learn 0.24: 5 основных новых функций
 Для любых специалистов по данным & инженеры по машинному обучению используют scikit-learn для различных проектов машинного обучения. Вот 5 лучших новых функций scikit-learn 0.24
Для любых специалистов по данным & инженеры по машинному обучению используют scikit-learn для различных проектов машинного обучения. Вот 5 лучших новых функций scikit-learn 0.24
481. Как работает алгоритм сжатия LZ78
 Как работает формат GIF?
Как работает формат GIF?
482. Введение 5 различных типов текстовых аннотаций в НЛП
 Обработка естественного языка (НЛП) — одна из крупнейших областей развития ИИ. Многочисленные решения НЛП, такие как чат-боты, программы автоматического распознавания речи и анализа настроений, могут повысить эффективность и производительность в различных компаниях по всему миру.
Обработка естественного языка (НЛП) — одна из крупнейших областей развития ИИ. Многочисленные решения НЛП, такие как чат-боты, программы автоматического распознавания речи и анализа настроений, могут повысить эффективность и производительность в различных компаниях по всему миру.
483. Знакомство с лучшими платформами для обработки данных и машинного обучения (DSML) 2022 года
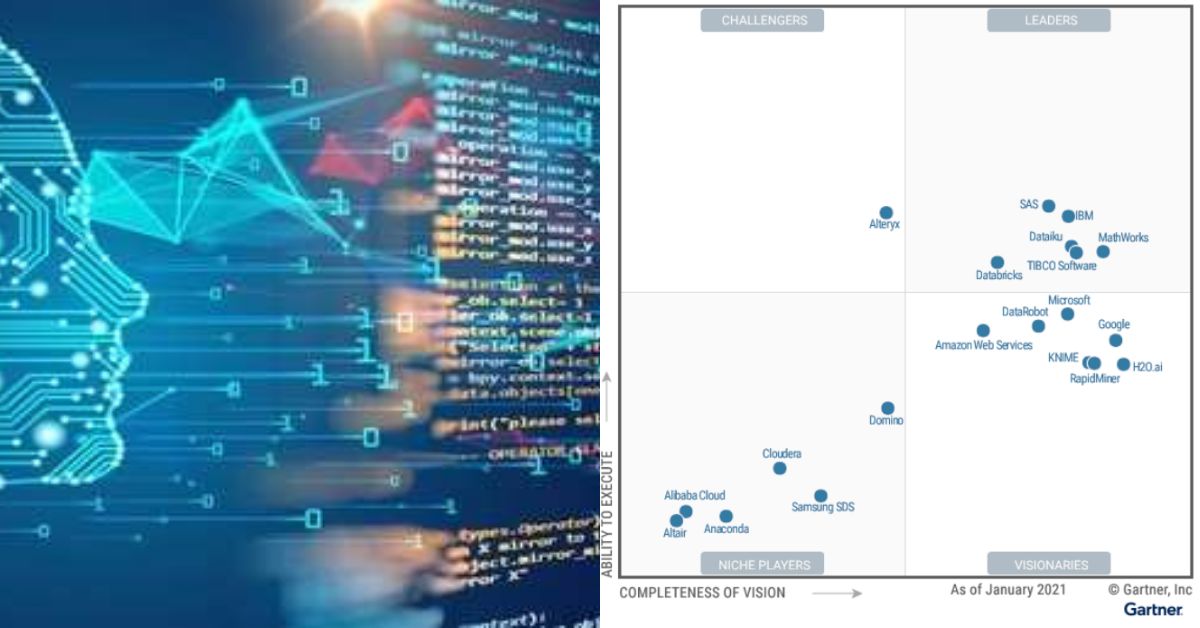 Изучение платформ обработки данных и машинного обучения (DSML)
Изучение платформ обработки данных и машинного обучения (DSML)
484. Коронавирус: семь способов сломать кривую прямо сейчас
 Все знают, что нужно действовать прямо сейчас, чтобы остановить коронавирус.
Все знают, что нужно действовать прямо сейчас, чтобы остановить коронавирус.
485. Как играть в шахматы, используя модель GPT-2
 Языковая модель GPT-2 на основе преобразователя OpenAI определенно оправдывает эту шумиху. После естественной эволюции искусственного интеллекта (ИИ) эта генеративная языковая модель привлекла большое внимание, участвуя в интервью и появляясь в текстовой онлайн-приключенческой игре AI Dungeon.
Языковая модель GPT-2 на основе преобразователя OpenAI определенно оправдывает эту шумиху. После естественной эволюции искусственного интеллекта (ИИ) эта генеративная языковая модель привлекла большое внимание, участвуя в интервью и появляясь в текстовой онлайн-приключенческой игре AI Dungeon.
486. Сегментация изображений: советы и рекомендации по результатам 39 соревнований Kaggle
 Представьте себе, если бы вы могли получить все советы и рекомендации, необходимые для участия в соревнованиях Kaggle. Я принял участие в более чем 39 соревнованиях Kaggle, включая
Представьте себе, если бы вы могли получить все советы и рекомендации, необходимые для участия в соревнованиях Kaggle. Я принял участие в более чем 39 соревнованиях Kaggle, включая
487. Наука о данных как карьера: 12 шагов от новичка к профессионалу
 12 шагов для тех, кто хочет построить карьеру в Data Science с нуля. Ниже есть инструкция к действию и россыпь ссылок на полезные ресурсы.
12 шагов для тех, кто хочет построить карьеру в Data Science с нуля. Ниже есть инструкция к действию и россыпь ссылок на полезные ресурсы.
488. Демократизация ИИ: насколько это может быть сложно?

489. Прогнозирование кредитного риска с помощью нейронных сетей
 Пошаговое руководство (с хорошей дозой очистки данных)
Пошаговое руководство (с хорошей дозой очистки данных)
490. Почему я влюблен в Юлю
 В этой статье я собираюсь обосновать, почему люди, серьезно относящиеся к созданию алгоритмов машинного обучения и высокопроизводительному программированию обработки данных, должны использовать Julia, а не Python.
В этой статье я собираюсь обосновать, почему люди, серьезно относящиеся к созданию алгоритмов машинного обучения и высокопроизводительному программированию обработки данных, должны использовать Julia, а не Python.
491. Парсинг с помощью Selenium 101: большая дыра в наборе инструментов для специалистов по данным [Часть 1]
 Веб-скрапинг, который обычно забывают во всех курсах и курсах по науке о данных, по моему честному мнению, является базовым инструментом в наборе инструментов Data Scientist, равно как и инструментом для получения и, следовательно, использования внешних данных из вашей организации, когда общедоступные базы данных недоступны.
Веб-скрапинг, который обычно забывают во всех курсах и курсах по науке о данных, по моему честному мнению, является базовым инструментом в наборе инструментов Data Scientist, равно как и инструментом для получения и, следовательно, использования внешних данных из вашей организации, когда общедоступные базы данных недоступны.
492. 4 совета, как стать успешным аналитиком данных начального уровня
 Компании во всех отраслях полагаются на большие данные при принятии стратегических решений в отношении своего бизнеса, поэтому должности аналитиков данных постоянно востребованы.
Компании во всех отраслях полагаются на большие данные при принятии стратегических решений в отношении своего бизнеса, поэтому должности аналитиков данных постоянно востребованы.
493. Собирайте и сравнивайте продукты электронной коммерции с помощью прокси-скребка
 В этом посте мы собираемся изучить парсинг веб-страниц с помощью Python. Используя Python, мы собираемся очистить веб-сайты, такие как Walmart, eBay и Amazon, чтобы узнать цену черной консоли Microsoft Xbox One X 1 ТБ. Используя этот парсер, вы сможете узнать цены на любой продукт с этих веб-сайтов. Как вы знаете, мне нравится все упрощать, поэтому я также буду использовать парсинг веб-страниц, который повысит эффективность парсинга.
В этом посте мы собираемся изучить парсинг веб-страниц с помощью Python. Используя Python, мы собираемся очистить веб-сайты, такие как Walmart, eBay и Amazon, чтобы узнать цену черной консоли Microsoft Xbox One X 1 ТБ. Используя этот парсер, вы сможете узнать цены на любой продукт с этих веб-сайтов. Как вы знаете, мне нравится все упрощать, поэтому я также буду использовать парсинг веб-страниц, который повысит эффективность парсинга.
494. Как искусственный интеллект может спасти индустрию 3D-печати и будущее машин
 3D-печать – это рынок стоимостью в миллиарды долларов, который можно использовать в самых разных сферах: от здравоохранения, реплик до архитектуры и деталей самолетов.
3D-печать – это рынок стоимостью в миллиарды долларов, который можно использовать в самых разных сферах: от здравоохранения, реплик до архитектуры и деталей самолетов.
495. Использование данных для прогнозирования спроса на велопрокат в Лондоне без кода
 2019 год – странное время для транспорта. Люди катаются на странных самокатах и заказывают поездки с помощью мобильных телефонов. Нью-Йорк и Лондон начали облагать налогом автомобили, въезжающие в центр города, чтобы сократить количество водителей. Появились альтернативы транспорта, такие как Zipcar, Lime, Bird, а также значительно возросло количество различных электронных велосипедов или велосипедов, доказывая, что пришло время подготовить свой арендный парк.
2019 год – странное время для транспорта. Люди катаются на странных самокатах и заказывают поездки с помощью мобильных телефонов. Нью-Йорк и Лондон начали облагать налогом автомобили, въезжающие в центр города, чтобы сократить количество водителей. Появились альтернативы транспорта, такие как Zipcar, Lime, Bird, а также значительно возросло количество различных электронных велосипедов или велосипедов, доказывая, что пришло время подготовить свой арендный парк.
496. 21 лучший курс и сертификат Coursera для ИТ-специалистов по изучению науки о данных и облачных технологиях
 Вот 20 лучших курсов и сертификатов Coursera для изучения науки о данных, облачных вычислений и Python.
Вот 20 лучших курсов и сертификатов Coursera для изучения науки о данных, облачных вычислений и Python.
497. 7 типов искажения данных в машинном обучении
 Смещение данных в машинном обучении — это тип ошибки, при которой определенные элементы набора данных имеют больший вес и/или представлены, чем другие. Предвзятый набор данных неточно отражает вариант использования модели, что приводит к искаженным результатам, низкому уровню точности и аналитическим ошибкам.
Смещение данных в машинном обучении — это тип ошибки, при которой определенные элементы набора данных имеют больший вес и/или представлены, чем другие. Предвзятый набор данных неточно отражает вариант использования модели, что приводит к искаженным результатам, низкому уровню точности и аналитическим ошибкам.
498. Четыре новых метода машинного обучения для анализа наборов данных блокчейна
 Использование машинного обучения для анализа наборов данных блокчейна — увлекательная задача. Помимо невероятного потенциала раскрытия неизвестной информации, которая помогает нам понять поведение криптоактивов, наборы данных блокчейна представляют собой уникальные проблемы для специалиста по машинному обучению. Многие из этих проблем становятся серьезными препятствиями для большинства традиционных методов машинного обучения. Однако быстрое развитие технологий машинного интеллекта позволило создать новые методы машинного обучения, которые очень применимы для анализа наборов данных блокчейна. В IntoTheBlock мы регулярно экспериментируем с этими новыми методами, чтобы повысить эффективность наших сигналов анализа рынка. Сегодня я хотел бы представить краткий обзор некоторых новых идей в области машинного обучения, которые могут дать интересные результаты при анализе данных блокчейна.
Использование машинного обучения для анализа наборов данных блокчейна — увлекательная задача. Помимо невероятного потенциала раскрытия неизвестной информации, которая помогает нам понять поведение криптоактивов, наборы данных блокчейна представляют собой уникальные проблемы для специалиста по машинному обучению. Многие из этих проблем становятся серьезными препятствиями для большинства традиционных методов машинного обучения. Однако быстрое развитие технологий машинного интеллекта позволило создать новые методы машинного обучения, которые очень применимы для анализа наборов данных блокчейна. В IntoTheBlock мы регулярно экспериментируем с этими новыми методами, чтобы повысить эффективность наших сигналов анализа рынка. Сегодня я хотел бы представить краткий обзор некоторых новых идей в области машинного обучения, которые могут дать интересные результаты при анализе данных блокчейна.
499. Построение конвейера цепей Маркова Монте-Карло с использованием Luigi
 Несколько месяцев назад меня приняли в учебный лагерь по науке о данных — Springboard, на их карьерный курс в области науки о данных. В рамках этого учебного курса мне пришлось работать над проектами Capstone, которые помогли бы построить мое портфолио, продемонстрировать мою способность извлекать, очищать данные, строить модели и извлекать информацию из этих моделей. Для своего первого проекта я изначально решил построить конвейер Марковской цепи Монте-Карло с целью создания модели мультитач-атрибуции, которая помогла бы мне понять коэффициенты конверсии на разных этапах процесса регистрации и использовать это, чтобы понять, какие каналы оказались результативными. наибольшие коэффициенты конверсии для пользователей, проходящих через данную целевую страницу и проходящих через различные состояния регистрации, определенные в моем наборе данных.
Несколько месяцев назад меня приняли в учебный лагерь по науке о данных — Springboard, на их карьерный курс в области науки о данных. В рамках этого учебного курса мне пришлось работать над проектами Capstone, которые помогли бы построить мое портфолио, продемонстрировать мою способность извлекать, очищать данные, строить модели и извлекать информацию из этих моделей. Для своего первого проекта я изначально решил построить конвейер Марковской цепи Монте-Карло с целью создания модели мультитач-атрибуции, которая помогла бы мне понять коэффициенты конверсии на разных этапах процесса регистрации и использовать это, чтобы понять, какие каналы оказались результативными. наибольшие коэффициенты конверсии для пользователей, проходящих через данную целевую страницу и проходящих через различные состояния регистрации, определенные в моем наборе данных.
500. 10 лучших библиотек обработки данных на Python
 Библиотеки обработки данных, которые будут блистать в этом году.
Библиотеки обработки данных, которые будут блистать в этом году.
501. Семантические поисковые запросы возвращают более точные результаты

502. 10 библиотек обработки данных и машинного обучения для Python

503. 3 распределения данных для подсчетов с точки зрения непрофессионала
 Подсчеты есть повсюду, поэтому независимо от вашего опыта, эти распределения данных пригодятся.
Подсчеты есть повсюду, поэтому независимо от вашего опыта, эти распределения данных пригодятся.
504. PULSE: повышение разрешения фотографий делает размытые лица в 60 раз резче
 Новый алгоритм PULSE: Photo Upsampling преобразует размытое изображение в изображение с высоким разрешением.
Новый алгоритм PULSE: Photo Upsampling преобразует размытое изображение в изображение с высоким разрешением.
505. Что такое Weaviate и как создавать в нем схемы данных

506. Используйте правило 80/20 с умеренностью

507. Как начать работу с контролем версий данных (DVC)
 Контроль версий данных (DVC) — это версия Git, ориентированная на данные. Фактически, он почти такой же, как Git, с точки зрения связанных с ним функций и рабочих процессов.
Контроль версий данных (DVC) — это версия Git, ориентированная на данные. Фактически, он почти такой же, как Git, с точки зрения связанных с ним функций и рабочих процессов.
508. 10 лучших ИТ-сертификаций по запросу с самой высокой оплатой: издание 2020 г.
 Сертификация информационных технологий (ИТ) может обогатить вашу карьеру в сфере ИТ и открыть путь к прибыльному пути. Поскольку спрос на ИТ-специалистов растет, давайте рассмотрим 10 высокооплачиваемых сертификатов. Технологический ландшафт постоянно меняется, и спрос на сертификацию информационных технологий также растет. Популярные области ИТ включают сети, облачные вычисления, управление проектами и безопасность. Восемьдесят процентов ИТ-специалистов считают, что сертификация полезна для карьеры, и их задача состоит в том, чтобы определить области интересов. Давайте посмотрим на наиболее необходимые сертификаты и соответствующие им зарплаты.
Сертификация информационных технологий (ИТ) может обогатить вашу карьеру в сфере ИТ и открыть путь к прибыльному пути. Поскольку спрос на ИТ-специалистов растет, давайте рассмотрим 10 высокооплачиваемых сертификатов. Технологический ландшафт постоянно меняется, и спрос на сертификацию информационных технологий также растет. Популярные области ИТ включают сети, облачные вычисления, управление проектами и безопасность. Восемьдесят процентов ИТ-специалистов считают, что сертификация полезна для карьеры, и их задача состоит в том, чтобы определить области интересов. Давайте посмотрим на наиболее необходимые сертификаты и соответствующие им зарплаты.
509. Парсинг веб-страниц с помощью Python

510. Как реализовать 3D-систему оценки позы человека в фитнес-приложениях с искусственным интеллектом
 «Может ли технологическое решение заменить фитнес-тренеров? Что ж, кто-то все равно должен мотивировать вас, говоря: «Да ладно, даже моя бабушка может добиться большего!» Но с технологической точки зрения это требование высокого уровня привело нас к технологии трехмерной оценки позы человека.
«Может ли технологическое решение заменить фитнес-тренеров? Что ж, кто-то все равно должен мотивировать вас, говоря: «Да ладно, даже моя бабушка может добиться большего!» Но с технологической точки зрения это требование высокого уровня привело нас к технологии трехмерной оценки позы человека.
511. Анализ данных о дорожно-транспортных происшествиях в США с помощью визуализации данных
 В этой статье мы будем анализировать данные о дорожно-транспортных происшествиях в США, которые можно использовать для изучения мест, подверженных авариям, и влияющих на них факторов.
В этой статье мы будем анализировать данные о дорожно-транспортных происшествиях в США, которые можно использовать для изучения мест, подверженных авариям, и влияющих на них факторов.
512. Как я проанализировал записи миллиона избирателей на Манхэттене
 Что, если бы вы могли мгновенно визуализировать политическую принадлежность всего города, вплоть до каждой квартиры и человека, зарегистрированного для голосования? Несколько удивительно, что город Нью-Йорк воплотил это в жизнь в начале 2019 года, когда Избирательная комиссия Нью-Йорка решила опубликовать в Интернете 4,6 миллиона записей избирателей, как сообщает New York Times. Эти записи включали полное имя, домашний адрес, политическую принадлежность и информацию о том, регистрировались ли вы за последние 2 года. Причиной согласно этой статье было:
Что, если бы вы могли мгновенно визуализировать политическую принадлежность всего города, вплоть до каждой квартиры и человека, зарегистрированного для голосования? Несколько удивительно, что город Нью-Йорк воплотил это в жизнь в начале 2019 года, когда Избирательная комиссия Нью-Йорка решила опубликовать в Интернете 4,6 миллиона записей избирателей, как сообщает New York Times. Эти записи включали полное имя, домашний адрес, политическую принадлежность и информацию о том, регистрировались ли вы за последние 2 года. Причиной согласно этой статье было:
513. Как кошельки BitMEX влияют на цену биткойнов
 Частью построения прибыльной торговой стратегии является быстрое тестирование новых идей. Они, как правило, приносят прибыль в том редком случае, когда они окажутся полезными, как только вы сможете интегрировать их в свою стратегию.
Частью построения прибыльной торговой стратегии является быстрое тестирование новых идей. Они, как правило, приносят прибыль в том редком случае, когда они окажутся полезными, как только вы сможете интегрировать их в свою стратегию.
514. Анализ настроений в Твиттере перед выборами в Лок Сабха 2019 года
 Введение
Введение
515. 6 лучших практик CI/CD для сквозных конвейеров разработки
 Чтобы добиться максимальной эффективности, нужно знать, как головоломки науки о данных сочетаются друг с другом, и затем решать их.
Чтобы добиться максимальной эффективности, нужно знать, как головоломки науки о данных сочетаются друг с другом, и затем решать их.
516. 5 статей о распознавании лиц, которые должен прочитать каждый специалист по данным
 Распознавание лиц — одна из крупнейших областей исследований в области компьютерного зрения. В этой статье будут представлены 5 статей по распознаванию лиц для специалистов по данным.
Распознавание лиц — одна из крупнейших областей исследований в области компьютерного зрения. В этой статье будут представлены 5 статей по распознаванию лиц для специалистов по данным.
517. Основы программирования: алгоритмы сортировки
 Следующее задание в вашем календаре, рейтинговая позиция вашей любимой спортивной команды в лиге, список контактов в вашем мобильном телефоне — все это имеет порядок. Порядок имеет значение, когда мы обрабатываем информацию. Мы используем порядок, чтобы придать смысл нашей жизни и оптимизировать наши решения. Представьте себе, что вы ищете слово в словаре со смешанным алфавитным порядком или пытаетесь найти самый дешевый товар в неупорядоченном прайс-листе. Мы заказываем вещи, чтобы принимать более обоснованные решения (что на самом деле является иллюзией), и это делает нас более уверенными в результатах.
Следующее задание в вашем календаре, рейтинговая позиция вашей любимой спортивной команды в лиге, список контактов в вашем мобильном телефоне — все это имеет порядок. Порядок имеет значение, когда мы обрабатываем информацию. Мы используем порядок, чтобы придать смысл нашей жизни и оптимизировать наши решения. Представьте себе, что вы ищете слово в словаре со смешанным алфавитным порядком или пытаетесь найти самый дешевый товар в неупорядоченном прайс-листе. Мы заказываем вещи, чтобы принимать более обоснованные решения (что на самом деле является иллюзией), и это делает нас более уверенными в результатах.
518. Терапия как услуга, секс и другие способы преодоления трудностей на дому

519. Как стать специалистом по данным: навыки и навыки; Курсы по изучению науки о данных
 Необходимые навыки для создания профиля специалиста по данным — это бизнес-аналитика, статистические знания, технические навыки, структура данных и т. д.
Необходимые навыки для создания профиля специалиста по данным — это бизнес-аналитика, статистические знания, технические навыки, структура данных и т. д.
520. Графовые алгоритмы, нейронные сети и графовые базы данных
 Информационный бюллетень «Год графика», сентябрь 2019 г.
Информационный бюллетень «Год графика», сентябрь 2019 г.
521. Полное руководство по стратегическому мышлению для специалистов по данным
 Хотя компания HBR назвала профессию специалиста по данным самой привлекательной профессией 21 века, давайте признаем, что преобладает мнение, что это вызывающая и высокотехнологичная область.
Хотя компания HBR назвала профессию специалиста по данным самой привлекательной профессией 21 века, давайте признаем, что преобладает мнение, что это вызывающая и высокотехнологичная область.
522. Основное руководство по увеличению данных в НЛП
 В НЛП существует множество задач, от классификации текста до ответов на вопросы, но что бы вы ни делали, объем данных, необходимый для обучения модели, сильно влияет на ее производительность.
В НЛП существует множество задач, от классификации текста до ответов на вопросы, но что бы вы ни делали, объем данных, необходимый для обучения модели, сильно влияет на ее производительность.
523. Искусственный интеллект и машинное обучение в обрабатывающей промышленности: примеры использования
 Искусственный интеллект (ИИ) уже доказал свою способность решать некоторые сложные проблемы в широком спектре отраслей, таких как автомобилестроение, образование, здравоохранение, электронная коммерция, сельское хозяйство и т. д., а также обеспечивать более высокую производительность, интеллектуальные решения, улучшенную безопасность и уход, бизнес-аналитику. с помощью прогнозной, предписывающей и описательной аналитики. Так что же может сделать ИИ для обрабатывающей промышленности?
Искусственный интеллект (ИИ) уже доказал свою способность решать некоторые сложные проблемы в широком спектре отраслей, таких как автомобилестроение, образование, здравоохранение, электронная коммерция, сельское хозяйство и т. д., а также обеспечивать более высокую производительность, интеллектуальные решения, улучшенную безопасность и уход, бизнес-аналитику. с помощью прогнозной, предписывающей и описательной аналитики. Так что же может сделать ИИ для обрабатывающей промышленности?
524. Руководство для начинающих по включению табличных данных с помощью преобразователей HuggingFace
 Модели на основе преобразователей меняют правила игры, когда дело доходит до использования неструктурированных текстовых данных. По состоянию на сентябрь 2020 года наиболее эффективными моделями в тесте общей оценки понимания языка (GLUE) являются модели на основе преобразователя BERT. В грузинском языке мы часто сталкиваемся со сценариями, в которых у нас есть вспомогательная табличная информация о функциях и неструктурированные текстовые данные. Мы обнаружили, что, используя табличные данные в этих моделях, мы можем еще больше повысить производительность, поэтому решили создать набор инструментов, который поможет другим сделать то же самое.
Модели на основе преобразователей меняют правила игры, когда дело доходит до использования неструктурированных текстовых данных. По состоянию на сентябрь 2020 года наиболее эффективными моделями в тесте общей оценки понимания языка (GLUE) являются модели на основе преобразователя BERT. В грузинском языке мы часто сталкиваемся со сценариями, в которых у нас есть вспомогательная табличная информация о функциях и неструктурированные текстовые данные. Мы обнаружили, что, используя табличные данные в этих моделях, мы можем еще больше повысить производительность, поэтому решили создать набор инструментов, который поможет другим сделать то же самое.
525. Будущее маркетинга: как наука о данных прогнозирует поведение потребителей
 Постепенно, по мере наступления постпандемической фазы, маркетологам стала помогать маркетологам прогнозировать поведение потребителей.
Постепенно, по мере наступления постпандемической фазы, маркетологам стала помогать маркетологам прогнозировать поведение потребителей.
526. 25 лучших цитат из интервью ML Heroes (+ захватывающий анонс!)
 Перезагрузка «Интервью с героями машинного обучения» и сборник лучших советов
Перезагрузка «Интервью с героями машинного обучения» и сборник лучших советов
527. 10 лучших наборов данных на африканских языках для проектов по науке о данных
 Список наборов данных африканских языков со всего Интернета, которые можно использовать в многочисленных задачах НЛП.
Список наборов данных африканских языков со всего Интернета, которые можно использовать в многочисленных задачах НЛП.
528. Биткойн-мемпул: где транзакции стремительно развиваются
 Одна из сильных сторон Биткойна и то, что делает его уникальным в финансовом мире, — это его радикальная прозрачность. Данные блокчейна подобны окну: вы можете видеть сквозь него.
Одна из сильных сторон Биткойна и то, что делает его уникальным в финансовом мире, — это его радикальная прозрачность. Данные блокчейна подобны окну: вы можете видеть сквозь него.
529. Использование GAN для создания аниме-лиц с помощью Pytorch
 Большинство из нас, занимающихся наукой о данных, в последнее время видели много людей, созданных ИИ, будь то в статьях, блогах или видео. Мы достигли стадии, когда становится все труднее отличить настоящие человеческие лица от лиц, созданных искусственным интеллектом. Однако с учетом имеющихся в настоящее время инструментов машинного обучения создать эти изображения самостоятельно не так сложно, как вы думаете.
Большинство из нас, занимающихся наукой о данных, в последнее время видели много людей, созданных ИИ, будь то в статьях, блогах или видео. Мы достигли стадии, когда становится все труднее отличить настоящие человеческие лица от лиц, созданных искусственным интеллектом. Однако с учетом имеющихся в настоящее время инструментов машинного обучения создать эти изображения самостоятельно не так сложно, как вы думаете.
530. Методы и плагины для обнаружения дипфейков и текста, сгенерированного искусственным интеллектом
 С появлением невероятно мощных технологий машинного обучения, таких как Deepfakes и генеративные нейронные сети, распространять ложную информацию стало гораздо проще. В этой статье мы кратко представим дипфейки и генеративные нейронные сети, а также несколько способов обнаружить контент, созданный искусственным интеллектом, и защитить себя от дезинформации.
С появлением невероятно мощных технологий машинного обучения, таких как Deepfakes и генеративные нейронные сети, распространять ложную информацию стало гораздо проще. В этой статье мы кратко представим дипфейки и генеративные нейронные сети, а также несколько способов обнаружить контент, созданный искусственным интеллектом, и защитить себя от дезинформации.
531. 7 проблем в маркетинге Решения для машинного обучения
 Эта статья поможет нашим читателям выявить и понять проблемы, с которыми сталкиваются компании-разработчики искусственного интеллекта при продвижении на рынок искусственного интеллекта и технологий. Продукты машинного обучения.
Эта статья поможет нашим читателям выявить и понять проблемы, с которыми сталкиваются компании-разработчики искусственного интеллекта при продвижении на рынок искусственного интеллекта и технологий. Продукты машинного обучения.
532. 5 лучших статей об искусственном интеллекте за февраль 2022 г., которые должен прочитать каждый специалист по данным
 Вот пять лучших статей об искусственном интеллекте за февраль. Надеюсь, они вызовут у вас желание узнать больше и посетить их сайт.
Вот пять лучших статей об искусственном интеллекте за февраль. Надеюсь, они вызовут у вас желание узнать больше и посетить их сайт.
533. Как осмысленно интерпретировать данные о COVID-19
534. Этические библиотеки искусственного интеллекта, которые важно знать каждому специалисту по данным
 В условиях экспоненциального роста приложений искусственного интеллекта, науки о данных и машинного обучения это критически важные библиотеки этического искусственного интеллекта, которые следует знать.
В условиях экспоненциального роста приложений искусственного интеллекта, науки о данных и машинного обучения это критически важные библиотеки этического искусственного интеллекта, которые следует знать.
535. Реалистичная манипуляция лицами в видео с помощью искусственного интеллекта
 Вы наверняка видели такие фильмы, как недавний «Капитан Марвел» или «Человек-Близнецы», где Сэмюэл Л. Джексон и Уилл Смит выглядели намного моложе. Это требует сотен, если не тысяч часов работы профессионалов, вручную редактирующих сцены, в которых он появлялся. Вместо этого вы можете использовать простой ИИ и сделать это за несколько минут.
Вы наверняка видели такие фильмы, как недавний «Капитан Марвел» или «Человек-Близнецы», где Сэмюэл Л. Джексон и Уилл Смит выглядели намного моложе. Это требует сотен, если не тысяч часов работы профессионалов, вручную редактирующих сцены, в которых он появлялся. Вместо этого вы можете использовать простой ИИ и сделать это за несколько минут.
536. HDTree: настраиваемое и интерактивное дерево решений, написанное на Python
 Представляем настраиваемую и интерактивную структуру дерева решений, написанную на Python
Представляем настраиваемую и интерактивную структуру дерева решений, написанную на Python
537. Полное (почти) руководство по инструментам Python, которые можно использовать для анализа текстовых данных
 Исследовательский анализ данных — одна из наиболее важных частей любого рабочего процесса машинного обучения, и обработка естественного языка не является исключением.
Исследовательский анализ данных — одна из наиболее важных частей любого рабочего процесса машинного обучения, и обработка естественного языка не является исключением.
Спасибо, что ознакомились с 537 самыми читаемыми историями о науке о данных на HackerNoon.
Посетите репозиторий /Learn, чтобы найти самые читаемые статьи о любой технологии.
Оригинал