

5 Рабочие процессы агента AI для повторяемого успеха (включен код)
20 августа 2025 г.Привет!
Большинство людей используют агента искусственного интеллекта, бросая в них подсказки и надеясь на лучшее. Это работает для быстрых экспериментов, но терпит неудачу, когда вам нужны постоянные, готовые к производству результаты.
Причина проста: специальное подсказка не масштабируется. Он производит грязные выходы, непредсказуемое качество и потраченную впустую вычислитель.
Лучший путь: рабочие процессы структурированного агента
Наиболее эффективные команды не полагаются на единые подсказки. Они используют рабочие процессы, которые цепляются, направляют и совершают задачи, пока вывод не станет надежным. Вместо того, чтобы относиться к агенту, как черный ящик, они разбивают задачи на шаги, прямые входы в нужные модели и систематически проверяют выходы.
В этом руководстве я проведу вас через 5 ключевых рабочих процессов, которые вам нужно освоить. Каждый из них включает в себя пошаговые инструкции и примеры кода, чтобы вы могли следовать и применить их напрямую. Вы увидите не только то, что делает каждый рабочий процесс, но и как его реализовать, когда его использовать, и почему он дает лучшие результаты.
Давайте погрузимся!
Workflows 1: Prompt Chaining
Приглашение цепочки означает использование выхода одного вызова LLM в качестве входа в другой. Вместо того, чтобы сбрасывать сложную задачу в одну гигантскую подсказку, вы разбиваете ее на более мелкие шаги.
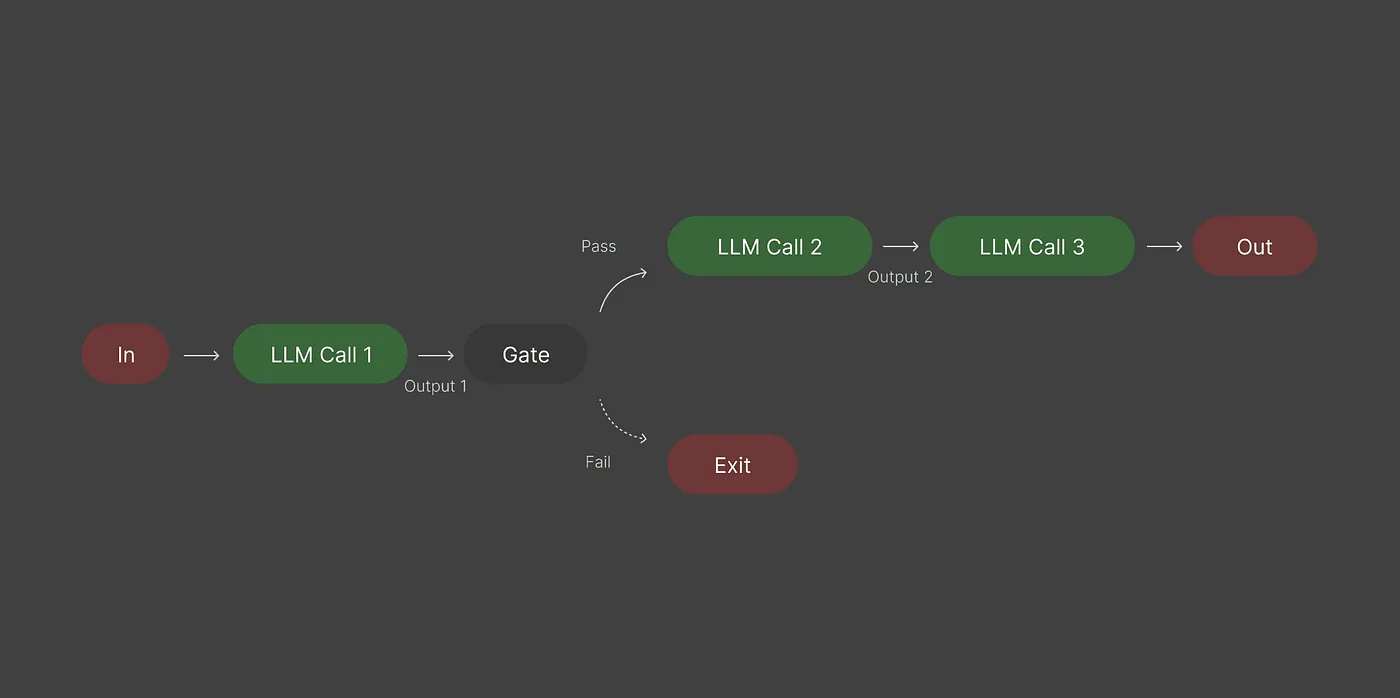
Идея проста: меньшие шаги уменьшают путаницу и ошибки. Цепочка направляет модель вместо того, чтобы оставлять ее, чтобы угадать.
Пропуск цепочки часто приводит к длинным, грязным выходам, непоследовательным тонам и большему количеству ошибок. Поцелевая, вы можете просмотреть каждый шаг, прежде чем двигаться дальше, что делает процесс более надежным.
Пример кода
from typing import List
from helpers import run_llm
def serial_chain_workflow(input_query: str, prompt_chain : List[str]) -> List[str]:
"""Run a serial chain of LLM calls to address the `input_query`
using a list of prompts specified in `prompt_chain`.
"""
response_chain = []
response = input_query
for i, prompt in enumerate(prompt_chain):
print(f"Step {i+1}")
response = run_llm(f"{prompt}\nInput:\n{response}", model='meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo')
response_chain.append(response)
print(f"{response}\n")
return response_chain
# Example
question = "Sally earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?"
prompt_chain = ["""Given the math problem, ONLY extract any relevant numerical information and how it can be used.""",
"""Given the numberical information extracted, ONLY express the steps you would take to solve the problem.""",
"""Given the steps, express the final answer to the problem."""]
responses = serial_chain_workflow(question, prompt_chain)
Рабочие процессы 2: маршрутизация
Маршрутизация решает, куда идет каждый вход.
Не каждый запрос заслуживает вашей самой большой, самой медленной или самой дорогой модели. Маршрутизация гарантирует, что простые задачи выполняются в легкие модели, в то время как сложные задачи достигают тяжеловеса.
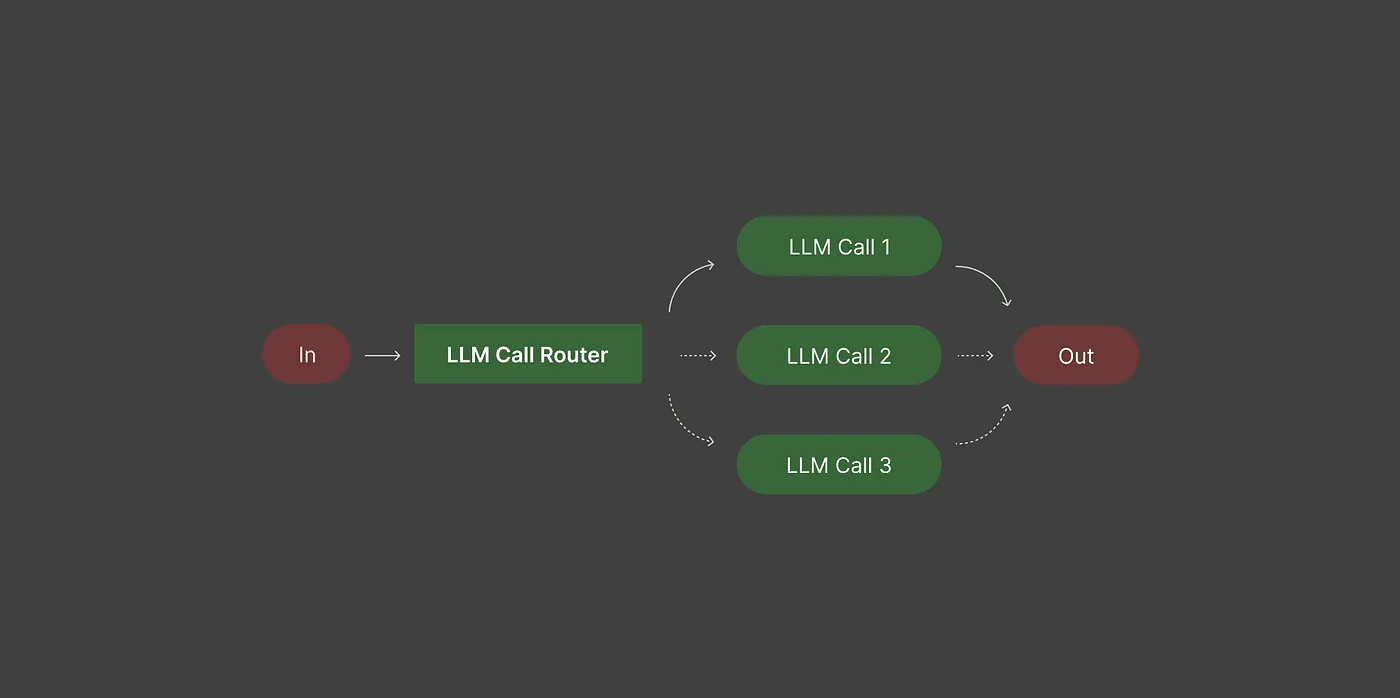
Без маршрутизации вы рискуете перерасходом на простые задачи или даете плохие результаты на тяжелые.
Для использования маршрутизации:
- Определите входные категории (простые, сложные, ограниченные).
- Назначьте каждую категорию правильной модели или рабочим процессам.
Цель - эффективность. Маршрутизация сокращает затраты, снижает задержку и улучшает качество, потому что правильный инструмент обрабатывает правильную работу.
Пример кода
from pydantic import BaseModel, Field
from typing import Literal, Dict
from helpers import run_llm, JSON_llm
def router_workflow(input_query: str, routes: Dict[str, str]) -> str:
"""Given a `input_query` and a dictionary of `routes` containing options and details for each.
Selects the best model for the task and return the response from the model.
"""
ROUTER_PROMPT = """Given a user prompt/query: {user_query}, select the best option out of the following routes:
{routes}. Answer only in JSON format."""
# Create a schema from the routes dictionary
class Schema(BaseModel):
route: Literal[tuple(routes.keys())]
reason: str = Field(
description="Short one-liner explanation why this route was selected for the task in the prompt/query."
)
# Call LLM to select route
selected_route = JSON_llm(
ROUTER_PROMPT.format(user_query=input_query, routes=routes), Schema
)
print(
f"Selected route:{selected_route['route']}\nReason: {selected_route['reason']}\n"
)
# Use LLM on selected route.
# Could also have different prompts that need to be used for each route.
response = run_llm(user_prompt=input_query, model=selected_route["route"])
print(f"Response: {response}\n")
return response
prompt_list = [
"Produce python snippet to check to see if a number is prime or not.",
"Plan and provide a short itenary for a 2 week vacation in Europe.",
"Write a short story about a dragon and a knight.",
]
model_routes = {
"Qwen/Qwen2.5-Coder-32B-Instruct": "Best model choice for code generation tasks.",
"Gryphe/MythoMax-L2-13b": "Best model choice for story-telling, role-playing and fantasy tasks.",
"Qwen/QwQ-32B-Preview": "Best model for reasoning, planning and multi-step tasks",
}
for i, prompt in enumerate(prompt_list):
print(f"Task {i+1}: {prompt}\n")
print(20 * "==")
router_workflow(prompt, model_routes)
Рабочие процессы 3: Параллелизация
Большинство людей выполняют LLMS по одной задаче за раз. Если задачи являются независимыми, вы можете запустить их параллельно и объединить результаты, экономить время и улучшение качества выпуска.
Параллелизация разбивает большую задачу на более мелкие, независимые части, которые работают одновременно. После того, как каждая часть сделана, вы объединяете результаты.
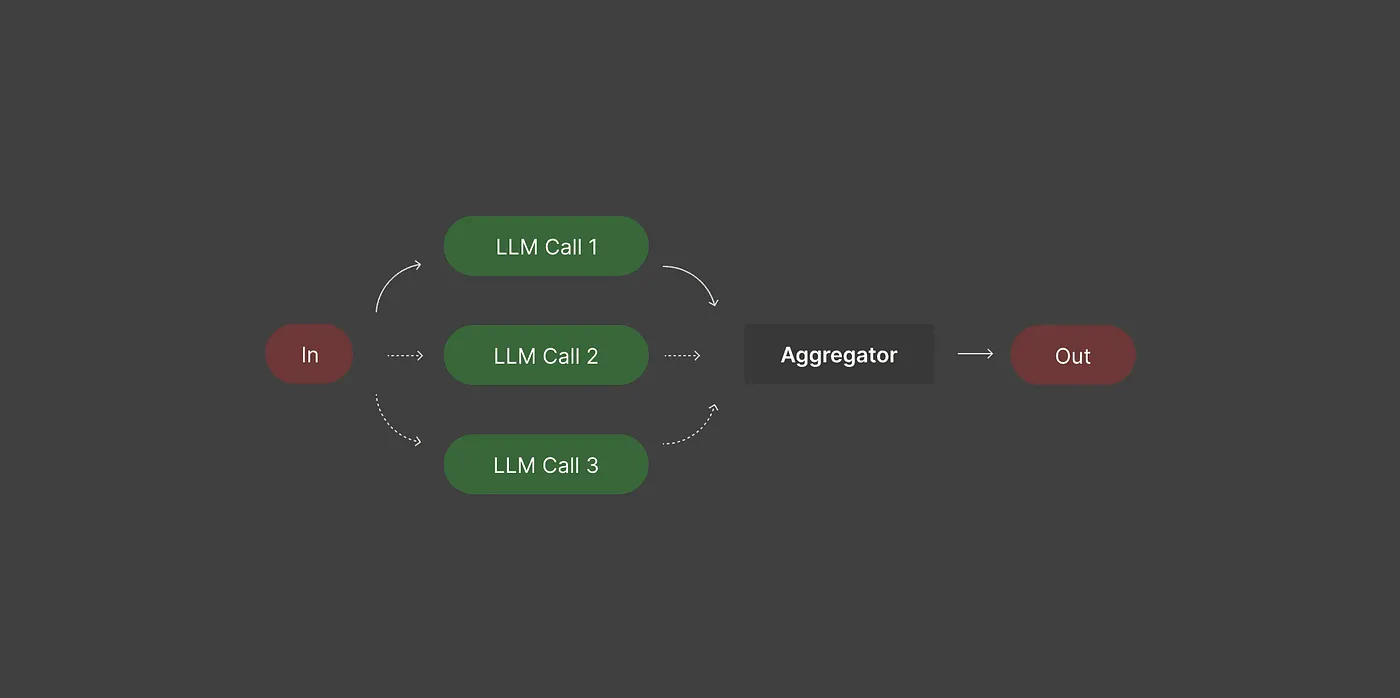
Примеры:
- Обзор кода: Одна модель проверяет безопасность, еще одну производительность, третью читаемость, а затем объединяет результаты для полного обзора.
- Анализ документов: Разделите длинный отчет на разделы, суммируйте каждый отдельно, затем объедините резюме.
- Текстовый анализ: Извлеките настроения, ключевые сущности и потенциальное смещение параллельно, затем объединяйтесь в окончательное резюме.
Параллелизация прохождения замедляет ситуацию и может перегружать одну модель, что приводит к грязным или непоследовательным выходам. Запуск задач параллельно позволяет каждой модели сосредоточиться на одном аспекте, делая окончательный результат более точным и проще в работе.
Пример кода
import asyncio
from typing import List
from helpers import run_llm, run_llm_parallel
async def parallel_workflow(prompt : str, proposer_models : List[str], aggregator_model : str, aggregator_prompt: str):
"""Run a parallel chain of LLM calls to address the `input_query`
using a list of models specified in `models`.
Returns output from final aggregator model.
"""
# Gather intermediate responses from proposer models
proposed_responses = await asyncio.gather(*[run_llm_parallel(prompt, model) for model in proposer_models])
# Aggregate responses using an aggregator model
final_output = run_llm(user_prompt=prompt,
model=aggregator_model,
system_prompt=aggregator_prompt + "\n" + "\n".join(f"{i+1}. {str(element)}" for i, element in enumerate(proposed_responses)
))
return final_output, proposed_responses
reference_models = [
"microsoft/WizardLM-2-8x22B",
"Qwen/Qwen2.5-72B-Instruct-Turbo",
"google/gemma-2-27b-it",
"meta-llama/Llama-3.3-70B-Instruct-Turbo",
]
user_prompt = """Jenna and her mother picked some apples from their apple farm.
Jenna picked half as many apples as her mom. If her mom got 20 apples, how many apples did they both pick?"""
aggregator_model = "deepseek-ai/DeepSeek-V3"
aggregator_system_prompt = """You have been provided with a set of responses from various open-source models to the latest user query.
Your task is to synthesize these responses into a single, high-quality response. It is crucial to critically evaluate the information
provided in these responses, recognizing that some of it may be biased or incorrect. Your response should not simply replicate the
given answers but should offer a refined, accurate, and comprehensive reply to the instruction. Ensure your response is well-structured,
coherent, and adheres to the highest standards of accuracy and reliability.
Responses from models:"""
async def main():
answer, intermediate_reponses = await parallel_workflow(prompt = user_prompt,
proposer_models = reference_models,
aggregator_model = aggregator_model,
aggregator_prompt = aggregator_system_prompt)
for i, response in enumerate(intermediate_reponses):
print(f"Intermetidate Response {i+1}:\n\n{response}\n")
print(f"Final Answer: {answer}\n")
Рабочие процессы 4: работники оркестраторов
В этом рабочем процессе используется модель оркестратора для планирования задачи и назначения конкретных подзадач рабочим моделям.
Оркестратор решает, что нужно сделать и в каком порядке, поэтому вам не нужно разрабатывать рабочий процесс вручную. Рабочие модели обрабатывают свои задачи, а оркестратор объединяет свои выходы в конечный результат.
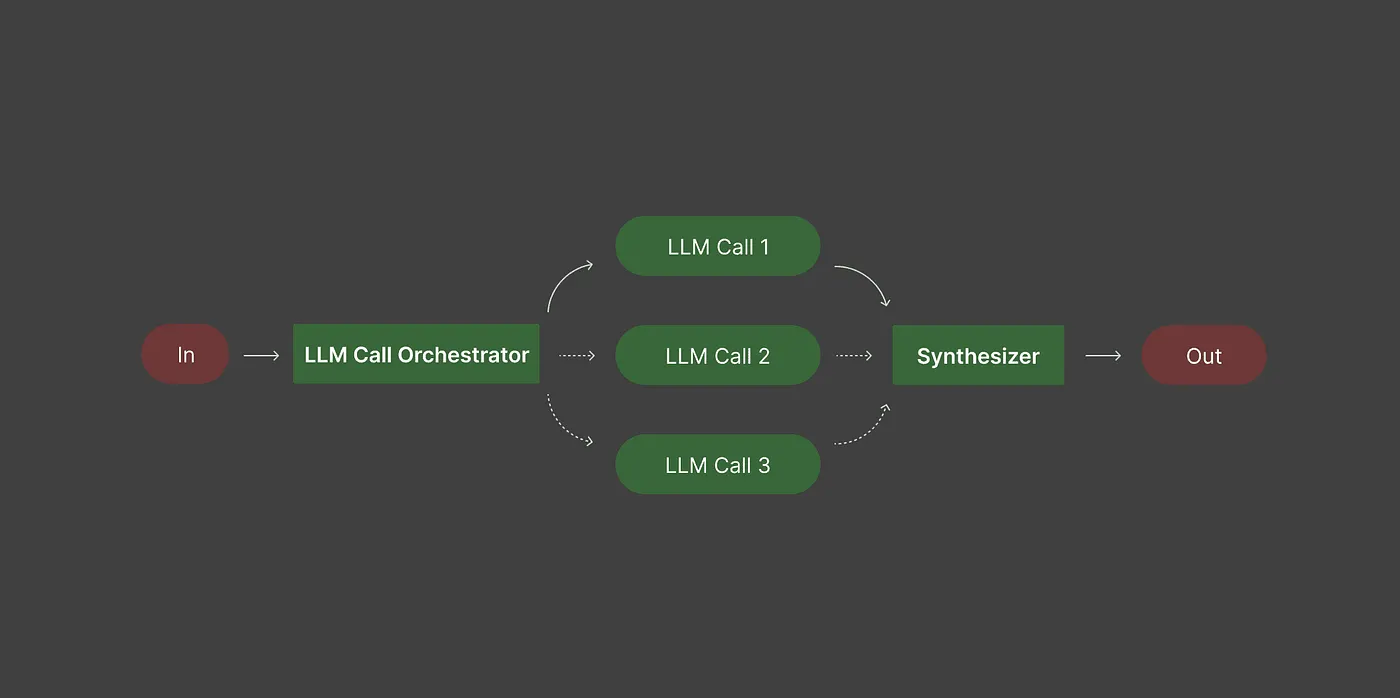
Примеры:
- Письмосодержание: Оркестратор разбивает сообщение в блоге на заголовок, очертания и разделы. Рабочие генерируют каждую часть, и оркестратор собирает полный пост.
- Кодирование: Оркестратор расщепляет программу на настройку, функции и тесты. Рабочие производят код для каждой части, и оркестратор объединяет их.
- Отчеты данных: Оркестратор определяет резюме, показатели и понимание. Рабочие генерируют контент для каждого, а оркестратор консолидирует отчет.
Этот рабочий процесс уменьшает ручное планирование и поддерживает организованные сложные задачи. Позволяя оркестру обрабатывать управление задачами, вы получаете последовательные, организованные результаты, в то время как каждый работник фокусируется на определенной работе.
Пример кода
import asyncio
import json
from pydantic import BaseModel, Field
from typing import Literal, List
from helpers import run_llm_parallel, JSON_llm
ORCHESTRATOR_PROMPT = """
Analyze this task and break it down into 2-3 distinct approaches:
Task: {task}
Provide an Analysis:
Explain your understanding of the task and which variations would be valuable.
Focus on how each approach serves different aspects of the task.
Along with the analysis, provide 2-3 approaches to tackle the task, each with a brief description:
Formal style: Write technically and precisely, focusing on detailed specifications
Conversational style: Write in a friendly and engaging way that connects with the reader
Hybrid style: Tell a story that includes technical details, combining emotional elements with specifications
Return only JSON output.
"""
WORKER_PROMPT = """
Generate content based on:
Task: {original_task}
Style: {task_type}
Guidelines: {task_description}
Return only your response:
[Your content here, maintaining the specified style and fully addressing requirements.]
"""
task = """Write a product description for a new eco-friendly water bottle.
The target_audience is environmentally conscious millennials and key product features are: plastic-free, insulated, lifetime warranty
"""
class Task(BaseModel):
type: Literal["formal", "conversational", "hybrid"]
description: str
class TaskList(BaseModel):
analysis: str
tasks: List[Task] = Field(..., default_factory=list)
async def orchestrator_workflow(task : str, orchestrator_prompt : str, worker_prompt : str):
"""Use a orchestrator model to break down a task into sub-tasks and then use worker models to generate and return responses."""
# Use orchestrator model to break the task up into sub-tasks
orchestrator_response = JSON_llm(orchestrator_prompt.format(task=task), schema=TaskList)
# Parse orchestrator response
analysis = orchestrator_response["analysis"]
tasks= orchestrator_response["tasks"]
print("\n=== ORCHESTRATOR OUTPUT ===")
print(f"\nANALYSIS:\n{analysis}")
print(f"\nTASKS:\n{json.dumps(tasks, indent=2)}")
worker_model = ["meta-llama/Llama-3.3-70B-Instruct-Turbo"]*len(tasks)
# Gather intermediate responses from worker models
return tasks , await asyncio.gather(*[run_llm_parallel(user_prompt=worker_prompt.format(original_task=task, task_type=task_info['type'], task_description=task_info['description']), model=model) for task_info, model in zip(tasks,worker_model)])
async def main():
task = """Write a product description for a new eco-friendly water bottle.
The target_audience is environmentally conscious millennials and key product features are: plastic-free, insulated, lifetime warranty
"""
tasks, worker_resp = await orchestrator_workflow(task, orchestrator_prompt=ORCHESTRATOR_PROMPT, worker_prompt=WORKER_PROMPT)
for task_info, response in zip(tasks, worker_resp):
print(f"\n=== WORKER RESULT ({task_info['type']}) ===\n{response}\n")
asyncio.run(main())
Рабочие процессы 5: Оценка-оптимизатор
Этот рабочий процесс фокусируется на улучшении качества выпуска путем введения петли обратной связи.
Одна модель генерирует содержание, а отдельная модель оценщика проверяет его на конкретных критериях. Если выход не соответствует стандартам, генератор пересматривает его, и оценщик снова проверяет. Этот процесс продолжается до тех пор, пока выход не пройдет.
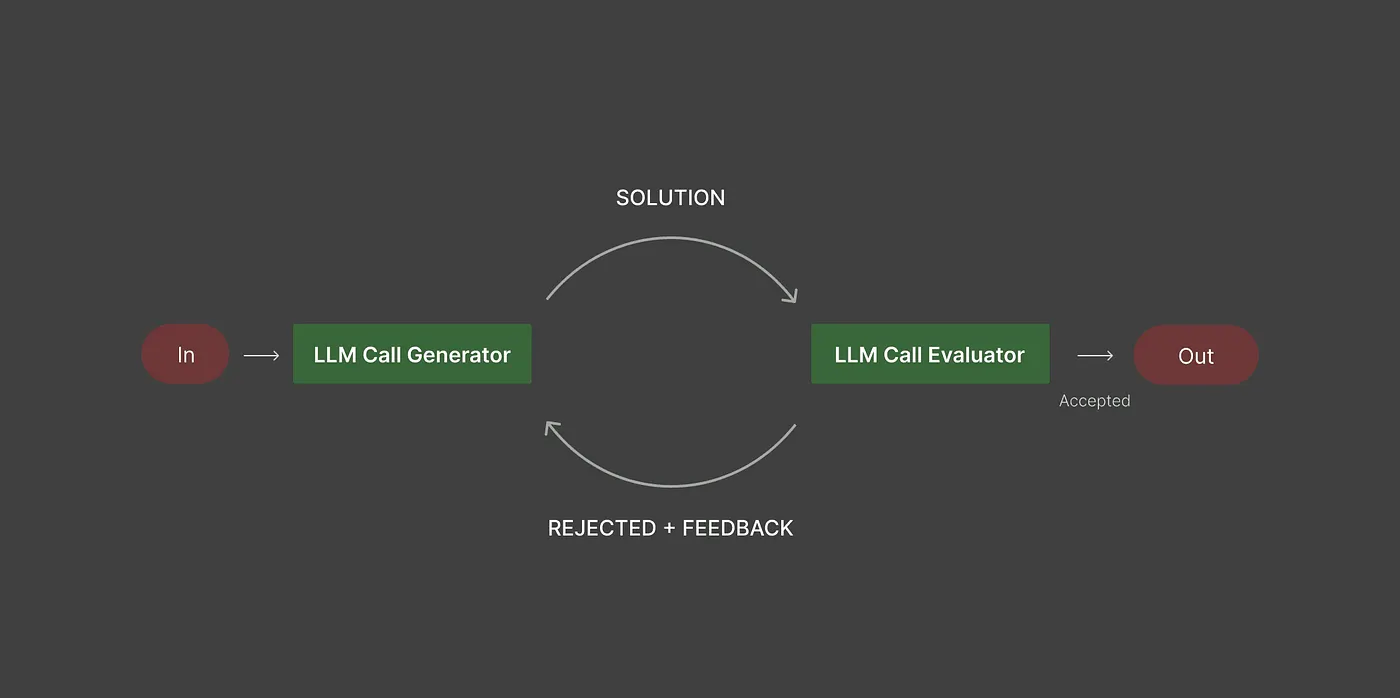
Примеры:
- Генерация кода: Генератор записывает код, оценщик проверяет правильность, эффективность и стиль, а генератор пересматривает до тех пор, пока код не удовлетворит требования.
- Маркетинговая копия: Генератор, копия, оценщик обеспечивает правильное количество слов, тона и ясности, а изменения применяются до утверждения.
- Сводка данных: Генератор дает отчет, оценщик проверяет полноту и точность, а генератор обновляет его по мере необходимости.
Без этого рабочего процесса выходы могут быть непоследовательными и требовать ручного обзора. Использование цикла оценщика-оптимизатора гарантирует, что результаты соответствуют стандартам и снижают повторные ручные исправления.
Пример кода
from pydantic import BaseModel
from typing import Literal
from helpers import run_llm, JSON_llm
task = """
Implement a Stack with:
1. push(x)
2. pop()
3. getMin()
All operations should be O(1).
"""
GENERATOR_PROMPT = """
Your goal is to complete the task based on <user input>. If there are feedback
from your previous generations, you should reflect on them to improve your solution
Output your answer concisely in the following format:
Thoughts:
[Your understanding of the task and feedback and how you plan to improve]
Response:
[Your code implementation here]
"""
def generate(task: str, generator_prompt: str, context: str = "") -> tuple[str, str]:
"""Generate and improve a solution based on feedback."""
full_prompt = f"{generator_prompt}\n{context}\nTask: {task}" if context else f"{generator_prompt}\nTask: {task}"
response = run_llm(full_prompt, model="Qwen/Qwen2.5-Coder-32B-Instruct")
print("\n## Generation start")
print(f"Output:\n{response}\n")
return response
EVALUATOR_PROMPT = """
Evaluate this following code implementation for:
1. code correctness
2. time complexity
3. style and best practices
You should be evaluating only and not attempting to solve the task.
Only output "PASS" if all criteria are met and you have no further suggestions for improvements.
Provide detailed feedback if there are areas that need improvement. You should specify what needs improvement and why.
Only output JSON.
"""
def evaluate(task : str, evaluator_prompt : str, generated_content: str, schema) -> tuple[str, str]:
"""Evaluate if a solution meets requirements."""
full_prompt = f"{evaluator_prompt}\nOriginal task: {task}\nContent to evaluate: {generated_content}"
#Build a schema for the evaluation
class Evaluation(BaseModel):
evaluation: Literal["PASS", "NEEDS_IMPROVEMENT", "FAIL"]
feedback: str
response = JSON_llm(full_prompt, Evaluation)
evaluation = response["evaluation"]
feedback = response["feedback"]
print("## Evaluation start")
print(f"Status: {evaluation}")
print(f"Feedback: {feedback}")
return evaluation, feedback
def loop_workflow(task: str, evaluator_prompt: str, generator_prompt: str) -> tuple[str, list[dict]]:
"""Keep generating and evaluating until the evaluator passes the last generated response."""
# Store previous responses from generator
memory = []
# Generate initial response
response = generate(task, generator_prompt)
memory.append(response)
# While the generated response is not passing, keep generating and evaluating
while True:
evaluation, feedback = evaluate(task, evaluator_prompt, response)
# Terminating condition
if evaluation == "PASS":
return response
# Add current response and feedback to context and generate a new response
context = "\n".join([
"Previous attempts:",
*[f"- {m}" for m in memory],
f"\nFeedback: {feedback}"
])
response = generate(task, generator_prompt, context)
memory.append(response)
loop_workflow(task, EVALUATOR_PROMPT, GENERATOR_PROMPT)
Сделать все это вместе
Структурированные рабочие процессы меняют способ работы с LLMS.
Вместо того, чтобы бросить подсказки в ИИ и надеяться на лучшее, вы разбиваете задачи на шаги, направляете их к правильным моделям, запускаете независимые подзадачи параллельными, организуйте сложные процессы и уточняете выходы с помощью петлей оценщика.
Каждый рабочий процесс служит целью, и объединение их позволяет выполнять задачи более эффективно и надежно. Вы можете начать с малого с одного рабочего процесса, освоить его и постепенно добавить других по мере необходимости.
Используя маршрутизацию, оркестровку, параллелизацию и петли-оптимизатор, вы переходите от грязного, непредсказуемого подсказки к результатам, которые являются последовательными, высококачественными и готовыми к производству. Со временем этот подход не только сэкономит время: он дает вам контроль, предсказуемость и уверенность в каждом результате, которые дают ваши модели, решая те самые проблемы, которые создает специальные подсказки.
Примените эти рабочие процессы, и вы будете разблокировать весь потенциал вашего ИИ, с уверенностью получая последовательные, высококачественные результаты.
Оригинал